【生物信息学】同源、相似性、相似性矩阵和点阵图| 学习课
摘要:• 氨基酸角度:公认使用定量相似性矩阵,根据多序列比对来看实际生物序列中各种变化的频率。• 同源性和相似性在生物学意义上有着千丝万缕的联系, 两序列有同源性表示两序列曾来自共同祖先, 如果演化时间不长,变化较少,那么两序列常常会表现出相似性。
导读
生物信息学是一门强大的新技术,是用来分析、存储、搜索海量生物医学数据的信息技术和计算技术。另一方面,生物信息学是一种研究生命科学问题的新方法、新思路,是一种从全基因组出发、从系统水平出发、基于数据整合,提出新假说、发现新规律的研究方法。
联川生物正在开展全员学习的生物信息学系列视频课程是由北京大学魏丽萍、高歌等教授主讲的“生物信息学:导论与方法课程”,几位教授通过14周的课程,系统地讲授生物信息学主要概念及方法,以及如何应用生物信息学手段解决生命科学问题。课程内容从基础的序列比对开始,循序渐进,围绕深度测序数据分析、计算基因组学、分子通路鉴定等当前研究的前沿热点内容进行介绍与讨论。
联川的小伙们想通过本次的全员学习,不断提升自己的知识水平。小编想来,这次学习的内容来自北大知名教授,关注我们的小伙伴们也能一起学习、进步,就将视频课程内容整理好分享给大家,与大家一起学习、一起进步,一起探讨生物信息学的相关知识。大家也可以在文末对照视频一起学习哦~
若有整理不当的地方,敬请大家留言交流呐~
同源、相似性、相似性矩阵和点阵图
• 同源性 Homology
•定义:在生物学意义上就是指多个 两个或多个东西具有共同的祖先,在基因序列的层次,特别是关于系统发育的研究中有时候还把同源分为直系同源和旁系同源。
• 直系同源 ortholog:指在不同物种中的两个序列 来自历史上的共同祖先和同一个序列, 是因为物种形成事件而可引申到两个或多个物种中;
• 旁系同源 paralog:指在同一个物种中的两个序列在历史上来自同一个序列, 是由于序列复制产生了多个拷贝,也可引申到多个物种中两个序列的关系。
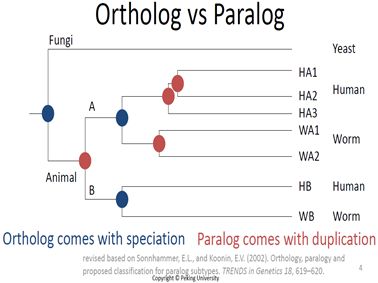
• 概念:直系同源来自物种形成事件,旁系同源来自于复制事件, 经物种内部基因组成复制。
•相似性与同一性
• 相似性 Similarity
• 定义:以氨基酸为例, 根据氨基酸的性质,例如酸碱性、疏水性,或者有没有苯烷 我们可以把氨基酸分成一些类别,同一个类别内的氨基酸可以认为是相似的。
• 同一性 Identity
• 定义:指A是A,G是G这样完全相同的关系。

• 同源性和相似性的联系
• 同源性和相似性在生物学意义上有着千丝万缕的联系, 两序列有同源性表示两序列曾来自共同祖先, 如果演化时间不长,变化较少,那么两序列常常会表现出相似性。反之,如果演化 时间很长,变化会越来越多,则两者的相似性可能就会越来越低,甚至无法分辨出来。由于同源性常常能带来相似性, 而我们容易测量得到序列,比较序列的相似性。所以我们常常想根据序列的相似性反推或暗示它们的同源性。
• 相似性矩阵 Similarity Matrix
• 氨基酸角度:一般用简单的单位矩阵,基于对角线大于零且都相等的矩阵作为其打分矩阵。不过在系统发育时的同构共轭工作中,大家常常会使用更复杂一些的碱基替换模型来更好地刻画碱基随演化改变的过程。包括我们一般认为嘧啶变为另一种嘧啶,嘌呤变成另一种嘌呤,会比嘧啶变为嘌呤或反过来变化更容易见到,即转换比替换更容易发生。
• 氨基酸角度:公认使用定量相似性矩阵,根据多序列比对来看实际生物序列中各种变化的频率。
• PAM (1978, Margaret Dayhoff)
• Two sequences are 1 PAM apart,if they differ in 1 % of the residues.
• 1 PAM = one step of evolution
• PAM30和PAM70:适用于序列更大比例差异的打分矩阵
• BLOSUM (1992, Steven Henikoff & Jorja Henikoff)
• computed by looking at "blocks" of conserved sequences found in multiple protein alignments
• BLOSUM 62:最常用的蛋白序列比对打分矩阵
• 矩阵自乘:指在转移概率意义上进行自乘
• 点阵图 Dot matrix
• 定义:把两个序列写到矩阵两边,然后标出对应残基相同的位置,可以产生一个0/1二则矩阵,如果两序列完全相同,那么对角线肯定都是1,如果有较长的子序列可以匹配,那么也可以看到远离对角线、平行于对角线的连线。如果有反向的匹配,则可按照反对角线方向的连线。如果两序列不全相同,有gap或miss,那么对角线就可能不再连续。
• 目的:寻找最优或较优的序列比对
• 与动态规划矩阵不同之处
• Dot Matrix只关心local的几位碱基构成的word是否完全匹配,而动态规划则关心前面已考察的子序列的最优匹配法及得分。
• word size:需要连续多少个残基每个都匹配才开始匹配,使配出的结果可能更有生物学意义。
课程内容就介绍完了,本系列课程均是整理自视频内容,大家也可以在文末对照视频一起学习哦~





