CatBoost、LightGBM、XGBoost,這些算法你都瞭解嗎?

圖源:pixabay
原文來源:towardsdatascience
作者:Alvira Swalin
「雷克世界」編譯:EVA
我最近參加了Kaggle競賽(WIDS Datathon),在那裏我通過使用各種各樣的Boosting算法而進入前10名。從那時起,我一直對每個模型精細的工作,包括參數調優、優缺點,都非常好奇,因此決定寫下這篇文章。儘管最近神經網絡重新出現並流行,我還是着重關注Boosting算法,因爲它們在訓練數據有限、訓練時間少、專業知識少的參數調優體系中仍然能夠發揮很大的作用。

XGBoost最初是由陳天奇於2014年3月發起的一個研究項目。2017年1月,微軟發佈了第一個穩定的LightGBM版本。2017年4月,俄羅斯的一個領先的科技公司—Yandex,發佈開源CatBoost
XGBoost(通常被稱爲GBM殺手)已經在機器學習領域裏盛行很長一段時間了,現在有很多專門闡述該技術的文章。因此,本文將更多地聚焦於CatBoost和LGBM。我們將要討論的話題涵蓋以下幾點:
•結構的差異
•每個算法對分類變量的處理
•參數的理解
•數據集的實現
•每個算法的性能
LightGBM和XGBoost的結構差異
LightGBM使用一種全新的基於梯度的單側採樣(GOSS)技術來過濾數據實例,以尋找分割值。而XGBoost則是使用預分類算法(presorted algorithm)和基於直方圖的算法來計算最佳分割。這裏,實例意味着觀察值/樣本。
首先,讓我們來了解一下預分類的分割是如何進行的:
•對於每個節點,列舉所有的特徵
•對於每個特徵,按特徵值對實例進行分類
•使用線性掃描根據該特徵基礎信息增益的程度確定最佳分割
•以最佳的分割解決方案來處理所有的特徵
簡單地說,基於直方圖的算法將一個特徵的所有數據點分割到離散的容器中,並使用這些容器來尋找直方圖的分割值。儘管它在訓練速度方面比預分類算法效率高,因爲預分類算法列舉了預分類特徵值所有可能的分割點的,但它在速度方面仍然落後於GOSS。
那麼,是什麼讓GOSS方法更高效呢?
在AdaBoost中,樣本權重可以作爲樣本重要性的一個很好的指標。然而,在梯度提升決策樹(GBDT)中沒有原始的樣本權重,因此針對AdaBoost的採樣方法不能直接應用到其中。這裏就需要基於梯度的採樣。
梯度代表了損失函數的切線斜率。所以從邏輯上說,如果數據點的梯度在某種意義上是很大的,那麼這些點對於找到最優的分割點來說是很重要的,因爲它們有更高的誤差。
GOSS保留所有具有大梯度的實例,並在具有小梯度的實例上執行隨機採樣。例如,假設我有50萬行數據,1萬行有更高的梯度。所以我的算法會選擇(更高梯度的1萬行+剩餘49萬行隨機選擇的x%)。假設x是10%,那麼在發現的分割值的基礎上,選擇的全部行數是50萬中的5萬9千。
這裏的基本假設是,具有小梯度訓練實例的樣本訓練誤差較小,並且已經訓練得很好。
爲了保持相同的數據分佈,當計算信息增益時,GOSS爲小梯度的數據實例引入了一個常數乘數。因此,GOSS在減少數據實例的數量和保持學習決策樹的精確性之間取得了良好的平衡。

高梯度/誤差的葉子在LGBM中進一步使用
每個模型如何處理分類變量?
· CatBoost
CatBoost具有提供分類列索引的靈活性,這樣就可以使用one_hot_max_size將其編碼爲獨熱編碼(對於所有具有小於或等於給定參數值的 特徵使用獨熱編碼進行編碼)。
如果你在cat_features引數中傳遞任何內容,那麼CatBoost將把所有的列都視爲數值變量。
注意:如果沒有在cat_features中提供具有字符串值的列,CatBoost會顯示錯誤。另外,默認整型的列會被默認當作數值處理,因此必須在cat_features中對它進行詳細說明以使算法將其視爲分類。

對於剩下的那些具有罕見的比one_hot_max_size更大的若干類別的分類列,CatBoost使用一種有效的編碼方法,它與平均數編碼相似,但減少了過度擬合。過程是這樣的:
1.對輸入的觀察值的集合進行隨機排列,生成多個隨機排列。
2.將標籤值從浮點或類別轉換爲整數
3. 使用如下公式將所有的分類特徵值轉換爲數值:

其中,CountInClass是指,對於那些具有當前分類特徵值的對象來說,其標籤值等於"1"的次數。
Prior是分子的初始值。它由起始參數決定。
TotalCount是對象的總數(直到當前的一個),它具有與當前的對象相匹配的分類特徵值。
從數學上講,這可以用以下公式來表示:

· LightGBM
與CatBoost類似,LightGBM還可以通過輸入特徵名稱來處理分類特徵。它不轉換爲獨熱編碼,而且比獨熱編碼快得多。LGBM使用一種特殊的算法來尋找分類特性的分割值。

注意:在爲LGBM構造數據集之前,你應該將你的分類特徵轉換爲整型。即使你通過categorical_feature傳遞參數,它也不接受字符串值。
· XGBoost
與CatBoost或LGBM不同,XGBoost不能獨自處理分類特徵,它只接受與隨機森林類似的數值。因此,在向XGBoost提供分類數據之前,必須執行各種編碼,比如標籤編碼、平均數編碼或獨熱編碼。
超參數的相似性
所有這些模型都有很多參數需要調優,但我們只討論重要的參數。下面是根據這些參數的功能和它們在不同模型中的對應而給出的的列表。
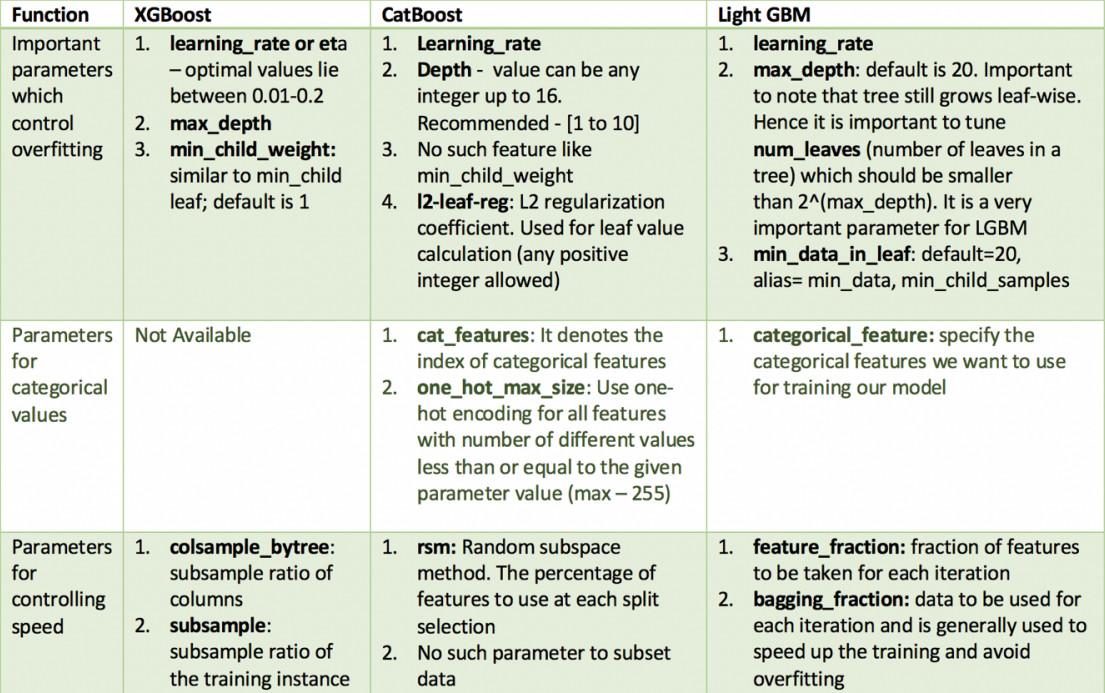
數據集的實現
我使用2015年的航班延誤數據集,因爲它具有分類特徵和數值特徵。它大約有500萬行,對於使用每種Boosting算法類型進行調優的模型,這個數據集都能夠很好地在速度和精確度兩個方面來判斷其性能。我將使用這個數據10%的子集——50萬行。
下面是用於建模的特徵:
MONTH, DAY, DAY_OF_WEEK: 整型數據
AIRLINE and FLIGHT_NUMBER: 整型數據
ORIGIN_AIRPORT and DESTINATION_AIRPORT: 字符型數據
DEPARTURE_TIME: 浮點型數據
ARRIVAL_DELAY: 這將是目標,並被轉換爲布爾變量,表明延遲超過10分鐘
DISTANCE and AIR_TIME: 浮點型數據

· XGBoost

· LightGBM

· CatBoost
在對CatBoost進行調參時,很難傳遞分類特徵的指數。因此,我在沒有傳遞分類特徵的情況下進行了調參,並對兩個模型進行了評估——一個有分類特徵而另一個沒有。我已經單獨調優了one_hot_max_size,因爲它不會影響其他參數。

結果

總結說明
對於模型的評價,我們應該從速度和精確度兩方面來考慮模型的性能。
記住這一點,CatBoost因在測試集中獲得最大精確度(0.816)、最小過度擬合(訓練和測試精度都很接近)和最小預測時間和調優時間,從而勝出。但這只是因爲我們考慮了分類變量並調優了one_hot_max_size。如果我們不利用CatBoost的這些特徵,那麼它就會是最差的,只有0.752的精確度。因此,我們瞭解到,只有當我們在數據中有明確的分類變量並對它們進行正確的調優時,CatBoost纔會表現得很好。
下一個是XGBoost,它整體運行良好。它的精確度非常接近於CatBoost,即使忽略這樣一個事實:我們在數據中存在分類變量,且出於消耗成本的考慮,已將其轉換爲數值。然而,XGBoost唯一的問題是它太慢了。調優參數令人非常沮喪(花了6個小時來運行GridSearchCV)更好的方法是分別對參數參數進行調優,而不是使用GridSearchCV。
最後是Light GBM。這裏需要注意的一點是,在使用cat_features時,它在速度和精確度方面都表現不佳。我認爲它之所以表現不佳是因爲它對分類數據使用了一種改良的平均值編碼,從而導致了過度擬合(訓練的精確度很高——0.999,比測試的準確度高)。但是,如果我們像XGBoost一樣使用它,它可以用更快的速度獲得與XGBoost(LGBM-0.785,XGBoost-0.789)類似的精確度(如果不是更高)。
最後,需要說明的是,這些觀察結果對於這個特定的數據集來說是正確的,但對其他數據集是否依然有效,要視具體情況而定。然而,有一點是可以肯定的,那就是XGBoost比其他兩種算法都要慢。
原文鏈接:https://towardsdatascience.com/catboost-vs-light-gbm-vs-xgboost-5f93620723db?source=userActivityShare-dc302bd40f88-1520991597&from=groupmessage










