Catboost:超越Lightgbm和XGBoost的又一個boost算法神器
摘要:性能:CatBoost提供最先進的結果,在性能方面與任何領先的機器學習算法相比都具有競爭力。自動處理分類特徵:CatBoost無需對數據特徵進行任何顯式的預處理就可以將類別轉換爲數字。
機器學習AI算法工程 公衆號:datayx
今天介紹一個超級簡單並且又極其實用的boosting算法包Catboost,據開發者所說這一boosting算法是超越Lightgbm和XGBoost的又一個神器。
論文鏈接
https://arxiv.org/pdf/1706.09516.pdf
它可以很容易地與谷歌的TensorFlow和蘋果的核心ML等深度學習框架集成。它可以處理各種數據類型,如音頻、文本、圖像(包括歷史數據)。幫助解決當今企業面臨的各種問題。最重要的是,它提供了強大的準確性。
它在兩方面特別強大:
它不需要其他機器學習方法通常需要的大量數據培訓,就能得到最先進的結果
爲伴隨許多業務問題而來的更具描述性的數據格式提供強大的支持
CatBoost名稱來源於“Category”和“boost”兩個單詞。其中“Boost”來源於梯度增強機器學習算法,因爲這個庫是基於梯度增強庫的。梯度增強是一種功能強大的機器學習算法,廣泛應用於欺詐檢測、推薦項、預測等多種類型的業務挑戰,具有良好的性能。它還可以以相對較少的數據返回非常好的結果,不像DL模型需要從大量數據中學習。
一、 CatBoost庫的優點
性能:CatBoost提供最先進的結果,在性能方面與任何領先的機器學習算法相比都具有競爭力。
自動處理分類特徵:CatBoost無需對數據特徵進行任何顯式的預處理就可以將類別轉換爲數字。CatBoost使用關於分類特徵組合以及分類和數字特徵組合的各種統計信息將分類值轉換爲數字。
魯棒性:它減少了對廣泛的超參數優化的需要,並降低了過擬合的機會,這也會導致更一般化的模型。CatBoost的參數包括樹的數量、學習率、正則化、樹的深度、摺疊尺寸、裝袋溫度等。
易於使用:您可以從命令行使用CatBoost爲Python和R用戶提供方便的API。
二、CatBoost與其他boost庫進行比較
我們有多個boost庫,如XGBoost、H2O和LightGBM,它們都能很好地解決各種問題。CatBoost在標準ML數據集上與競爭對手進行了性能對比:
上面的對比顯示了測試數據的log-loss值,在大多數情況下CatBoost的log-loss值是最低的。它清楚地表明,CatBoost在調優和默認模型上的性能都更好。除此之外,CatBoost不需要將數據集轉換爲任何特定格式。

Python安裝:
pip install catboost
四、使用CatBoost解決ML挑戰
CatBoost庫既可以解決分類問題,也可以解決迴歸問題。對於分類,您可以使用“CatBoostClassifier”和“CatBoostRegressor”進行迴歸。
在本文中,我將使用CatBoost解決“Big Mart Sales”實踐問題。這是一個迴歸的挑戰,所以我們將使用CatBoostRegressor。
完整代碼
案例一


案例二
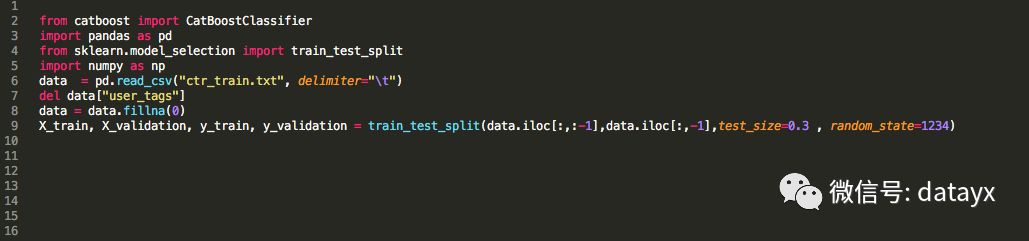
這裏我們可以觀察一下數據的特徵列,這裏有很多列特徵比如廣告的寬高,是否可以下載,是否會跳轉等一些特徵,而且特徵的數據類型各不一樣,有數值型(creative_height),布爾型(creative_is_js)等不同類型的特徵。

下圖我們對所有特徵做了一個統計,發現整個訓練數據集一共有34列,除去標籤列,整個數據集一共有33個特徵,其中6個爲布爾型特徵,2個爲浮點型特徵,18個整型特徵,還有8個對象型特徵。

如果按照正常的算法,此時應該將非數值型特徵通過各種數據預處理手段,各種編碼方式轉化爲數值型特徵。而在catboost中你根本不用費心幹這些,你只需要告訴算法,哪些特徵屬於類別特徵,它會自動幫你處理。代碼如下所示:

最後就是將數據餵給算法,訓練走起來。

將plot = ture 打開後,catboot包還提供了非常炫酷的訓練可視化功能,從下圖可以看到我的Logloss正在不停的下降。

訓練結束後,通過model.feature_importances_屬性,我們可以拿到這些特徵的重要程度數據,特徵的重要性程度可以幫助我們分析出一些有用的信息。

執行上方代碼,我們可以拿到特徵重要程度的可視化結構,從下圖我們發現campaign_id是用戶是否點擊這個廣告的最關鍵的影響因子。

至此整個catboot的優點和使用方法都介紹完了,是不是覺得十分簡單易用,而且功能強大。深度學習,神經網絡減弱了我們對特徵工程的依賴,catboost也在朝着這方面努力。所以有時候碰到需要特別多的前期數據處理和特徵數值化的任務時,可以嘗試用一下catboost