H200,英伟达终于肯加内存了?
H200,英伟达终于肯加内存了?
来源:华尔街见闻 赵颖
现在囤货没有性价比,下一代B100 GPU更香?
人工智能浪潮席卷全球,AI服务器需求井喷,同时也带火了拥有超高带宽的HBM芯片。
周二,英伟达官网官宣史上最强的AI芯片H200,其基于Hopper架构,配备英伟达H200 Tensor Core GPU,可以为生成式AI和高性能计算工作负载处理海量数据。
其中值得一提的是,H200是全球首款配备HBM3e内存的GPU,拥有高达141GB的显存。据SK海力士介绍,HBM3e芯片拥有更快的速度,容量也更大,在速度、发热控制和客户使用便利性等所有方面都达到了全球最高水平。
一直以来,由于高成本等制约因素,企业往往选择提高处理器的计算能力性能,而忽略了内存带宽性能。随着AI服务器对高性能内存带宽提出更高要求,HBM(高带宽内存)成了“香饽饽”。
H200最大升级:HBM3e
相比于前一代H100,H200在哪些方面进行了升级?
H100相比,H200 的性能提升主要体现在推理性能表现上。在处理 Llama 2 等大语言模型时,H200 的推理速度比 H100 提高了接近 2 倍。
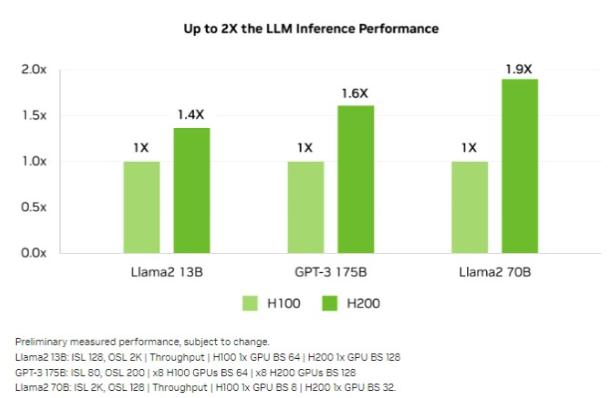
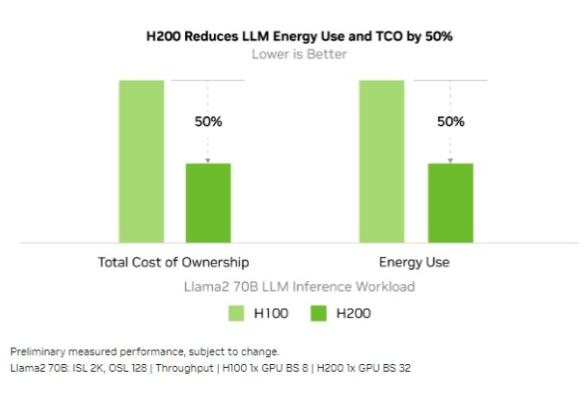
相同的功率范围之内实现 2 倍的性能提升,意味着实际能耗和总体成本降低了50%。
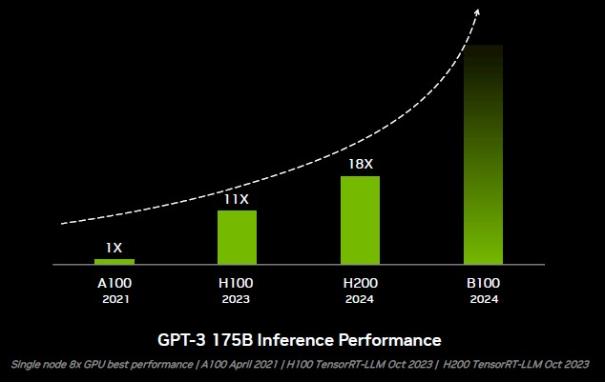
得益于 Tansformer 引擎、浮点运算精度的下降以及更快的 HBM3内存 ,H100 在 GPT-3 175B 模型的推理性能方面已经较 A100 提升至 11 倍。而凭借更大、更快的 HBM3e 内存,无需任何硬件或代码变更的 H200 则直接把性能提高至 18 倍。
从 H100 到 H200,性能提高了 1.64 倍,这一切都归功于内存容量和带宽的增长。
H100 具有 80 GB 和 96 GB 的 HBM3 内存,在初始设备中分别提供 3.35 TB/秒和 3.9 TB/秒的带宽,而 H200 具有 141 GB 更快的 HBM3e 内存,带宽为 4.8总带宽 TB/秒。
其他方面,据媒体分析,H200 迄今为止仅适用于 SXM5 插槽,并且在矢量和矩阵数学方面具有与 Hopper H100 加速器完全相同的峰值性能统计数据。
什么是HBM?
出于一系列技术和经济因素的考量,存储性能的提升速度往往跟不上处理器,过去20年硬件的峰值计算能力增加了90000倍,但是内存/硬件互连带宽却只是提高了30倍。
而当存储的性能跟不上处理器,读写指令和数据的时间将是处理器运算所消耗时间的几十倍乃至几百倍。想象一下,数据传输就像处在一个巨大的漏斗之中,不管处理器灌进去多少,存储器都只能“细水长流”。
为了减少能耗和延迟,将很多个普通DDR芯片堆叠在一起后和GPU封装在一起,就得到了所谓的HBM(高带宽内存)。HBM通过增加带宽,扩展内存容量,让更大的模型,更多的参数留在离核心计算更近的地方,从而减少内存和存储解决方案带来的延迟。
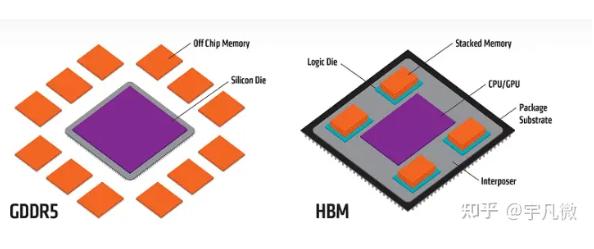
不过,这也意味着更高的成本,在没有考虑封测成本的情况下,HBM的成本是GDDR的三倍左右。HBM发展制约因素正是高成本,一些高级计算引擎上的HBM内存成本往往比芯片本身还要高,因此添加更多内存自然面临很大的阻力。
媒体进一步分析指出,如果添加内存就能让性能翻倍,那同样的 HPC 或 AI 应用性能将只需要一半的设备即可达成,这样的主意显然没法在董事会那边得到支持。这种主动压缩利润的思路,恐怕只能在市场供过于求,三、四家厂商争夺客户预算的时候才会发生。
接下来到了拼内存突破的阶段?
然而,随着AI的爆火,对带宽的要求更高,HBM需求激增。市场规模上,有分析预计预计2023年全球HBM需求量将增近六成,达到2.9亿GB,2024年将再增长30%,2025年HBM整体市场有望达到20亿美元以上。SK海力士已表示,2024年的HBM3订单已经排满,而同样的情况现在也出现在三星身上。
同时分析指出,无论英伟达接下来的 Blackwell B100 GPU 加速器具体表现如何,都基本可以断定会带来更强大的推理性能,而且这种性能提升很可能来自内存方面的突破、而非计算层面的升级。因此,从现在到明年夏季之间砸钱购买英伟达 Hopper G200没有什么性价比可言,但快速发展也是数据中心硬件技术的常态。
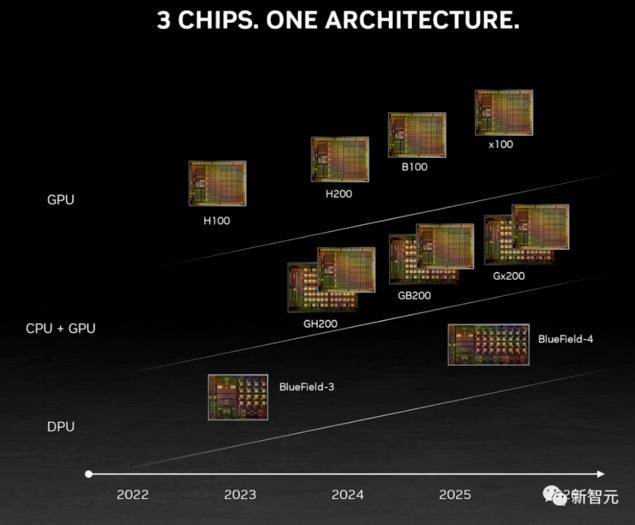
此外,英伟达的竞争对手——AMD也将在12月6日推出面向数据中心的“Antares”GPU加速器家族,包括带有192 GB HBM3内存的Instinct MI300X和带有128 GB HBM3内存的CPU-GPU混合MI300A。
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。






