科技|想要更進一步,AI 需要向嬰兒學習“人類本能”
前言
深度學習讓人工智能在個別應用上取得了飛躍。但是目前靠海量數據+機器學習的AI解決方案存在哪些限制?爲什麼稍微改變一下環境現有的AI系統就無法適應了呢?有一個派別的專家相信,這是因爲AI缺乏常識。如果給AI注入人類的一些基本本能,也許做出通用人工智能(AGI)就不是遙不可及。不過開發AI系統究竟需要多少先天知識呢? AGI應該遊走在純粹學習與純粹直覺之間的什麼位置?《科學》雜誌的一篇文章對此進行了分析。

嬰兒天生就具備了一些本能,正是這些本能幫助我們學習常識,而AI迄今爲止仍搞不懂常識這個東西。
機器學習的研究人員認爲,經過海量數據訓練的計算機可以學習任何事情——包括常識——而且需要很少的編程規則(如果說不可能不需要的話)。Marcus說,“在我看來,這些專家存在盲點。這是一個社會學上的東西,是物理妒忌的一種形式,大家都以爲越簡單越好。”他說計算機科學家忽視了一點:認知科學和發展心理學數十年的工作表明,人類是具備先天能力的——在出生或者童年早期就具備了編程好的本能——從而幫助我們進行靈活的抽象的思考,就像Chole那樣。他認爲AI研究人員應該把那樣的本能植入到程序裏面。
但許多計算機科學家正沉浸在機器學習的成功之中,他們渴望探索一個幼稚的AI能做的事情的極限是什麼。俄勒岡州立大學計算機科學家Thomas Dietterich說:“我認爲大多數搞機器學習的人對於納入大量背景知識都有着方法論的偏見,因爲從某種程度上來說我們視之爲一種失敗。”他補充說,此外,計算機科學家還非常欣賞簡潔性,討厭調試複雜代碼。MIT心理學家Josh Tenenbaum 說,Facebook和Google這樣的大公司是將AI朝那個方向推進的另一個因素。那些公司最感興趣的是狹義定義的近期問題,比如web搜索和人臉識別,這些問題白紙一張的AI系統可以用海量數據加以訓練並且解決得出奇的好。
但從更長期來看,計算機科學家預計AI要承接棘手得多的任務,而那些任務需要的是靈活性和常識。他們想創建可解釋新聞的聊天機器人,能應付混亂的城市交通的無人車,會照料老人的機器人。Tenenbaum說:“如果我們想開發像C-3PO那樣可以在完全人類的世界裏互動的機器人,就得用通用得多的設置去解決所有這些問題。”
探索的目的之一是想發現嬰兒知道什麼以及什麼時候知道的——然後再把這些經驗用到機器身上。艾倫人工智能研究所(AI2)的CEO Oren Etzioni說,但這需要時間。AI2最近宣佈要投入1.25億美元用於開發和測試AI的常識。Etzioni說:“我們願意開發人類大腦天生的表徵結構,但我們不會理解大腦是如何處理語言、推理以及知識的。”
Tenenbaum說,到頭來“我們是在嘗試着將AI的最古老夢想之一變成現實:也就是開發能夠像人一樣發展出智能的機器——像嬰兒一樣開始,像小孩一樣學習。”
過去幾年,AI已經展示出它可以翻譯語音、診斷癌症,並且在撲克遊戲中擊敗人類。但每一場勝利背後都會有一個大錯。圖像識別算法現在認狗的能力比你還強,但有時候卻會錯誤地把吉娃娃認成藍莓鬆糕。AI玩《太空入侵者》等經典Atari視頻遊戲有着超人的技藝,但當你把外星人全拿掉只留下一個時,AI卻令人費解地不知道該怎麼玩了。

2017年,AlphaGo擊敗了圍棋世界冠軍柯潔,這是機器學習的一項勝利。
Google DeepMind的Alpha程序把深度學習推上了神壇的位置。每次去掉規則,軟件似乎都得到改善。2016年,AlphaGo擊敗了一位圍棋的世界冠軍。次年,AlphaGo Zero在得到的指導少得多的情況下輕易擊敗了AlphaGo。數月之後,一個更加簡單的系統AlphaZero又擊敗了AlphaGo Zero——而且還掌握了國際象棋。1997年,一個經典的、基於規則的AI——IBM的深藍已經擊敗了國際象棋世界冠軍卡斯帕羅夫。不過事實表明,真正精通國際象棋的訣竅是知道例外的例外的例外——那是最好通過經驗收集到的信息。AlphaZero靠着自己跟自己下棋就能打敗目前最好的國際象棋程序深藍以及每一位人類世界冠軍。
但類似Alpha這樣的系統顯然不是在吸取能導致常識的經驗。如果是在21 x 21而不是標準的19 x 19棋盤上下圍棋的話,AI就得重新學習這種遊戲。1990年代末,Marcus訓練了一個網絡接收輸入數字然後再吐出來——這應該是能想象到的最簡單的任務了。但是他只是用偶數來對網絡進行訓練。在用奇數進行測試時,網絡不知所措了。它沒法像Chole那樣開始側向造樂高時將一個領域學到的東西應用到另一個領域。
哈佛大學心理學家Elizabeth Spelke認爲,我們至少有4種“核心知識”系統賦予了我們理解對象、動作、數字以及空間的先發優勢。比方說,我們是具有直覺的物理學家,能夠迅速理解對象及其交互。根據一項研究,僅3天大的嬰兒就能把部分隱藏的一根棍子的兩頭視爲一個實體的一部分——這是我們的大腦也許有感知連貫的對象的傾向。我們還是具有直覺的心理學家。在2017年《科學》雜誌的一項研究中,Spelke實驗室的研究生Shari Liu發現,10個月大的嬰兒就能推斷出當一個動畫角色爬上更高的山抵達一種形狀而不是另一種時,該角色必定會選擇前者(編者注:也就是說嬰兒知道付出越多回報越大這個常識邏輯)。Marcus已經表明了7個月大的嬰兒能學習規則;他們在聽到3個單詞組成的句子(“wo fe fe”)打破了之前聽到的句子(“ga ti ga”)的語法模式時會表現出驚訝。據後來的一項研究,出生才一天的嬰兒也顯示出了類似的行爲。
Marcus已經構建出10項他認爲應該植入到AI之中的人類本能最簡清單,其中包括了因果概念,成本效益分析,類型與實例(狗與我的狗)等。去年10月,他直面紐約大學計算機科學家,Facebook的首席AI科學家Yann LeCun,在紐約大學的一場有關AI是否需要“更直覺的機制”的辯論中爲他的清單辯護。爲了證明自己對直覺的主張,Marcus展示了一張野山羊嬰兒在懸崖峭壁下山的幻燈片。他說:“它們沒有時間去試錯學習100萬次。如果它們犯了錯,那將是致命的。”
不過Marcus指出,LeCun本人已經將這10項關鍵本能中的一種嵌入到了他的圖像識別算法裏面:平移不變性,不管出現在視野的任何地方都能識別對象的能力。平移不變性是卷積神經網絡(convnets)背後的原則,這是LeCun最出名的成就。過去5年卷積神經網絡已經成爲圖像識別等AI應用的核心,開啓了目前這波深度學習的狂熱。
經過一番裝飾之後,悉尼新南威爾士大學的機器人實驗室看起來就像一個客廳跟廚房。計算機科學家Michael Thielscher解釋說,這個實驗室是一個家用機器人的試驗檯。他的團隊正在嘗試賦予一個有手有臉(屏幕)的豐田人類支持機器人(HSR)兩種類似人類的直覺。首先,他們希望對HSR進行編程,把挑戰分解爲更小更容易的問題,就像一個人會將食譜解析成若干步驟一樣。其次,他們希望賦予機器人推理信念和目標,也就是人類對他人思想進行直覺思考的能力。如果一個人讓它取一個紅色的杯子,但它只能找到一個藍色杯子和一個紅色碟子時,HSR會如何響應呢?
到目前爲止,他們的軟件展示出了一些類似人類的能力,包括取藍色杯子而不是紅色碟子的好感覺(編者注:形狀而不是顏色對目標更重要)。但是編進系統的規則數量超過了Thielscher的設想。他的團隊被迫告訴AI通常杯子要比紅色更重要。理想情況下,機器人應該具備社會本能迅速自行了解到人們的喜好。
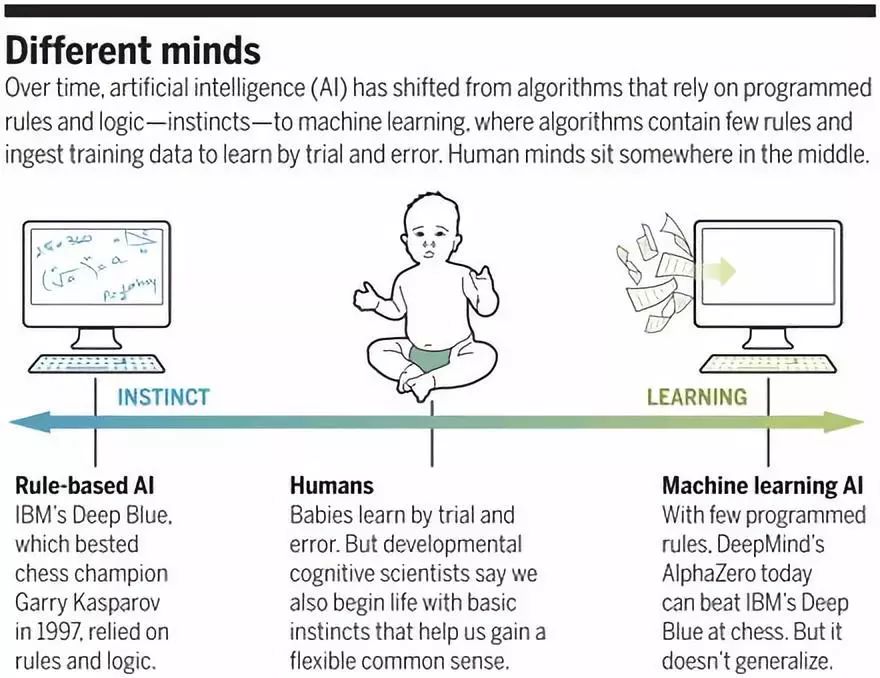
不同的思想:1)直覺——以IBM深藍爲代表的基於規則的AI;2)人類;3)學習——機器學習AI
機器人軟件公司Vicarious的模式網絡把這個想法又推進了一步。那些系統也假設對象和交互的存在,但系統還推斷連接它們的因果關係。通過不斷學習,該公司的軟件可以像人一樣從想要的結果倒推出計劃來。(我想讓我的鼻子不癢;撓一下可能行。)研究人員將它們的方法用Atari的遊戲《打磚塊》跟最先進的神經網絡進行比較。由於這種模式網絡能夠學習因果關係——比如球無論速度如何在接觸到的時候都能敲掉磚塊——所以在遊戲改動時並不需要額外的訓練。你可以移動目標磚塊,讓玩家改成同時玩3個球,模式網絡仍然能玩得很溜。其他網絡就失敗了。
除了我們的天生能力以外,人類還受益於一個大多數AI都沒有的東西:身體。爲了幫助軟件對世界進行推理,Vicarious對它進行了“具體化”從而使得軟件能夠探索虛擬的環境,就像嬰兒推倒一堆積木塊也許能瞭解到重力的一些東西了。今年2月,Vicarious展示了一個在二維場景下尋找有界區域的系統,方法是用一個微小的虛擬角色穿越區域。在探索過程中,系統瞭解到了包含的概念,從而幫助它比標準的圖像識別卷積神經網絡更快地弄清楚了新場景。概念——運用到很多情況下的知識——是常識的關鍵。Vicarious 聯合創始人Dileep George說:“在機器人學裏面,機器人能夠對新情況作出推理極其重要。”今年晚些時候,這家公司將在倉庫和工廠對其軟件進行試點,在打包和運送之前幫助機器人把東西撿起來、組裝然後上色。
最具挑戰性的任務之一是靈活地對直覺進行編碼,這樣AI才能應對一個未必遵守規則的混沌世界。比方說無人車沒有辦法指望其他司機會遵守交通規則。爲了應對這些不可預測性,斯坦福大學的心理學家兼計算機科學家Noah Goodman參與開發了概率編程語言(PPL)。他說這是一門把嚴格的計算機代碼結構與數學概率相結合的語言,正好呼應了人既遵循邏輯又允許不確定性的風格:如果草是溼的則有可能在下雨——但也可能是因爲有人灑水了。關鍵是,PPL可以跟深度學習網絡結合來體現博學。在Uber工作的時候,Goodman等人發明了這樣一種“深度PPL”,名字叫做Pyro。這家共享乘車公司正在探索Pyro的應用,比如派遣司機以及在遇到施工及比賽日時的適應性路線規劃等問題。Goodman說PPL能推理的不僅是物理和物流,也包括如何跟人交流,應對棘手的表達形式,比如誇張、諷刺、挖苦等。
對此Marcus顯然感到很自豪,原因不僅是因爲他的子女的能力,也是因爲他們支持了他關於我們如何瞭解世界的理論——以及AI應該如何學習的理論。玩完樂高積木之後,Chole和Alexander飛奔着撲向了父親的懷抱。當他抱着他們轉圈時,他們高興得尖叫起來,這又給了他們一次調整自己對物理的直覺,以及享受樂趣的機會。
☞來源:搜狐科技
意向合作,文章轉載, 均可聯繫堂博士









