谷歌失敗案例賞析:那些年在微服務上踩的坑

歡迎關注“創事記”微信訂閱號:sinachuangshiji
文/Ben Sigelman 譯/禚嫺靜
來源: InfoQ(ID:infoqchina)
Ben Sigelman 是 LightStep 的首席執行官兼聯合創始人,他是 Dapper 的共同創始人(Google 的分佈式跟蹤工具,幫助開發人員理解他們的大型分佈式系統),以及開源 OpenTracing API 標準的共同創建者( 一個 CNCF 內的項目)。在 2018 年 12 月 QCon 大會上 Ben 向我們分享了谷歌在微服務構建路上遇到的經驗教訓,本文是 Ben 的演講主要內容的譯稿。
大家好,今天和在座的各位分享一些失敗的經驗教訓。聊一聊這一類的話題要比那些成功案例更有意思。行業在進步,我們可以從過去的錯誤中吸取經驗,並主動在未來的計劃中避免,這一點很令人鼓舞。
背景信息
在開始之前,先介紹一下我在谷歌的經歷。2003 年大學畢業後我直接加入了谷歌,在這之前我是一個音樂營地的營地顧問,營地顧問之前我在一家冰激凌店工作。我還記得在谷歌的第一天,第一個項目的技術負責人是 Andrew Fights,他現在是類似谷歌傑出的工程師的角色,我記得當時告訴他,我得去找人聊一聊因爲實在不知道我在做什麼,今天想起來還是很有趣的事情。在谷歌裏我像海綿一樣快速的吸收技術和其他的信息。今天我在這裏談論的一些事情其實要早於我在谷歌的時間,大約 2000 年和 2001 年左右。讓我們從微服務,即谷歌的微服務版本開始講起。
當時,谷歌的業務仍然押注在 GSA(谷歌搜索服務器)產品,其實最終 GSA 也並沒有像想象中的那麼順利。當然了,其它事情也是這樣,畢竟不能將一個虛擬的壟斷產品與像廣告這樣數十億美元的鉅額業務相對比。不過,谷歌最開始是以搜索起家的,並專注在解決這一類的技術問題。

接下來要討論的很多內容的原始驅動力來自於這張幻燈片。在經濟危機之前,很多企業都將他們的基礎設施構建在 Sun Microsystems 的硬件之上,並將 Solaris 作爲操作系統。如果不考慮成本的話,這一套解決方案比現有的其它東西都要好,很多人買了很多這種 Sun box 也是基於這樣的原因。但 Sun box 真的很貴,尤其是一個擁有龐大數據中心的企業,整個數據中心需要填滿這種機箱以支撐業務的發展,成本就會影響到其業務渠道和活下去的底線。
谷歌當時就處在這樣一個狀況。當時的人會很自然的說:“Linux 雖然不夠完美,不過功能也夠用,它的硬件又很便宜,所以平衡下來我們可以選擇 Linux 作爲替代”。一定程度上,我也認同這些過往的事情是真實的,當時的人們成本意識很強,所以他們會不遺餘力的去解決一系列 RAM、芯片等 Linux 出現的一切故障,以降低成本。而這就帶來了一個結果 - 即 Linux 真的不可靠,特別是使用垃圾站硬件的時候,且問題很嚴重。我認爲,谷歌從 Compaq DEC 併購中受益匪淺,這也是導致 90 年代一些真正令人難以置信的研究實驗室死亡的原因。許多人比如 Jeff Dean 和 Sanjay Kumar 都來自那個世界,他們現在幾乎都是質量工程師。當時的他們對如何在那些難以令人置信的不可靠硬件之上構建軟件這個問題產生了強大的興趣,後面發生的事情也是很多接下來要分享的內容。

大家都知道,這個問題在 2001 年是沒有人解決過的問題,也是他們當下所處的情況。“讓我們寫一些很酷的軟件,看看 Github 上有什麼”。

然而在 2001 年並沒有什麼可以替代的方案,所以必須自己做。另一個問題是非常古怪的擴展要求。他們試圖做一些當時非常大膽的事情,即索引每個網頁的每個字。一些人將每個網頁的每個單詞收錄並編入索引,其他人只是給它建立索引,然後丟棄那些限制競爭對手能力的原始數據。這是一項艱鉅的任務,需要用到當時根本不存在的計算機軟件。
因此,由於不可靠的 Linux 盒子,該軟件必須橫向擴展,並且必須在堆棧的任何組件中容納頻繁的例行故障。之前有一篇很棒的文章提出了“機器是牛而不是寵物”。我認爲在這件事情上谷歌做對了。這些機器沒有來自“星際迷航”的酷炫名字,它們只是 AB 1,2,5,7 類似的東西,那也是機器名。系統對它沒有太多的依賴,它死了或者繼續運行都不會影響其它部分。這個問題讓人們開始思考如何建立更具彈性的系統。
以上是我如何描述事物的方式。在谷歌很多人都有博士學位。記得面試時,我還沒有博士學位。而且,我只跟一個沒有博士學位的人談過,面試結束時,他說,“別擔心,現在開始僱用沒有博士學位的人了”,在那裏有很多人比我更聰明,並且真的想將他們的知識應用到 CS 系統研究中,將這種類型的經驗和知識應用於現實問題是一件很有趣的事情。

在谷歌有很多自下而上的決策,我的第一位經理在我加入時有 120 位直接彙報人的這一事實也說明了這一點,決策的制定是分散且唯一,那裏是一個有抱負的文化氛圍,也是一個非常以任務爲導向的組織,既有基礎設施,還有公司層面,特別是在那個時候,它是一個非常純粹的理想主義組織。具有諷刺意味的是,現在看到新聞時感覺事情發生了很大的變化,至少就公衆形象而言,當然重要的是要記住時間,而且我承認也許有點過分自信。人們可能覺得他們有能力做任何事情,願意嘗試新的大的挑戰,並假設確實可以實現,這很酷有很高的風險,但也很有趣。
那些發生的事情
那麼,這樣的工程要求和文化氛圍實際導致的結果是什麼呢?

這是一張寒武紀大爆發的圖,寒武紀大爆發是進化史上的一個時期,生物多樣性迅速,是多種因素共同作用的結果。我今天早上讀了維基百科,以確保我引用的事實是正確的。它與氧氣的增加有關,鈣的增加使得這些生物能夠製造它們的殼。那時的許多事情都發生在大致相同的時間,在 2000 萬年間,生物多樣性的增長非常迅速。

在谷歌也有類似的東西,業務需要構建一個非常大的架構,這個架構需要圍繞軟件和認爲他們可以嘗試一些新事物的文化背景而構造。這就導致了在谷歌類似寒武紀大爆發一樣的很多基礎設施項目的爆發,許多項目現在已經衆所周知,如 GFS-Google 被廣泛使用的文件系統, BigTable 是 Cassandra 之前的產品,著名的 MapReduce、Borg 是類似於 Kubernetes-ish 的項目。有人可能會因爲我這樣的觀點生氣,但它應該很接近真實的情況,也還有一些沒有公開但令我印象深刻的項目。
其實不僅這些重要的項目衆所周知,他們撰寫的論文也使得這些案例在 Google 之外傳播開來。這些項目與 Hadoop 項目之間存在一對一的對應關係,並從開源社區推廣。但這帶來了一個問題,他們引領谷歌的文化走向崇拜這些項目,人們會認爲在一些與大型基礎設施結構相似的項目上工作真的很酷。這份清單上的所有內容當然都是必要的,Google 也從中受益匪淺。然而谷歌內部的這些貨物崇拜導致人們試圖模仿這些系統的設計而不去理解爲什麼選擇這些設計。

這些設計在很多方面看起來很像今天的微服務。這就是爲什麼我們不把它稱爲微服務,在結構上它們看起來很像微服務。起初想要創造一種可以水平擴展的東西,想要分解像 RPC 服務發現這樣的用戶級基礎設施,但現在“服務網格”中的內容已被考慮到這些巨大的客戶端庫中,這些庫在今天的谷歌被廣泛使用,被稱爲谷歌 3。在谷歌 3 構建一個 Hello World 的二進制文件,它需要消耗 140 兆字節的二進制文件,且只是爲了鏈接這個用戶級別的內核。谷歌 3 爲了完成所有這些工作而將其考慮在內,後來也轉向了一些看起來有點像 CI、CD 的東西。它開始感覺很像微服務了,但是這樣做的決定是出於計算機科學的需求,我認爲這是今天大多數組織構建微服務的一個有趣的理由。
經驗教訓
第一條 開始之前需要明確構建微服務的原因

我認爲構建微服務的唯一充分理由是組織結構,並且這也應該是大多數組織構建微服務的唯一原因。然而,這並不是谷歌構建微服務的原因。谷歌構建微服務是爲了計算機科學,在這裏,我不會去爭辯從這個角度構建微服務其實也沒有什麼好處,當然肯定是有很多痛點驅動。
開始構建微服務之後,如果簡單的認爲它一定會很順利,也沒有事先調研所有可能的失敗情況,那麼一定不會順利,而且實際上也可能會帶來很多令人遺憾的結果。我和很多企業討論過這個問題,這些企業也因爲遷移的過程實在太痛苦了而放棄了向微服務的遷移。所以,一定要事先了解構建微服務的動因。就像谷歌裏有很多人效仿大型的基礎設施項目一樣,有時我認爲他們在構建一些並不必須的架構。理智的投資方式應該是遵循以下原則:“如果你不需要就不要去做,否則只會會讓事情變得更困難”。
這樣做的主要原因是最大限度地減少團隊之間的人員溝通成本,一個超過 10 個或 12 個人的團隊無法在一個工程項目上成功協作,它與人員溝通結構和工作授權有很大關係。因此,將項目團隊映射到微服務可以減少人與人之間的溝通開銷,從而提高開發速度。這是一個選擇微服務的合理原因,但這也並不是我們在谷歌構建微服務的原因。

其實谷歌的微服務不是預先設計的結果,只是一件意外產物。我聽到過很多人分享他們採用微服務的原因,對我而言他們從根本上還是技術驅動。我並不是說這些是錯的。但我認爲,如果這是你選擇微服務的原因,那麼至少你應該慎重的考慮並確認微服務是當下唯一的技術選擇,沒有其它的替代辦法。

我經常從管理層那裏聽到很多實施微服務後帶來的痛苦。我也構建過很多使所有 Google 受益的監控系統,也會不可避免地討論我們的客戶 -Google 內部的項目,其中一些是搜索和廣告等內容,一些是在 Google 雲端硬盤管理控制檯中很少聽說過的功能,它可能是爲谷歌雲端硬盤服務的一個非常重要的項目,但吞吐量並不高,有着一套與搜索和廣告都不同的要求。而且,來自搜索和廣告的經驗教訓只對大規模的服務有意義。就像 Jeff Dean 所說的一句話,一個支撐超過三四個數量級以上規模的系統是無法設計出來的。基於此,我認爲在系統的能力集和功能集,以及系統規模之間存在一個自然的取捨。
可以用一個例子來理解它:如果我們構建了一個具備大規模擴展能力的系統,那麼由於這樣一種自然的規律,在某些角度就必須承認它的功能特性可能很差。我們在谷歌構建的系統具備超級超級的可擴展能力,現在谷歌的公開數據是每秒 20 億次 RPC 調用,這比我想象的實際需要的要多得多。如果要通過擴展來實現這種請求量,那麼必將犧牲很多功能,而這也是在谷歌發生的事情。
Dapper 通過積極的採樣分析解決了這個問題,但坦白說,也給低吞吐量的系統帶來了糟糕的體驗。Kubernetes 項目大概不會真正適用於 Google 的現狀。當觸及實質問題的時候,我們會發現 Borg(谷歌內部的大型集羣管理項目)從很多角度都可以說是一個非常不同的系統。這些取捨在很多地方都會發生,但對於應用程序員們的結果是,他們有大量的需求用來標準化微服務的開發工作,而所參考的微服務本質上卻來自搜索與廣告領域,小型服務的程序員開發體驗因此會變得非常糟糕。
在谷歌,要想將一個服務投放到生產環境是一件很麻煩的事情,因爲所有的需求都必須支持搜索和廣告的水平擴展,即使一個很小的項目也要強制執行。我還記得,我以 20% Project 的方式完成了谷歌天氣項目,當你搜索舊金山的天氣,谷歌天氣就會出現。我一週內完成了原型開發,接下來的幾個星期內完成了核心代碼的生產版本,但總共花了六個月的時間 。實際上也並不是六個月就把它發佈了,因爲我還要完成很多上線必須要做的任務清單任務。
如果一個微服務專注於解決計算機科學研究的問題而非速度,那麼就會發生這種情況。我認爲,開始之前應該明白將要完成的事情,並確保可以專注於速度,保持合理且適合當下實際構建的服務類型的任務清單。因爲促進高吞吐量不同於高工程速度;也不需要考慮低延遲;而低延遲非常重要,但是在吞吐量和工程速度之間需要取捨,反映在技術決策則體現在是否應該使用 JSON 進行通信,還是某些非常嚴格的二進制協議,亦或考慮監控的可觀察性方面。這些事情會讓你的進度慢下來,而大多數的谷歌項目並沒有像搜索和廣告一樣的規模,所以就會非常的痛苦。
第二條 無服務器服務仍然運行在服務器上

在谷歌我們也沒有稱它爲無服務器。上面圖中是一個測試,”火腿三明治、費德勒、怪物卡車、富士山和亞馬遜的 Lambda“,這些其實都是無服務器的,它們只是一些沒有任何意義的術語,所以我非常討厭無服務器這個詞。就像 NoSQL 一樣,我們不應該將這其中一些小事物的反面詞語作爲營銷術的術語。這些詞語沒有任何意義,但是這就是我們生活的世界。我將繼續稱之爲 FaaS- 功能即服務,這個詞至少有意義。

這張圖顯示了每一個工程師都需要知道的一些數字 - 系統運行中不同活動的延遲時間列表。從上向下的第五個是讀取主要內存數據的延遲時間,可以理解爲如果有一個緩存未命中,到達主內存需要大約 100 納秒。如果要在一個數據中心內完成一個 RPC 調用,那時間就遠遠不止於此。

這是另一張同樣活動的數字,主內存數據大約是 100 納秒 - 十分之一微秒,速度很快。即使在同一數據中心內往返,仍然不到一毫秒。所以,當把它與人的速度類比的時候,它的速度感覺有點快,但如果你把它們放在一起,就會發現真的非常不同。而且我認爲有一種趨勢,將事情分解成越來越小的部分會變得非常有趣,以至於我們會忘記了其實兩個進程間通過網絡通信的成本非常高。我也確實看到很多人在這個方向上走的太遠,再次強調一下,這還是癡迷於單一目的服務的理念,也是盲目蠻幹的失敗模式。 我寧願看到圍繞工程組織中的功能單元構建服務,並考慮一定的分區,而不是將事情細分爲儘可能小的部分。
我有些擔心無服務器運動或 FaaS 運動。有時你可以擺脫完全令人尷尬的並行,但在其他情況下緩存真的很有幫助。如果你正通過網絡進行緩存,Mem Cache 有時是合適的,但是,在使用之前要確保完成背後的那些工作,包括如何支撐串行調用的次數,它是否會影響最終用戶的延遲,當前的系統狀況。
所以,我認爲這是微服務的另一種失敗模式,而現在無服務器的市場很大,所以外部市場實際發生的事情遠多於我在 Google 內部所看到的。如果我們想消除對系統運行的擔心,那麼 Etsy 文件及類似的東西都可以解決問題。但是,如果我們將功能作爲一項服務專門討論,請注意一旦賣出概不退換,所以請確保那些功能真的是適合你的系統需求。
第三條 獨立並不是絕對的
我們之前談到過採用微服務的根本原因是團隊溝通成本和獨立的思考等。它開始讓我覺得有點像嬉皮士。就像每個人一樣...... 每個團隊都是一個獨立的決策單位。他們會嬉鬧,需要做的只是決定 API,發送請求然後響應。在微服務架構下,每個團隊可以做他們想做的任何事,它是平等和美麗的。
這些實際上是來自我之前對話的一家公司,他們不得不將已經完成的微服務回滾。在爲單個服務寫代碼的時候開發工作還是很順利的,但在部署的時候問題就來了,交叉出現了一系列的跨服務橫切關注點,尤其在生產環境中。那些顯而易見的關注點包括安全性、監控、服務發現、身份驗證等。這些都是跨功能的關注點。這時候會面臨兩個問題,第一個問題,每一個團隊都必須承擔運維壓力,而每一個團隊的規模相對較小,所以必須要付出額外的成本。第二,其中一些事情是全局的問題,特別像可觀察性,需要從系統的全局進行設計,而這樣的事情如果每個團隊自己做決定,將會失去統一有效的機制。
Jessica 也談到了這一點。聽起來 Airbnb 正在以正確的方式接近這個方向,但這是一個重大問題。我認爲,當人們追求微服務的獨立性時,他們應該考慮哪些維度實際上是獨立的,哪些維度應該委託給某類平臺團隊。我今天早上和 O'Reilly 的一個人談論了可能對微服務領域有幫助的書籍,其中我認爲看一本關於在微服務項目和人員管理方面的書會很有用,可以有助找出應該獨立的和不應該獨立的那些因素。

在這個問題上,我認爲螞蟻做對了。螞蟻,無論性別身份如何,都是獨立的。它們獨立完成自己的工作,但是會堅定遵循蟻羣的行爲規則。有時螞蟻們可能很痛苦,但是蟻羣這樣做的目的爲了獲取更大的利益。儘管這對單隻螞蟻來說可能是令人沮喪的,但這就是蟻羣可以活下去的工作方式。就如有時候使用一個簡短前綴的語言菜單和技術令人很沮喪,但是如果你的組織有一個支持微服務的短平臺列表,這大概是最好的選擇。在這個方面我認爲谷歌做的對,谷歌對事物的分解有時候近似瘋狂,在某種程度上,我建議儘可能將事情從你的服務中獨立出來。我喜歡螞蟻,圖中顯示了它們的服務發現,如果螞蟻們通過隨機散步找到了食物,它們會返回巢穴並沿路留下信息素,隨後其他螞蟻聞到並跟隨它找到食物源。螞蟻們非常聰明。在大學,我們有一個有趣的編程作業來模擬螞蟻的這種行爲 - 一種非常優雅且效果很好的集體行爲。當有威脅時,螞蟻們會進行一系列的智能安全措施並聚集幼蟲,它們會把所有的熔岩都帶走並隱藏起來,這是蟻羣爲了共同的利益而採取的集體行爲。螞蟻們還構建了一些令人驚奇的物體,尤其考慮到它們是昆蟲類動物,螞蟻絕對稱得上是優秀的工程師。他們做的對。
我認爲,在微服務中需要更多地考慮螞蟻精神而不是嬉皮士精神。在這個時代,嬉皮士精神可能不應該進入工程管理領域,這是微服務的錯誤信念和價值觀。
第四條 警惕巨大的儀表板
我曾在谷歌的 Dapper 和 Monarch 項目工作過,Monarch 這個項目在谷歌並沒有太多的記錄,John Banning 曾在 Monitorama 分享過。Monarch 的規模非常大,它以服務的方式運行,基本上就像是一個爲整個谷歌設計的高可用性時間序列監控系統。在這個項目中,我花了大量時間與 Google 的 SRE 團隊交流,其中有一些非常棒的實踐給了我很多啓發。Cody Smith 是負責網絡搜索的 SRE。網絡搜索作爲儀表板設計的非常緊湊,就像十幾棵草攢在一起,但卻具有令人難以置信的時間保真度。就如每秒分辨率,存在一百萬個維度去解釋圖形中的任何變化以及某種維度的過濾聚合。還有其他的項目也有這些巨大的儀表板,有很多很多頁的信息。它們背後的設計思路是可以通過掃描所有的信息並找到其中的問題或類似的問題。但我認爲這是一個非常糟糕的模式。
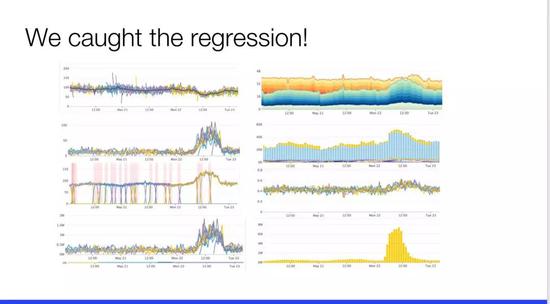
這是內部儀表板中的一組圖表。通過這張圖,很明顯可以看出這裏大約在 12 點出現了一些問題,而這裏的高峯期是 12:20 左右,另一邊的圖顯示峯值在 12 點之前,這些圖標顯示的數據大都相關。
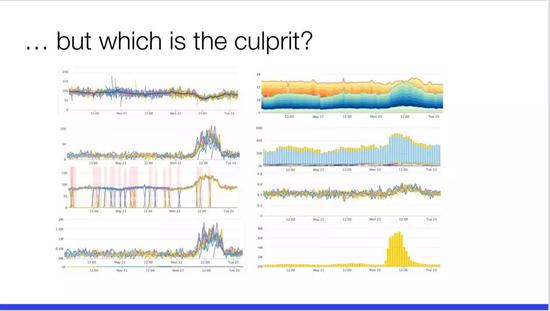
然而,這麼多呈現的圖表,接下來我們應該查看哪一個進一步定位問題?我一點概念都沒有。真正瞭解這些系統的人可能通過一些細節可以辨識這些圖標背後的含義,但如果是正在隨時待命處理生產環境問題的運維人員則必須快速找出問題,這個儀表板則是一個糟糕的情況,有八個圖表,還有另外十幾個顯示相同的情況。另外,還有的儀表板的頁面一次又一次地顯示同一個故障,這樣實際上對於分析問題也並不可行。然而對微服務架構來說這是一個重要問題,每個服務都會生成大量的儀表板或 RPC 和服務網格等等,包括業務指標。
之後,儀表板會呈現分佈式系統中的級聯故障,這些故障在很多地方都可以看到。微服務的本質是服務間具有相互依賴關係,A 依賴 B,B 依賴於 C,C 依賴於 D,D 出現了一次故障且反映在 CBNA 中。在儀表板中,應該可以通過查看波浪線找出根本原因,然而現實卻不是這樣。儀表板應該服務於 SLI 即服務水平指標,它代表了消費者關心的內容,之後的根因分析則需要基於此進行引導分析和改進。

我認爲可觀察性包括兩件事,一個是檢測關鍵信號,即 SLI 的部分,它需要非常精確;另一個則是改進搜索空間。每增加一個微服務,可能發生的故障模式的數量隨着服務數量的增長而幾何式增長。我並不認爲機器學習或 AI 可以神奇地解決這個問題。我們需要儘快發現可以幫助減少人腦假設的方法,只有在使用巨型儀表板之外的技術時才能實現引導過程。巨型儀表板在單體環境中運行良好,但我看到人們採用這種理念並圍繞它構建微服務的可觀察性。我認爲有必要使用儀表板,但肯定不夠。我採訪過的 SRE 小組當時正在構建巨大的儀表板,我們的效率明顯低於讓它設計上更緊湊的團隊,之後再使用其他工具來改進搜索空間。所以,不要混淆搜索空間的可視化和對它的精煉優化。整個搜索空間太大了且無法可視化,而且人類迄今也無法處理那麼多信息。
在 LightStep,我們看到很多客戶一直在努力解決這類問題。我不知道在座的各位是否經歷過同樣的情況,但我認爲這是一種失敗模式,谷歌肯定也明白這一點。曾經有一個大型的 Google 服務,大概名字是家庭類型之類的服務,它不得不使用代碼生成器生成告警配置,最終導致了 35,000 行還要長的代碼。我不記得其中的所有原因。但隨後他們不得不開始手動維護這 35,000 行代碼,然而這些配置是在 Google 內部完全模糊的 DSL 中編寫的,手動維護所帶來的痛苦程度無法比擬,這就是因爲他們混淆了對 SLI 的告警信息和可能是根本原因的告警信息。監控不應該對根本原因發出告警,它應該是細化過程的一部分;而應該對 SLI 發出告警,對於任何特定系統,SLI 的信息不會有那麼多而導致無法處理。
第五條 無法跟蹤一切
這條教訓來自 Dapper 項目。在某種程度上和之前對谷歌系統的評價類似,”當一個系統變得如此龐大時,它所提供的解決方案功能集會相對的減少”。我們當時正在與搜索和廣告對 Dapper 的要求進行抗爭,它們要求 Dapper 每秒支持數億次查詢,而我們能做到的唯一方法就是積極地進行採樣分析。
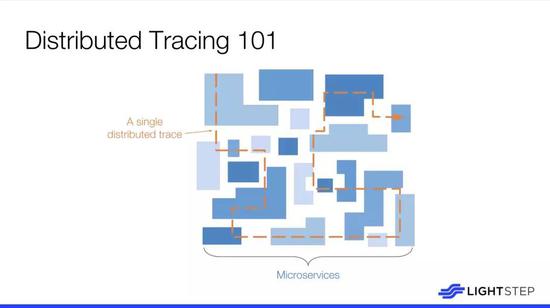
微服務的結構看起來很像多邊形,在運行中會產生事務經過這些組件,有些事務也會調用多個其它服務,所以瞭解一個微服務系統最基礎層面發生的事情可以更好的維護和提供服務,諸如服務請求的起點、它的旅程直到請求的結束,這就是分佈式跟蹤的最基本想法。如果沒有實現這樣的功能,另一種可替代的方式則是讓其他人通過電話幫助調試,但實現起來非常痛苦。分佈式跟蹤的功能對於分佈式系統來說非常有價值。

它的問題是跟蹤在這個圖的數據科學和數據工程中有一個黑暗的祕密跟蹤。
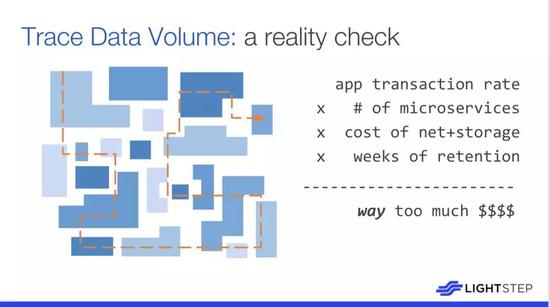
圖中呈現了數據卷的真實檢查數據,可以看出堆棧頂部的實際事務數量,隨着業務增長,這個數據的總量大概需要再乘以服務數量。因此,當遷移至微服務後,數據量也會相應增長,這個增長與事務總數不成比例,但與服務的數量成正比,大概是乘以網絡成本和存儲此數據的成本,之後還需要將數據存儲一段有效時間。基本上,從第一原則的角度來看,微服務系統中的數據太多。在更快的網絡或更便宜的存儲被髮明之前,現在的數據真的太多了。這個問題會反映在過高的 Splunk 賬單或者 ELK 失效。但如果你使用日誌記錄作爲跟蹤數據,然後嘗試使在同一管道中聚合,這個問題就會發生。分佈式跟蹤通常被認爲是這些時序圖,但實際上它只是一種使用內置採樣機制進行事務性日誌記錄的方法。
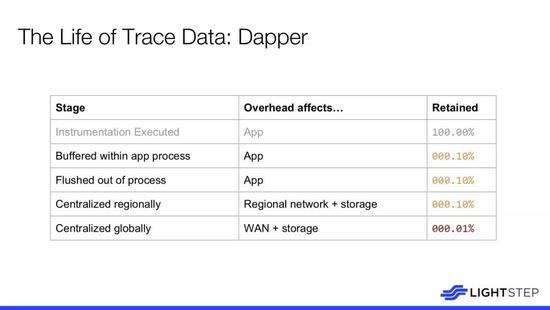
對於 Dapper,我們需要將其用於 Web 搜索和廣告,也因此而積極的採樣分析。我們在交易之前做的第一件事就是翻轉一枚硬幣選擇它作爲樣本數據,這樣可以將數據量減少 99.9%,這種方法很有幫助。然而,事實證明這還不夠,即使將 1000 箇中的一個請求集中在一起的成本也很昂貴。因此,在全局集中這些數據之前還需要進行進一步的抽取 1:10000,之後可以 MapReduce 以及更復雜的分析。這就是在 Google 完成這項工作所必需的。然而,就我個人而言非常後悔並對此種做法深感遺憾。坦率講,相較於在 Dapper 的做法,我認爲應該可以找到另一種方法提供更多的按鈕並且更面向長遠的考慮,這也是我爲什麼會成立 LightStep 的原因。
Dapper 由 Sharon Pearl 和 Mike Burrows 兩人創辦,他們都來自前面提到的 Compaq DEC 併購,但對此並不是很開心。Mike 在微軟研究院工作過,那時他在研究 Bing 搜索產品,當他去谷歌時,有人稱他的背景並不允許他在谷歌工作。他喜歡搜索,之後他創建了 Chubby,有點像 Zookeeper,同時還參與了許多其他項目。而 Sharon 促使了我加入 Dappe。 在早期的職業生涯裏,谷歌做過這樣一件事情:他們會在組織裏給你匹配一個與你儘可能不同的人,他們會從九維空間的角度進行員工走查,包括工作的語言、離開學校的時間、辦公地點、彙報結構等。
在參與這項調查的人裏面,Sharon 是與我最不相同的那個人,當時我還在廣告項目,並不是很喜歡當時的工作。Sharon 給我列出來她正在參與的一系列項目,並提到了 Dapper,而他們當時真的不想將它產品化。我聽了之後卻喜歡上了它,“這聽起來比我正在做的事情更加有趣”,之後我管理了大約 120 份報告,我開始研究它想做一些更野心勃勃的事情,我的導師 Luis 在這當中也建議我 “這足以讓人在谷歌的每臺機器上跑步了。你爲什麼不先解決它?”這真的是一個有些政治和塹壕戰的項目,但這就是他告訴我要做的事情。我也做到了,但我真的後悔了。因爲其實還有很多其它的方法可以解決這個問題。這無關我的 LightStep 項目,相比於方法,LightStep 給出了很多可以瞭解系統的機會。
總結

最後總結一下,我認爲選擇微服務有兩個驅動因素:獨立和計算機科學。開始微服務之前要確保在組織級別推進微服務的原因。構建微服務的目的在於優化速度,它不是指工程速度,也不是指系統吞吐量。一件事情開始的原因不同會導致不同的結果。第二,需要了解所選解決方案的適合規模。對於整個無服務器 FaaS 話題,不要因爲它很有趣而繼續縮小和縮小。“嘗試做個螞蟻,而不是嬉皮士”。第三,可觀察性不是關於三大支柱,它只是有關數據的檢測和改進。考慮一下這些工作流程,跟蹤所有內容則是可能的。從調試和性能優化角度來看,這是解決此問題的一種有趣方式。









