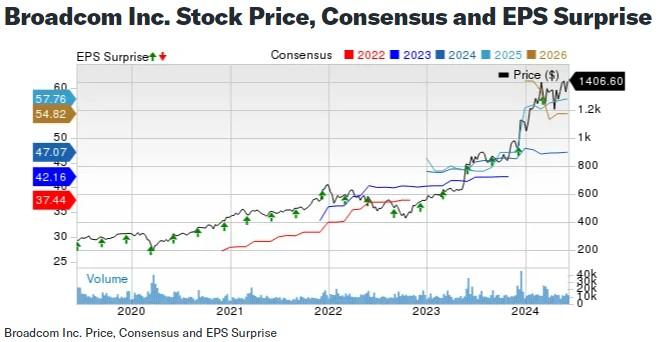
Huskarl 最近進展:已支持與 OpenAI Gym 環境無縫結合
摘要:\u003C\u002Fp\u003E\u003Cimg src=\"http:\u002F\u002Fp3.pstatp.com\u002Flarge\u002Fpgc-image\u002FRX2DzBcA5qBYBg\" img_width=\"700\" img_height=\"558\" alt=\"Huskarl 最近進展:已支持與 OpenAI Gym 環境無縫結合\" inline=\"0\"\u003E\u003Cp\u003E創建並可視化深度強化學習網絡(DQN)智能體的完整代碼\u003C\u002Fp\u003E\u003Cimg src=\"http:\u002F\u002Fp1.pstatp.com\u002Flarge\u002Fpgc-image\u002FRX2DzBzDSJW3vB\" img_width=\"710\" img_height=\"284\" alt=\"Huskarl 最近進展:已支持與 OpenAI Gym 環境無縫結合\" inline=\"0\"\u003E\u003Cp\u003EHuskarl DQN 智能體學習平衡 cartpole(完整動態圖點擊原文鏈接查看)\u003C\u002Fp\u003E\u003Cp\u003E目前 Huskarl 支持的一些算法可以在三類可調智能體上運行。\u003C\u002Fp\u003E\u003Cimg src=\"http:\u002F\u002Fp3.pstatp.com\u002Flarge\u002Fpgc-image\u002FRX2DzCP1xBpxKe\" img_width=\"706\" img_height=\"281\" alt=\"Huskarl 最近進展:已支持與 OpenAI Gym 環境無縫結合\" inline=\"0\"\u003E\u003Cp\u003EHuskarl DDPG 智能體學習提升鐘擺\u003C\u002Fp\u003E\u003Cp\u003EHuskarl 可以輕鬆地跨多個 CPU 內核並行計算環境動態,這非常很有助於如 A2C 和 PPO 這類策略性(從多個併發經驗源中學習數據)算法的加速。
"\u003Cp\u003E\u003Cstrong\u003E雷鋒網 AI 科技評論按:\u003C\u002Fstrong\u003E近日,Github 上開源的一個專注模塊化和快速原型設計的深度強化學習框架 Huskarl 有了新的進展。該框架除了輕鬆地跨多個 CPU 內核並行計算環境動態外,還已經成功實現與 OpenAI Gym 環境的無縫結合。TensorFlow 發佈了相應的文章來報道此研究成果,雷鋒網 AI 科技評論將其編譯如下。\u003C\u002Fp\u003E\u003Cimg src=\"http:\u002F\u002Fp9.pstatp.com\u002Flarge\u002Fpgc-image\u002FRX2DzBMBIYoKZr\" img_width=\"640\" img_height=\"339\" alt=\"Huskarl 最近進展:已支持與 OpenAI Gym 環境無縫結合\" inline=\"0\"\u003E\u003Cp\u003E\u003C\u002Fp\u003E\u003Ch3\u003E背景概述\u003C\u002Fh3\u003E\u003Cp\u003E深度學習革命在計算機視覺和自然語言處理等領域取得了許多最新的進展和突破。尤其是在深度強化學習這個特別的領域,我們已經看到了非凡的進展。2013 年 DeepMind 出版了「用深度強化學習來玩 Atari」,這個模型只通過觀看屏幕上的像素,就可以學習如何玩 Atari 遊戲。三年後,AlphaGo 擊敗了圍棋世界冠軍,這一舉動吸引了全球觀衆的注意。在這之後,AlphaZero 又打破了從人類比賽中學習的規定,將自我學習推廣到任何完美的信息遊戲,並有效地成爲圍棋、國際象棋和日本將棋的世界冠軍。Huskarl 在這樣的深度學習熱潮之下,有了更深入的研究進展。\u003C\u002Fp\u003E\u003Cp\u003E模型框架\u003C\u002Fp\u003E\u003Cp\u003EHuskarl 是一個新的開源框架,用於深度強化學習訓練,專注於模塊化和快速原型設計。它基於 TensorFlow 2.0 構建,並使用了 tf.keras API 以實現其簡潔性和可讀性。\u003C\u002Fp\u003E\u003Cp\u003EHuskarl 最近在 PoweredByTF 2.0 挑戰賽(https:\u002F\u002Ftensorflow.devpost.com\u002F)中獲得第一名,該挑戰賽意在讓研究人員更易於對深度強化學習算法進行運行、測試、優化和對比的操作。\u003C\u002Fp\u003E\u003Cp\u003EHuskarl 與 TensorFlow 抽象出計算圖的管理以及 Keras 創建高級模型的想法類似,它抽象出了智能體與環境的交互。這便使用戶能夠專注於開發和理解算法,同時還可以防止數據泄漏。Huskarl 可以做到與 OpenAI Gym 環境的無縫結合,其中也包括了 Atari 環境。下面是創建並可視化深度強化學習網絡(DQN)智能體所需的完整代碼,該智能體將學習 cartpole 平衡問題。\u003C\u002Fp\u003E\u003Cimg src=\"http:\u002F\u002Fp3.pstatp.com\u002Flarge\u002Fpgc-image\u002FRX2DzBcA5qBYBg\" img_width=\"700\" img_height=\"558\" alt=\"Huskarl 最近進展:已支持與 OpenAI Gym 環境無縫結合\" inline=\"0\"\u003E\u003Cp\u003E創建並可視化深度強化學習網絡(DQN)智能體的完整代碼\u003C\u002Fp\u003E\u003Cimg src=\"http:\u002F\u002Fp1.pstatp.com\u002Flarge\u002Fpgc-image\u002FRX2DzBzDSJW3vB\" img_width=\"710\" img_height=\"284\" alt=\"Huskarl 最近進展:已支持與 OpenAI Gym 環境無縫結合\" inline=\"0\"\u003E\u003Cp\u003EHuskarl DQN 智能體學習平衡 cartpole(完整動態圖點擊原文鏈接查看)\u003C\u002Fp\u003E\u003Cp\u003E目前 Huskarl 支持的一些算法可以在三類可調智能體上運行。\u003C\u002Fp\u003E\u003Cp\u003E第一類是 DQN 智能體,它可以實現深度 Q 學習(https:\u002F\u002Farxiv.org\u002Fabs\u002F1509.06461)以及多種增強功能,例如:可變步長跟蹤(variable-step traces)、雙 DQN 和可調整的對抗架構(dueling architecture)。DQN 是一種非策略算法,我們的實現默認使用優先經驗回放(Prioritized experience replay)。DQN 智能體主要處理離散動作空間的問題。\u003C\u002Fp\u003E\u003Cp\u003E第二類是 A2C 智能體,它採用了同步、多步的「優勢動作-評論」(Advantage Actor-Critic)模型,這是一種基於策略的算法。(有關 A2C 與 A3C 之間差異的更多信息,可參閱此博客文章 https:\u002F\u002Fopenai.com\u002Fblog\u002Fbaselines-acktr-a2c\u002F)Huskarl 允許像 A2C 這樣基於策略的算法輕鬆地同時從多個環境實例中獲取經驗數據,這有助於數據的整理過程變得更加穩定,從而更利於學習。\u003C\u002Fp\u003E\u003Cp\u003E第三類是 DDPG 智能體,它採用了變步長跟蹤的深度確定性策略梯度(Deep Deterministic Policy Gradient)算法,同時在默認情況下也使用優先經驗回放。DDPG 智能體專用於處理連續動作空間的問題。\u003C\u002Fp\u003E\u003Cimg src=\"http:\u002F\u002Fp3.pstatp.com\u002Flarge\u002Fpgc-image\u002FRX2DzCP1xBpxKe\" img_width=\"706\" img_height=\"281\" alt=\"Huskarl 最近進展:已支持與 OpenAI Gym 環境無縫結合\" inline=\"0\"\u003E\u003Cp\u003EHuskarl DDPG 智能體學習提升鐘擺\u003C\u002Fp\u003E\u003Cp\u003EHuskarl 可以輕鬆地跨多個 CPU 內核並行計算環境動態,這非常很有助於如 A2C 和 PPO 這類策略性(從多個併發經驗源中學習數據)算法的加速。首先,如果要同時使用多個環境實例,我們只需爲基於策略的智能體和模擬器提供所需數量的環境實例;然後將環境實例分佈在多個進程上,這些進程將在可用的 CPU 內核上自動並行化;之後我們只需在調用 sim.train函數時爲 max_subprocesses 參數提供所需的值即可,詳情如下面的代碼段所示。\u003C\u002Fp\u003E\u003Cimg src=\"http:\u002F\u002Fp1.pstatp.com\u002Flarge\u002Fpgc-image\u002FRX2DzCo10iXpBX\" img_width=\"694\" img_height=\"353\" alt=\"Huskarl 最近進展:已支持與 OpenAI Gym 環境無縫結合\" inline=\"0\"\u003E\u003Cp\u003EHuskarl 實現策略性算法加速的代碼段(跳轉原文可查看完整代碼)\u003C\u002Fp\u003E\u003Cp\u003E另外需要注意的是,爲每個環境實例使用不同的策略非常簡單,無需提供單個策略對象,只需提供策略列表即可。\u003C\u002Fp\u003E\u003Cimg src=\"http:\u002F\u002Fp3.pstatp.com\u002Flarge\u002Fpgc-image\u002FRX2CdWGAYQRm06\" img_width=\"716\" img_height=\"303\" alt=\"Huskarl 最近進展:已支持與 OpenAI Gym 環境無縫結合\" inline=\"0\"\u003E\u003Cp\u003EHuskarl A2C 智能體同時學習 16 個環境實例來平衡 cartpole。其中,較粗的藍線表示使用貪婪的目標政策獲得的獎勵,當在其他 15 個環境中起作用時使用高斯ϵ-貪婪(gaussian epsilon-greedy)策略,epsilon 均值從 0 變爲 1\u003C\u002Fp\u003E\u003Cp\u003E但如果在某些簡單環境中,如 cartpole 環境,強行使用多個進程並行會因進程間通信成本增大而減慢訓練速度。因此,只有在計算成本較高的環境下,這種多進程並行才能發揮有利的作用。\u003C\u002Fp\u003E\u003Cp\u003E所有可運行的智能體都會依賴於每個問題規範,因此,其使用的神經網絡由用戶提供。這些神經網絡是多樣化的(簡單、淺顯、複雜、富有深度均可)。智能體通常會在內部向所提供的神經網絡添加一個或多個層,以便正確地執行它們的預期功能。此外,所有算法都充分利用了自定義 Keras 損失,使其運行能夠儘可能快速與簡潔。目前我們有三個示例(每個智能體一個),這些示例使用了微小的、完全連接的網絡來展示智能體的功能,甚至是使用簡單模型,結果也不會改變。\u003C\u002Fp\u003E\u003Cp\u003E目前,Huskarl 支持 DQN(Deep Q-Learning Network)、Multi-step DQN、Double DQN、A2C(Advantage Actor-Critic)、DDPG(Deep Deterministic Policy Gradient)等算法,PPO(Proximal Policy Optimization)、Curiosity-Driven Exploration 等算法仍在計劃中。\u003C\u002Fp\u003E\u003Cimg src=\"http:\u002F\u002Fp1.pstatp.com\u002Flarge\u002Fpgc-image\u002FRX2CaiPHmnFsKt\" img_width=\"416\" img_height=\"266\" alt=\"Huskarl 最近進展:已支持與 OpenAI Gym 環境無縫結合\" inline=\"0\"\u003E\u003Cp\u003EHuskarl 支持算法列表\u003C\u002Fp\u003E\u003Cp\u003E\u003C\u002Fp\u003E\u003Ch3\u003E未來計劃\u003C\u002Fh3\u003E\u003Cp\u003E我們計劃加入更新穎的深度強化學習算法,例如近端策略優化算法(PPO,Proximal Policy Optimization),柔性致動\u002F評價算法(SAC,Soft Actor-Critic)和雙延遲深度確定性策略梯度(TD3,Twin Delayed Deep Deterministic Policy Gradient)。\u003C\u002Fp\u003E\u003Cp\u003E此外,我們還計劃引入內在的獎勵方法,如好奇心方法(curiosity)和賦權方法(empowerment)。其目的是希望用戶能夠更輕鬆地交換和組合深度強化學習算法中的不同組件,例如經驗回放、輔助獎勵以及像堆疊樂高積木一樣的智能體任務。同時,我們還計劃在未來開源多智能體環境和 Unity3D 環境。\u003C\u002Fp\u003E\u003Cblockquote\u003E\u003Cp\u003E原文地址\u003C\u002Fp\u003E\u003Cp\u003Ehttps:\u002F\u002Fmedium.com\u002F@tensorflow\u002Fintroducing-huskarl-the-modular-deep-reinforcement-learning-framework-e47d4b228dd3\u003C\u002Fp\u003E\u003Cp\u003EGithub 地址\u003C\u002Fp\u003E\u003Cp\u003Ehttps:\u002F\u002Fgithub.com\u002Fdanaugrs\u002Fhuskarl\u003C\u002Fp\u003E\u003C\u002Fblockquote\u003E\u003Cp\u003E雷鋒網 AI 科技評論\u003C\u002Fp\u003E"'.slice(6, -6), groupId: '6716777539462758926