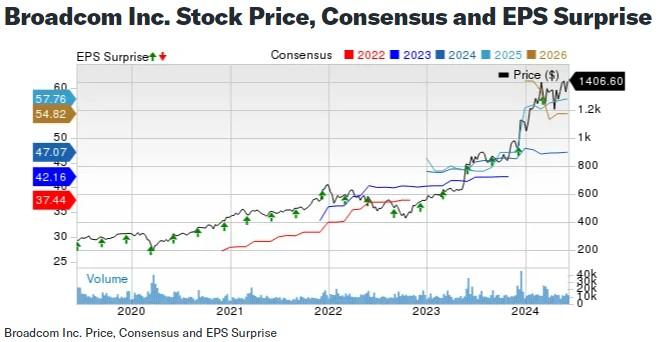
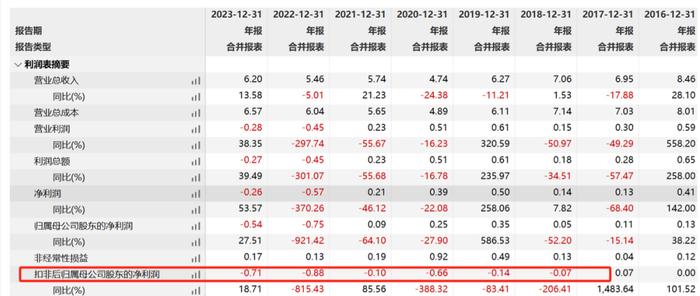
認知智能的突圍:NLP、知識圖譜是AI下一個“掘金地”?
摘要:\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E本文後面的章節,就從虛擬生命1.0,也就是聊天機器人的角度,來闡述目前自然語言處理和知識圖譜的技術落地,以及如何實現基本的機器人認知能力。而構建知識圖譜是一個系統工程,其整體的技術棧如圖7所示:\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cdiv class=\"pgc-img\"\u003E\u003Cimg src=\"http:\u002F\u002Fp1.pstatp.com\u002Flarge\u002Fpgc-image\u002F6684250335b04a5688638ea6488093ca\" img_width=\"1080\" img_height=\"604\" alt=\"認知智能的突圍:NLP、知識圖譜是AI下一個“掘金地”。
"\u003Cdiv\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E作者 | 劭浩,上海瓦歌智能科技有限公司總經理,狗尾草科技人工智能研究院院長\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E責編 | 許愛豔\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E出品 | AI科技大本營(ID:rgznai100)\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Ch1 class=\"ql-align-center\"\u003E\u003Cstrong\u003E一、引言\u003C\u002Fstrong\u003E\u003C\u002Fh1\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E最近,很多人邀請我回答下面的這些問題:\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E“人工智能能否取代人類?”\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E“十年內,人類是否能製造出賈維斯那樣的AI?”\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E“人工智能什麼時候纔會擁有自我意識?”\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E爲什麼大家對這類問題如此感興趣?\u003C\u002Fstrong\u003E這可能要追溯到2016年,AI真正進入到大衆視野並引爆媒體的標誌性事件,也就是AlphaGo戰勝圍棋的世界冠軍-李世石。在之後,我們看到一個又一個AI技術的突破,以及不斷被刷新的媒體頭條,好像AI取代人類是完全可能而且理所應當的事情。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E我們看到波士頓動力的機器人行雲流水般的後空翻,看到索菲亞在各大場合欺騙人類感情,看到Dota2、星際爭霸等遊戲被AI攻破,也看到IBM的辯論機器人和人類旗鼓相當的交鋒,在2019年7月份《Science》發表的研究成果中,一個名爲Pluribus的算法僅僅通過自我博弈,就在多人無限注德州撲克中戰勝了人類專業選手[1]。人工智能在這第三輪的熱潮中,通過大數據和深度學習,創造了一項又一項歷史,也吊足了普羅大衆的胃口。\u003C\u002Fp\u003E\u003Cblockquote\u003E人工智能從1956年被提出至今,經歷了三次大的熱潮。20 世紀50 年代中期到80 年代初期的感知器,20世紀80 年代初期至21 世紀初期的專家系統,以及最近十年的深度學習技術,分別是三次熱潮的代表性產物。\u003C\u002Fblockquote\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E爲了回答這些問題,我拋出了一張2018年Gartner技術曲線,解釋目前人工智能的進展。如圖1所示。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cdiv class=\"pgc-img\"\u003E\u003Cimg src=\"http:\u002F\u002Fp3.pstatp.com\u002Flarge\u002Fpgc-image\u002F98cf7a2016e84bcca399e6d46e9fba04\" img_width=\"1050\" img_height=\"708\" alt=\"認知智能的突圍:NLP、知識圖譜是AI下一個“掘金地”?\" inline=\"0\"\u003E\u003Cp class=\"pgc-img-caption\"\u003E圖1 Gartner2018技術成熟度曲線\u003C\u002Fp\u003E\u003C\u002Fdiv\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003EGartner每年發佈的技術趨勢曲線,聚焦未來5到10年間,可能產生巨大競爭力的新興技術。在圖中我們可以看到,深度學習(Deep Learning)已經走到高原期(Peak of Inflated Expectations),而知識圖譜(Knowledge Graph)還是在起步階段(Innovation Trigger),更不用說腦機接口(Brain-Computer Interface)、通用人工智能(Artificial General Intelligence)這些技術,在圖中的標記還是黃色三角,也就是起碼10年會後才能到達高原期。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E人工智能技術遠未達到媒體所宣傳的神通廣大,無所不能。從圖1中的技術發展現狀也可一窺端倪。AlphaGo可以戰勝最好的人類棋手,但卻不可能爲你端一杯水。著名機器人學者Hans Moravec早前說過:機器人覺得容易的,對於人類來講將是非常難的;反之亦然。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E人可以輕鬆做到聽說讀寫,但對於複雜計算很喫力;而機器人很難輕鬆做到用手抓取物體、以及走上坡路,但可以輕而易舉地算出空間火箭的運行軌道。人類可以通過日積月累的學習,輕鬆完成各種動作,但對於機器人來講完成這些簡單的動作難如登天。專家們稱此理論爲“莫拉維克悖論”(Moravec's Paradox)。機器學習專家、著名的計算機科學和統計學家 Michael I. Jordan近日在《哈佛數據科學評論》上發表文章,也認爲現在被稱爲AI的許多領域,實際上是機器學習,而真正的 AI 革命尚未到來。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E在目前,即使是最先進的AI智能體,在適應環境變化的能力方面,也無法與動物相提並論。近期,英國帝國理工學院和劍橋大學研究人員共同組織了一場特別的AI競賽,希望把動物能夠完成的“覓食任務”交給AI智能體來完成,讓AI和動物世界來一場虛擬比賽。我們也期待着這項比賽的結果。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E因此,人工智能,任重而道遠。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Ch1 class=\"ql-align-center\"\u003E\u003Cstrong\u003E二、從感知智能到認知智能\u003C\u002Fstrong\u003E\u003C\u002Fh1\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E業界一致認爲,AI的三要素是算法,算力和數據。近十年來,人工智能的技術突破,很大程度上是得益於大數據以及大規模運算能力的提升,真正讓深度學習這項“老”技術煥發了新生,突破了一項又一項感知能力。追溯到2006年,Geoffrey Hinton和他的學生在《Science》上提出基於深度信念網絡(Deep Belief Networks, DBN)可使用非監督學習的訓練算法;隨後2012年深度神經網絡技術在ImageNet評測中取得了突破性進展,人工智能進入到新的熱潮,圍繞語音、圖像、機器人、自動駕駛的技術大量湧現,也出現了很多里程碑水平的技術。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E2017年8月20日,微軟語音和對話研究團隊負責人黃學東宣佈微軟語音識別系統取得重大突破,錯誤率由之前的5.9%降低到5.1%,可與專業速記員比肩[2];Google在2015年提出的深度學習算法,已經在ImageNet2012分類數據集中將錯誤率降低到4.94%,首次超越了人眼識別的錯誤率(約5.1%)[3];DeepMind公司在2017年6月發佈了當時世界上文本到語音環節最好的生成模型WaveNet語音合成系統;由斯坦福大學發起的SQuAD(Stanford Question Answering Dataset)閱讀理解競賽,截至2019年7月,使用BERT的集成系統暫列第一,其F1分值達到89.474,超越了人類水平。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E從計算,到感知,再到認知,是大多數人都認同的人工智能技術發展路徑。那麼認知智能的發展現狀如何?\u003C\u002Fstrong\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E首先,讓我們看一下什麼是認知智能。\u003C\u002Fstrong\u003E復旦大學肖仰華教授曾經提到,所謂讓機器具備認知智能是指讓機器能夠像人一樣思考,而這種思考能力具體體現在機器能夠理解數據、理解語言進而理解現實世界的能力,體現在機器能夠解釋數據、解釋過程進而解釋現象的能力,體現在推理、規劃等等一系列人類所獨有的認知能力上。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E也就是說,認知智能需要去解決推理、規劃、聯想、創作等複雜任務。\u003C\u002Fstrong\u003E我們可以大膽想象,如果機器人具備了認知智能,那麼我們周圍就會出現很多電影裏才能看到的智能機器,比如說《銀翼殺手2049》裏的喬伊,《她》中的薩曼莎,以及《超能查派》裏的機器人查派,這些智能機器會有意識,有情感,並且有自己的善惡觀。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E人類總是想當造物主,讓機器擁有認知智能,其實在一定程度上是希望模仿生命本身,尤其是人類的各種能力。在維基百科給出的定義中,生命泛指一類具有穩定的物質和能量代謝現象並且能回應刺激、能進行自我複製(繁殖)的半開放物質系統。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E簡單來說,也就是有生命機制的物體,是存在一定的自我生長、繁衍、感覺、意識、意志、進化、互動等豐富可能的一類現象。科學家從來沒有停止對生命的再造和探索,也就自然而然產生了“人工生命”(Artificial Life)的概念。人工生命可以分爲兩個方面,一是人造生命,特指利用基因工程技術創造的人工改造生物。另一方面則是本文所要探討的虛擬生命(Virtual Life),特指利用人工智能創造的虛擬生命系統。(注:本文只討論軟件層面上的認知智能,因此不涉及對控制論、機器人硬件的討論。)\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Ch1 class=\"ql-align-center\"\u003E\u003Cstrong\u003E三、創造具有認知智能的虛擬生命\u003C\u002Fstrong\u003E\u003C\u002Fh1\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E一個具備認知智能的虛擬生命,不僅僅可以和人類進行多模態交互,還需要有具有生命感的表達能力。\u003C\u002Fstrong\u003E圖2給出了虛擬生命的基本能力範疇。對於看、聽、說、動作而言,感知智能已經可以達到非常好的效果。而對於推理、情感、聯想等能力,還需要更強的認知能力的體現。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cdiv class=\"pgc-img\"\u003E\u003Cimg src=\"http:\u002F\u002Fp3.pstatp.com\u002Flarge\u002Fpgc-image\u002F7bcb703076b54a7f9fc056e66cd8ccca\" img_width=\"1080\" img_height=\"547\" alt=\"認知智能的突圍:NLP、知識圖譜是AI下一個“掘金地”?\" inline=\"0\"\u003E\u003Cp class=\"pgc-img-caption\"\u003E圖2 虛擬生命基本能力範疇\u003C\u002Fp\u003E\u003C\u002Fdiv\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E那麼問題來了,在現有技術條件下,是否能實現虛擬生命的認知能力?這也就是文章開頭提到的問題的關注點。微軟亞洲研究院宋睿華老師(微軟小冰首席科學家)曾經說過一個故事,她在和母親聊天的時候,問“如果機器人可以打敗人類最頂尖的棋手,厲不厲害?”,母親回答說“很厲害“。她再問母親”如果我們做出一個機器人,可以和人聊天,厲不厲害?“,母親回答說”不厲害“。宋老師就問爲什麼,母親的回覆是”因爲不是每個人都會下棋,但每個人都會說話啊“。這個故事其實告訴我們,讓機器人說話,雖然技術上非常複雜,但離人類的期望值還相差甚遠。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E即便是機器人可以聊天,那是不是就可以說其擁有了認知智能?答案仍然是否定的。\u003C\u002Fstrong\u003E會說話的機器很多,不僅僅是聊天機器人,智能客服,甚至是推銷電話都可以做到以假亂真的程度。谷歌在2018年開發者大會上演示了一個預約理髮店的聊天機器人,語氣惟妙惟肖,表現相當令人驚豔。相信很多讀者都接到過人工智能的推銷電話,不去仔細分辨的話,根本不知道電話那頭只是個AI程序。破解方法其實也很簡單,問機器人一句“今天天氣挺好的,你覺得呢”,相信很多推銷電話就無法回答了。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E這是因爲在特定場景下,對話可以跳轉的狀態一般都是有限的,可能產生的話題分支,比起圍棋的可能性要少很多,因此,即便是窮舉所有的可能性,也不是不可做到的事情。如果提前設置好對話策略,加上語音合成技術,完全可以以假亂真,但一旦在開放域進行閒聊,對話的可能性幾乎是無限的,場景對話技術也就無能爲力了。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E所以,要想真正實現具備認知智能的虛擬生命,還需要很多的技術突破,尤其是目前還不能夠對人類的思維能力做到真正的理解,所以機器人就好比綠野仙蹤中的鐵皮人,還缺乏帶有靈魂和感情的那顆心。\u003Cstrong\u003E因此,受限於目前的技術能力,虛擬生命不可能一蹴而就,而是要分步驟不斷的突破技術難題。\u003C\u002Fstrong\u003E圖3給出了虛擬生命不同發展階段。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cdiv class=\"pgc-img\"\u003E\u003Cimg src=\"http:\u002F\u002Fp3.pstatp.com\u002Flarge\u002Fpgc-image\u002Fd0da822c6c2445b3add4ddc088162fb9\" img_width=\"1080\" img_height=\"571\" alt=\"認知智能的突圍:NLP、知識圖譜是AI下一個“掘金地”?\" inline=\"0\"\u003E\u003Cp class=\"pgc-img-caption\"\u003E圖3 虛擬生命發展階段\u003C\u002Fp\u003E\u003C\u002Fdiv\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E虛擬生命1.0,可以看做是聊天機器人的升級版本。本階段最重要的特點是單點技術的整合,並能作爲整體和人類進行交互。\u003C\u002Fstrong\u003E從功能上來看,仍然是被動交互爲主,但可以結合對用戶的認知,進行用戶畫像和主動推薦。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E我們目前正在處於虛擬生命的1.0階段。\u003C\u002Fstrong\u003E在這個階段,多輪對話、開放域對話、上下文理解、個性化問答、一致性和安全回覆等仍然是亟待解決的技術難題。同時,虛擬生命也需要找到可落地的場景,做好特定領域的技術突破。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E虛擬生命2.0,是目前正在努力前行的方向,\u003C\u002Fstrong\u003E在這個階段,多模態技術整合已完全成熟,虛擬生命形態更爲多樣性,具備基於海量數據的聯合推理及聯想,對自我和用戶都有了全面的認知,並可快速進行人格定製。實現這個階段可能需要3-5年。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E虛擬生命3.0,\u003C\u002Fstrong\u003E 初步達到強人工智能,具備超越人類的綜合感知能力,並擁有全面的推理、聯想和認知,具備自我意識,並能達到人類水平的自然交互。隨着技術的進步,我們期待在未來十年至三十年實現虛擬生命的3.0。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E本文後面的章節,就從虛擬生命1.0,也就是聊天機器人的角度,來闡述目前自然語言處理和知識圖譜的技術落地,以及如何實現基本的機器人認知能力。\u003C\u002Fstrong\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E這兩年,聊天機器人領域異常火熱,原因在於我們目前所處的時代需要一個語音交互入口。從上世紀80年代至今,我們已經經歷了四個技術時代,分別是PC時代,互聯網時代,移動互聯網時代和現在的AI時代。每一個時代均湧現了大量的科技成果,也出現了劃時代的產品和偉大的公司。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E其中,在PC時代,運算力改變了人類的生活,個人電腦和windows操作系統,成就了微軟和IBM兩個軟件和硬件的巨頭。在互聯網時代,連接顛覆一切,人們可以通過網絡隨時隨地進行信息交互,互聯網和搜索引擎造就了谷歌;在移動互聯網時代,技術帶來了兩大變革,一是數據利用效率的提升,導致服務發生了變化,人們可以隨時隨地享受即時服務,二是交互方式的改變,智能手機成爲了主要的入口級設備,最具有代表性的公司就是蘋果。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E當人們跨越到AI時代,微軟又提出對話即平臺(Conversation As A Platform)的理念,認爲語音交互是這個時代的入口,隨着硬件和軟件的成熟,人們可以採用最自然的交互方式-語音,和機器進行流暢對話,完成各種服務。也正是在這種背景之下,聊天機器人開始作爲入口級產品而大量湧現。而打造聊天機器人產品,不僅需要計算機視覺、聲學等技術,更進一步需要自然語言處理及知識圖譜技術。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Ch1 class=\"ql-align-center\"\u003E\u003Cstrong\u003E四、自然語言處理\u003C\u002Fstrong\u003E\u003C\u002Fh1\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E語言是主要以發聲爲基礎來傳遞信息的符號系統,是人類重要的交際工具和存在方式之一。作用於人與人的關係時,是表達相互反應的中介;作用於人和客觀世界的關係時,是認識事物的工具;作用於文化時,是文化信息的載體(來源:維基百科)。語言與邏輯相關,而人類的思維邏輯最爲完善。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E1957年喬姆斯基的第一部專著《句法結構》出版,提出了基於普遍語法的理論核心,認爲人腦有一種先天的特定結構或屬性,即語言習得機制,它是人類學會使用語言的內因。而埃弗雷特通過研究皮拉罕的部落之後,認爲是文化而不是遺傳決定了語言,並否認了喬姆斯基普遍語法中的“遞歸性假設”。自然語言處理,研究能實現人與計算機之間用自然語言進行有效通信的各種理論和方法,主要是計算機科學、語言學和數學的融合學科。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E通過圖4可以看出,自底向上,自然語言處理需要通過對字、詞、短語、句子、段落、篇章的分析,使得計算機能夠理解文本的意義。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cdiv class=\"pgc-img\"\u003E\u003Cimg src=\"http:\u002F\u002Fp3.pstatp.com\u002Flarge\u002Fpgc-image\u002Ffa9dcd8612cf4c57a29678565eb3a399\" img_width=\"1080\" img_height=\"597\" alt=\"認知智能的突圍:NLP、知識圖譜是AI下一個“掘金地”?\" inline=\"0\"\u003E\u003Cp class=\"pgc-img-caption\"\u003E圖4 自然語言技術體系\u003C\u002Fp\u003E\u003C\u002Fdiv\u003E\u003Cp class=\"ql-align-justify\"\u003E而在每一個層級上都包含大量的技術模塊,比如說在詞級別,需要做分詞、詞性標註、命名實體識別等。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E由於本文主要探討虛擬生命的相關技術,因此,在一個虛擬生命1.0框架(或者說聊天機器人)中,牽扯到的自然語言處理技術主要包括:自然語言理解,對話管理和自然語言生成。其中,自然語言理解是爲了分析句子的各項含義,包括情感、意圖、句型、主題等;而對話管理則是用於管理上下文、更新對話狀態、進行邏輯推理等;最後的自然語言生成,用於合成自然流暢的句子,並以合適的形式進行反饋。無論是微軟小冰、Siri、亞馬遜的Echo,還是公子小白、度祕、小愛同學,都是自然語言處理技術的典型的產品落地體現。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E比如和機器人對話的過程中,對於音樂話題的理解,就需要用到命名實體識別、實體鏈接等技術。\u003C\u002Fstrong\u003E舉一個簡單的例子,“我真的非常喜歡杰倫的雙截棍”,就需要判斷杰倫是一個人名,鏈接到知識庫中“周杰倫”這樣一個歌手實體,並且“雙截棍”是一個歌名而不是一種器械。同時,還可以進行情感判斷,是一個正面的“喜歡”的情感。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E傳統的自然語言處理技術,還是以統計學和機器學習爲主,同時需要用到大量的規則。近十年來,深度學習技術的興起,也帶來了自然語言處理技術的突破。這一切還需要從語言的表示開始說起。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E衆所周知,計算機擅長處理符號,因此,自然語言需要被轉化爲一個機器友好的形式,使得計算機能夠快速處理。一個很典型的表示方法是\u003Cstrong\u003E詞彙的獨熱(one-hot)表示\u003C\u002Fstrong\u003E,也就是相當於每個詞在詞彙表裏都有一個特定的位置。比如說有一個10000個詞的詞彙表,而“國王”是詞彙表裏的第500個詞,那麼“國王”就可以表示爲一個一維向量,只有第500個位置是1,其他9999個位置都是0。但這種表示方法的問題很多,對語義相近但組成不同的詞或句子如“國王”和“女王”,利用獨熱表示的向量內積,無法準確的判斷兩者之間的相似度。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E2013年,Tomas Mikolov等人在谷歌開發了一個基於神經網絡的詞嵌入(word embedding)學習方法Word2Vec,不但大大縮短了詞彙的表示向量的長度,而且能夠更好的體現語義信息。\u003C\u002Fstrong\u003E通過這種嵌入方法可以很好的解決“國王”-“男人”=“女王”-“女人”這類問題。感興趣的讀者可以參考互聯網上大量的關於詞嵌入的資料。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E計算機能夠快速處理自然語言之後,傳統的機器學習方法也進一步被深度學習所顛覆。相關算法在近年來的迭代速度非常快。\u003Cstrong\u003E以語言模型(Language Model)預訓練方法爲例,代表性方法有Transformer,ELMo,Open AI GPT,BERT,GPT2以及最新的XLNet。\u003C\u002Fstrong\u003E其中,Transformer於2017年6月被提出。ELMo的發表時間是2018年2月,刷新了當時所有的SOTA(State Of The Art)結果。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E不到4個月,Open AI在6月,基於Transformer發佈了GPT方法,刷新了9個SOTA結果。又過了4個月,橫空出世的BERT又刷新了11個SOTA結果。2019年2月,Open AI發佈的GPT2,包含15億參數,刷新了11項任務的SOTA結果。而2019年6月,CMU 與谷歌大腦提出了全新 XLNet,在 20 個任務上超過了 BERT 的表現,並在 18 個任務上取得了當前最佳效果。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E除了算法和算力的進步,還有一個重要的原因在於,\u003Cstrong\u003E以前的自然語言處理研究,更多的是監督學習,需要大量的標註數據,成本高且質量難以控制,而以BERT爲代表的深度學習方法,直接在無標註的文本上做出預訓練模型。\u003C\u002Fstrong\u003E在人類歷史上,無監督數據是海量的,也就代表着這些模型的提升空間還有很大。2019年7月11日,Google AI發表論文[5],就利用了驚人的250億平行句對的訓練樣本。其應用效果我們也拭目以待。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E從自然語言處理的理論發展來看,前景一片光明,但相比之下,聊天機器人產品的效果,卻被無數用戶所詬病。答非所問、響應延遲、誤喚醒等問題大大降低了用戶的滿意度。隨着2018年Facebook關閉其虛擬助手M,亞馬遜Echo也被爆出侵犯用戶隱私的問題,再加上聊天機器人實際使用效果遠低於大衆預期,整個行業也逐步走向低迷。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E一個很關鍵的原因在於,媒體上對於聊天機器人的宣傳,都在嘗試模仿人類的對話交互。而在目前的技術條件下是無法達到的。微軟亞洲研究院副院長周明博士曾經提到,語言智能可以看做是人工智能皇冠上的明珠。嘗試用技術模擬人類的真實對話,在開放領域就是個僞命題。因爲在人類的對話過程中,一句話中所表達出的信息,不只是文字本身,還包括世界觀、情緒、環境、上下文、語音、表情、對話者之間的關係等。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E比如說“今天天氣不錯”,在早晨擁擠的電梯中和同事說,在秋遊的過程中和驢友說,走在大街上的男女朋友之間說,在傾盆大雨中對同伴說,很可能代表完全不同的意思。在人類對話中需要考慮到的因素包括:說話者和聽者的靜態世界觀、動態情緒、兩者的關係,以及上下文和所處環境等,如圖5所示。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cdiv class=\"pgc-img\"\u003E\u003Cimg src=\"http:\u002F\u002Fp3.pstatp.com\u002Flarge\u002Fpgc-image\u002Fd0a166f8b2c5462b922f477c46c8cb73\" img_width=\"1080\" img_height=\"655\" alt=\"認知智能的突圍:NLP、知識圖譜是AI下一個“掘金地”?\" inline=\"0\"\u003E\u003Cp class=\"pgc-img-caption\"\u003E圖5 人類聊天中的要素\u003C\u002Fp\u003E\u003C\u002Fdiv\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E而且,以上這些都不是獨立因素,整合起來,才能真正反映一句話或者一個詞所蘊含的意思。這就是人類語言的奇妙之處。同時,人類在交互過程中,並不是等對方說完一句話才進行信息處理,而是隨着說出的每一個字,不斷的進行腦補,在對方說完之前就很可能瞭解到其所有的信息。再進一步,人類有很強的糾錯功能,在進行多輪交互的時候,能夠根據對方的反饋,修正自己的理解,達到雙方的信息同步。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E再進一步,在體驗模擬假說(Embodied Simulation Hypothesis)中[6],人類在進行語言理解的時候,會基於聽覺、視覺以及運動等體驗的模擬,來進行“腦補”。比如說當聽到“綿羊有沒有角”這個問題,我們會在腦海裏浮現出綿羊的形象,甚至聲音,再去判斷它頭上有沒有角。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E因此,在開放域的聊天機器人,寄希望於從一句話的文本理解其含義,這本身就是很不靠譜的一件事情。\u003C\u002Fstrong\u003E目前市場上大部分的聊天機器人,還僅是單通道的交互(語音或文本),離人類多模態交互的能力還相差甚遠。哪怕僅僅是語音識別,在不同的噪音條件下也會產生不同的錯誤率,對於文本的理解就更加雪上加霜了。更別談推理能力,僅僅通過自然語言處理技術也是無法進行解決的。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E那麼自然語言的生成模型是否可以解決問題呢?通過端到端的深度學習方法,我們可以做到句子的生成。但實際上,這種方法所生成的語句,還未能達到實用級別,因此本文不做深入討論。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E結合多模態識別和分析,是自然語言處理落地的新方向。\u003C\u002Fstrong\u003E舉例來說,要識別一句話“你太壞了”是撒嬌還是批評,如果將聲音特徵和表情特徵結合進來,那麼會很容易判斷。哈工大李海峯教授也曾給出過一個有趣的例子,對於“我沒有看見他拿了你的錢包“,重音位置不同,會導致不同的含義。當重音在”我“的時候,可能表示說話者沒看到,但有其他人看到。當重音在”錢包“的時候,可能表示被拿走的不是錢包,而是別的東西。當重音在”看見“的時候,可能表示說話者並沒看到,但有可能聽說了這個事情。因此,結合多模態的自然語言處理,會大大提升多輪對話中機器人的表現。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Ch1 class=\"ql-align-center\"\u003E\u003Cstrong\u003E五、知識圖譜\u003C\u002Fstrong\u003E\u003C\u002Fh1\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E在上一節中,我們也提到,自然語言處理技術很難解決推理問題。而推理是認知智能的重要組成部分。比如說對於問題“姚明的老婆的女兒的國籍是什麼?”,一個可行的解決方案,就是通過大規模百科知識圖譜來進行推理查詢。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E知識圖譜被認爲是從感知智能通往認知智能的重要基石。\u003C\u002Fstrong\u003E一個很簡單的原因就是,沒有知識的機器人不可能實現認知智能。圖靈獎獲得者,知識工程創始人Edward Feigenbaum曾經提到:“Knowledge is the power in AI system”。張鈸院士也提到,“沒有知識的AI不是真正的AI”。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E拿上一節提到的GPT-2算法來看,即使其文章續寫能力讓人讚歎,也只是再次證明了足夠大的神經網絡配合足夠多的訓練數據,就能夠產生強大的記憶能力。但邏輯和推理能力,仍然是無法從記憶能力中自然而然的出現的。學界和企業界都寄希望於知識圖譜解決知識互連和推理的問題。那麼什麼是知識圖譜?簡單來說,就是把知識用圖的形式組織起來。可能這樣說還不夠明白,我們舉例子分別說下什麼是知識,什麼是圖譜。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E所謂知識,是信息的抽象,舉一個簡單的例子來說,226.1釐米,229釐米,都是客觀存在的孤立的數據。此時,數據不具有任何的意義,僅表達一個事實存在。而“姚明臂展226.1釐米”, “姚明身高229釐米”,是事實型的陳述,屬於信息的範疇。對於知識而言,是在更高層面上的一種抽象和歸納,把姚明的身高、臂展,及姚明的其他屬性整合起來,就得到了對於姚明的一個認知,也可以進一步瞭解姚明的身高是比普通人更高的。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E維基百科給出的關於知識的定義是:知識是人類在實踐中認識客觀世界(包括人類自身)的成果,它包括事實、信息的描述或在教育和實踐中獲得的技能。知識是人類從各個途徑中獲得得經過提升總結與凝練的系統的認識。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E圖譜的英文是graph,直譯過來就是“圖”的意思。在圖論(數學的一個研究分支)中,圖(graph)表示一些事物(objects)與另一些事物之間相互連接的結構。一張圖通常由一些結點(vertices或nodes)和連接這些結點的邊(edge)組成。Sylvester在1878年首次提出了“圖”這一名詞[7]。如果我們把姚明相關的“知識”用“圖譜”構建起來,就是圖6所體現的內容。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cdiv class=\"pgc-img\"\u003E\u003Cimg src=\"http:\u002F\u002Fp3.pstatp.com\u002Flarge\u002Fpgc-image\u002Fb816029b5a0946eab0dae8fda7e74dc4\" img_width=\"410\" img_height=\"415\" alt=\"認知智能的突圍:NLP、知識圖譜是AI下一個“掘金地”?\" inline=\"0\"\u003E\u003Cp class=\"pgc-img-caption\"\u003E圖6 姚明的基本信息知識圖譜\u003C\u002Fp\u003E\u003C\u002Fdiv\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E知識圖譜是實現通用人工智能(Artificial General Intelligence)的重要基石。從感知到認知的跨越過程中,構建大規模高質量知識圖譜是一個重要環節,當人工智能可以通過更結構化的表示理解人類知識,並進行互聯,纔有可能讓機器真正實現推理、聯想等認知功能。而構建知識圖譜是一個系統工程,其整體的技術棧如圖7所示:\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cdiv class=\"pgc-img\"\u003E\u003Cimg src=\"http:\u002F\u002Fp1.pstatp.com\u002Flarge\u002Fpgc-image\u002F6684250335b04a5688638ea6488093ca\" img_width=\"1080\" img_height=\"604\" alt=\"認知智能的突圍:NLP、知識圖譜是AI下一個“掘金地”?\" inline=\"0\"\u003E\u003Cp class=\"pgc-img-caption\"\u003E圖7 知識圖譜體系架構\u003C\u002Fp\u003E\u003C\u002Fdiv\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E針對不同場景,知識圖譜的構建策略分爲自頂向下和自底向上兩種方法。\u003C\u002Fstrong\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E自頂向下\u003C\u002Fstrong\u003E的策略爲專家驅動,根據應用場景和領域,利用經驗知識人工爲知識圖譜定義數據模式,在定義本體的過程中,首先從最頂層的概念開始,然後逐步進行細化,形成結構良好的分類學層次結構;在定義好數據模式後,再將實體逐個對應到概念中。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E自底向上\u003C\u002Fstrong\u003E的策略爲數據驅動,從數據源開始,針對不同類型的數據,對其包含的實體和知識進行歸納組織,形成底層的概念,然後逐步往上抽象,形成上層的概念,並對應到具體的應用場景中。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E知識圖譜可以輔助各種智能場景下的應用。谷歌在2012年最早提出“Knowledge Graph”的概念,並將知識圖譜用到搜索中,使得“搜索能直接通往答案”。知識圖譜還能輔助智能問答、決策推理等應用場景。圖8給出的是使用知識圖譜結合自然語言處理進行問答的案例。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cdiv class=\"pgc-img\"\u003E\u003Cimg src=\"http:\u002F\u002Fp9.pstatp.com\u002Flarge\u002Fpgc-image\u002F4279344558ae4855a290e2861663a043\" img_width=\"1080\" img_height=\"574\" alt=\"認知智能的突圍:NLP、知識圖譜是AI下一個“掘金地”?\" inline=\"0\"\u003E\u003Cp class=\"pgc-img-caption\"\u003E圖8 知識圖譜輔助智能問答\u003C\u002Fp\u003E\u003C\u002Fdiv\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cstrong\u003E知識圖譜讓機器人擁有了知識,也讓我們看到了實現認知智能的希望。但在目前的技術條件下,還有很多問題需要解決。\u003C\u002Fstrong\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E首先,知識的覆蓋面不全。\u003C\u002Fstrong\u003E目前的知識圖譜,僅僅涵蓋了人類知識的極小的一部分。由於構建較爲複雜,人類歷史上海量自然語言文本中的知識,很大部分並沒有被結構化到知識圖譜中。即便是有了半自動的抽取方法,常識知識也很難從文本中得到。\u003Cstrong\u003E因此,常識推理也是目前知識圖譜領域很難解決的一個問題。\u003C\u002Fstrong\u003E例如對於“雞蛋放到籃子裏,是雞蛋大還是籃子大”,“人看見老虎要不要跑”這類問題,通過百科知識圖譜就很難解決。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E其次,知識圖譜體系的標準化還不夠完善。\u003C\u002Fstrong\u003E知識圖譜體系稱爲“schema”。通俗來講,schema是骨架,而知識圖譜是血肉。有了schema,我們可以更好的做推理和聯想。例如,樹是一種植物,而柳樹是樹的一種實例化,可以推斷出“柳樹是植物”。一個簡單的schema如圖9所示。不同領域schema的建立通常會有所區別,不同知識圖譜之間的schema也會有差異。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cdiv class=\"pgc-img\"\u003E\u003Cimg src=\"http:\u002F\u002Fp1.pstatp.com\u002Flarge\u002Fpgc-image\u002Fec7cef7086f54d419a14dd0f584816d2\" img_width=\"1080\" img_height=\"467\" alt=\"認知智能的突圍:NLP、知識圖譜是AI下一個“掘金地”?\" inline=\"0\"\u003E\u003Cp class=\"pgc-img-caption\"\u003E圖9 知識圖譜schema示例\u003C\u002Fp\u003E\u003C\u002Fdiv\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E2011年,Google、Microsoft和Yahoo!三大巨頭推出了一個schema的規範體系:Schema.org,這個規範體系是一個消費驅動的嘗試,其指導數據發佈者和網站構建者在網頁中嵌入併發布結構化數據,對應的回報是在用戶在使用特定關鍵字搜索時,可以免費爲這些網頁提升排名,從而起到搜索引擎優化(SEO)的作用。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E它的核心schema由專家自頂向下定義,截止目前,這個詞彙本體已經包含600多個類和900多個關係,覆蓋範圍包括:個人、組織機構、地點、時間、醫療、商品等。通過SEO的明確價值導向,得到了廣泛應用,目前全互聯網有超過30%的網頁增加了基於schema.org的數據體系的數據標註。在國內,相對應的是由OpenKG組織牽頭的CnSchema(cnschema.org)。在相同的規範體系下,不同知識圖譜之間可以做到更好的融合和知識遷移。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E最後,構建知識圖譜的成本仍然較高。\u003C\u002Fstrong\u003EHeiko Paulheim在其文章《How much is a Triple? Estimating the Cost of Knowledge Graph Creation》中,給出了幾個典型的知識圖譜的構建成本。其中,上世紀80年代開始的也是最早的知識圖譜項目CYC,平均構建一條陳述句和斷言的成本是5.71美元,而隨着自然語言處理和機器學習技術的進步,DBpedia構建每一條的成本降低到了1.85美分。即便如此,在真正工程化落地的時候,牽扯到多源數據的清洗整合,一個知識圖譜項目的成本還是居高不下。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Ch1 class=\"ql-align-center\"\u003E\u003Cstrong\u003E六、重新審視認知科學\u003C\u002Fstrong\u003E\u003C\u002Fh1\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E從感知智能通向認知智能的道路中,自然語言處理與知識圖譜技術起到了重要作用。但不可忽視的是,認知智能乃至通用人工智能的實現,是需要多學科的共同進步才能完成的。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E其中,腦科學是一個非常重要的研究領域。迄今爲止,我們在創造智能機器的過程中,很大程度上還是在仿造現有的生命體。因此,對人腦的研究也提升了我們對認知智能的理解。人腦是由千億級神經細胞,通過千萬億級的突觸連接而形成的神經網絡,不同的區域負責不同的功能。發達的大腦皮層也正是人類區別於動物的主要特點。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E目前主流的深度學習技術,正是對人腦的一定程度的模仿。李航博士在其《智能與計算》一文中提到,雖然腦科學研究取得了一定的進展,但離探明人腦的工作機理還相差甚遠。就能耗而言,前文中所提到的打敗李世石的AlphaGo(擁有1202個CPU,176個GPU,按照每個CPU的功率爲100W,每個GPU的功率爲200W進行推算得到此結果。),每小時的能量消耗接近15萬千卡,而一個成年人每天的能量消耗也僅僅2500千卡。更何況人在下棋之外還可以做很多其他的事情。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E另外還需提及的一個學科是認知科學,其誕生於上世紀50年代的“認知革命”,包括哲學、認知心理學、計算機科學、語言學、人類學和神經科學六個主要領域。其代表綱領爲“認知即計算“,通過心理符號表徵和對錶徵結構的操作程序來研究一般的思維和智能。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E在今年五月底《Nature Human Behaviour》的論文《What happened to cognitive science?》中,美國加州大學聖地亞哥分校認知科學系具身認知實驗室主任(Director of the Embodied Cognition Laboratory)Rafael Núñez等幾位專家,對半個世紀以來認知科學的發展進行了一個概括和討論。圖10給出了六個學科中在《認知科學》上論文數量的對比。可以看出,認知心理學佔比超過了60%,計算機科學、神經科學和語言學分別佔比10%左右,而人類學和哲學卻幾乎爲零。因此,在認知科學領域,並沒有形成一個完整統一的學科,而是認知心理學的一枝獨秀。 \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E但大量的里程碑式的成果仍然是多學科融合的產物。上世紀60年代興起的心智計算理論(Computational Theory of Mind),是由認知科學家、腦科學家和哲學家共同提出和推進的。其認爲“心智是計算系統,思考是符號操作”。心智計算理論在近二十年受到了前文提到的“體驗認知理論”的挑戰,而體驗認知理論,也融合了認知科學、腦科學和哲學的研究成果。近十年來,認知神經科學和腦科學結合,通過先進的功能核磁共振技術,也爲大腦如何產生思想提供了新的實驗發現。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cdiv class=\"pgc-img\"\u003E\u003Cimg src=\"http:\u002F\u002Fp3.pstatp.com\u002Flarge\u002Fpgc-image\u002Fd6763962d2754b82ad413f9ff49297e7\" img_width=\"1080\" img_height=\"1037\" alt=\"認知智能的突圍:NLP、知識圖譜是AI下一個“掘金地”?\" inline=\"0\"\u003E\u003Cp class=\"pgc-img-caption\"\u003E圖10 《認知科學》領域論文數量對比\u003C\u002Fp\u003E\u003C\u002Fdiv\u003E\u003Cp class=\"ql-align-center\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E多學科的融合和發展,讓認知智能不斷進步。在今年7月,我們看到了一項令人激動的技術落地。美國神經科技公司Neuralink的創始人埃隆·馬斯克(Elon Musk)16日表示,“腦機接口”(Brain-Computer Interface, BCI)研究取得新進展。公司研發出一種比人類頭髮絲還細的“線”,可植入人類大腦中,檢測神經元活動。目前,研究人員已在猴子身上進行了實驗,可以從1500個電極讀取信息,讓猴子能用大腦控制電腦。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Ch1 class=\"ql-align-center\"\u003E\u003Cstrong\u003E七、結語\u003C\u002Fstrong\u003E\u003C\u002Fh1\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cbr\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E認知智能的突破,一定不是由單個技術所完成,而是需要結合多種不同的技術的發展。正如本文中所提到的,自然語言處理與知識圖譜結合可以實現一定程度的推理,而知識圖譜和深度學習結合可以實現一定程度的可解釋性,自然語言處理和深度學習結合,誕生了BERT等強大的語言模型。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E在技術之外,在實現認知智能的過程中,還需要考慮一些人文因素,例如如何讓機器人具備情感,如何賦予機器人生存的意義(或目標),這些都是目前無法實現的事情。自然語言處理與知識圖譜技術,開啓了認知智能的大門,但還需要科學家和工程師們的共同努力,才能真正摘得人工智能皇冠上的明珠。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E最後以孫中山先生的名言作爲本文的結語:“革命尚未成功,同志任需努力。”\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E參考文獻\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E[1] N. Brown, Superhuman AI for Multiplayer Poker, Science, 2019.\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E[2] W. Xiong, L. Wu, F. Alleva, J. Droppo, X. Huang, A. Stolcke, The Microsoft 2017 Conversational Speech Recognition System, Microsoft Technical Report MSR-TR-2017-39, arXiv:1708.06073v2, 2017.\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E[3] K. He, X. Zhang, S. Ren, J. Sun. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, arXiv:1502.01852v1, 2015.\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E[4] A. Radford, K. Narasimhan, T. Salimans and I. Sutskever. Improving Language Understanding by Generative Pre-training, 2018.\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E[5] N. Arivazhagan et. al., Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges, arXiv:1907.05019, 2019.\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E[6]Y. Xu, Y. He and Y. Bi. A Tri-network Model of Human Semantic Processing. Frontiers in psychology, 2017.\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E[7] J. J. Sylvester. On an Application of the New Atomic Theory to the Graphical Representation of the Invariants and Covariants of Binary Quantics, with Three Appendices, Pure and Applied, 1 (1): 64–90, 1878.\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E \u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E附相關鏈接:\u003C\u002Fstrong\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E(1)英國帝國理工學院和劍橋大學研究人員共同組織的AI競賽\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003Ehttp:\u002F\u002Fwww.animalaiolympics.com\u002F\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E(2)ImageNet評測任務\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003Ehttps:\u002F\u002Fwww.kaggle.com\u002Fc\u002Fimagenet-object-localization-challenge\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E(3)WaveNet語音合成系統\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003Ehttps:\u002F\u002Fdeepmind.com\u002Fblog\u002Fwavenet-generative-model-raw-audio\u002F\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E(4)SQuAD閱讀理解競賽\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003Ehttp:\u002F\u002Fstanford-qa.com\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E(5)Transformer論文:\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003Ehttps:\u002F\u002Farxiv.org\u002Fabs\u002F1706.03762\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E(6)ELMo論文\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003Ehttps:\u002F\u002Farxiv.org\u002Fabs\u002F1802.05365\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E(7)BERT論文\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003Ehttps:\u002F\u002Farxiv.org\u002Fabs\u002F1810.04805\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E(8)XLNet論文\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003Ehttps:\u002F\u002Farxiv.org\u002Fabs\u002F1906.08237\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E【作者簡介】劭浩,上海瓦歌智能科技有限公司總經理,狗尾草科技人工智能研究院院長。日本國立九州大學工學博士。現任上海瓦歌智能科技有限公司總經理,深圳狗尾草智能科技有限公司合夥人,人工智能研究院院長,帶領團隊打造了聊天機器人產品“公子小白”及AI虛擬生命產品“琥珀•虛顏”的交互引擎。上海市靜安區首屆優秀人才,兼任中國中文信息學會青年工作委員會委員,中國計算機學會YOCSEF上海學術委員會委員。研究方向爲人工智能,共發表論文40餘篇,出版了業內第一本聊天機器人著作,主持多項國家級及省部級項目,曾在聯合國、WTO、亞利桑那州立大學、香港城市大學等任訪問學者。\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cstrong\u003E相約 2019 AI ProCon:劭浩還將於 9 月 7 日 出席 2019 AI開發者大會,與你共同探討 NLP 技術落地與前沿研究!\u003C\u002Fstrong\u003E\u003C\u002Fp\u003E\u003Cp class=\"ql-align-justify\"\u003E\u003Cem\u003E(*本文爲 AI科技大本營約稿文章,轉載請聯繫微信 1092722531)\u003C\u002Fem\u003E\u003C\u002Fp\u003E\u003C\u002Fdiv\u003E"'.slice(6, -6), groupId: '6719416788938932739