用數據分析網絡暴力有多可怕
摘要:df = db['user_message'].str.split(' ', expand=True)。df['time'] = db['date'].str.split(':', expand=True)[0]。
這應該是一篇拖得蠻久的文章。

故事源於潘長江在某個綜藝節目上沒認出蔡徐坤,然後潘長江老師的微博評論區就炸鍋了。
最後搞得兩邊都多多少少受到網絡暴力的影響。
直至今日,這條微博的評論區還在更新着。
不得不說微博的黑粉,強行帶節奏,真的很可怕。
還有比如自己一直關注的英雄聯盟。
上週王校長也是被帶了一波節奏,源於姿態退役後又復出的一條微博。

本來是一句很普通的調侃回覆,「離辣個傳奇adc的迴歸,還遠嗎?[二哈]」。
然後就有人開始帶王校長的節奏,直接把王校長給惹毛了。
上面這些事情,對於我這個喫瓜羣衆,也沒什麼好說的。
只是希望以後能沒有那麼多無聊的人去帶節奏,強行給他人帶來壓力。
本次通過獲取潘長江老師那條微博的評論用戶信息,來分析一波。
一共是獲取了3天的評論,共14萬條。
/ 01 / 前期工作
微博評論信息獲取就不細說,之前也講過了。
這裏提一下用戶信息獲取,同樣從移動端下手。

主要是獲取用戶的暱稱、性別、地區、微博數、關注數、粉絲數。
另外本次的數據存儲採用MySQL數據庫。
創建數據庫。
import pymysql
db = pymysql.connect(host='127.0.0.1', user='root', password='774110919', port=3306)
cursor = db.cursor()
cursor.execute("CREATE DATABASE weibo DEFAULT CHARACTER SET utf8mb4")
db.close()
創建表格以及設置字段信息。
import pymysql
db = pymysql.connect(host='127.0.0.1', user='root', password='774110919', port=3306, db='weibo')
cursor = db.cursor()
sql = 'CREATE TABLE IF NOT EXISTS comments (user_id VARCHAR(255) NOT NULL, user_message VARCHAR(255) NOT NULL, weibo_message VARCHAR(255) NOT NULL, comment VARCHAR(255) NOT NULL, praise VARCHAR(255) NOT NULL, date VARCHAR(255) NOT NULL, PRIMARY KEY (comment, date))'
cursor.execute(sql)
db.close()
/ 02 / 數據獲取
具體代碼如下。
from copyheaders import headers_raw_to_dict
from bs4 import BeautifulSoup
import requests
import pymysql
import re
headers = b"""
accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
accept-encoding:gzip, deflate, br
accept-language:zh-CN,zh;q=0.9
cache-control:max-age=0
cookie:你的參數
upgrade-insecure-requests:1
user-agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
"""
# 將請求頭字符串轉化爲字典
headers = headers_raw_to_dict(headers)
def to_mysql(data):
"""
信息寫入mysql
"""
table = 'comments'
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
db = pymysql.connect(host='localhost', user='root', password='774110919', port=3306, db='weibo')
cursor = db.cursor()
sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=table, keys=keys, values=values)
try:
if cursor.execute(sql, tuple(data.values())):
print("Successful")
db.commit()
except:
print('Failed')
db.rollback()
db.close()
def get_user(user_id):
"""
獲取用戶信息
"""
try:
url_user = 'https://weibo.cn' + str(user_id)
response_user = requests.get(url=url_user, headers=headers)
soup_user = BeautifulSoup(response_user.text, 'html.parser')
# 用戶信息
re_1 = soup_user.find_all(class_='ut')
user_message = re_1[0].find(class_='ctt').get_text()
# 微博信息
re_2 = soup_user.find_all(class_='tip2')
weibo_message = re_2[0].get_text()
return (user_message, weibo_message)
except:
return ('未知', '未知')
def get_message():
# 第一頁有熱門評論,拿取信息較麻煩,這裏偷個懶~
for i in range(2, 20000):
data = {}
print('第------------' + str(i) + '------------頁')
# 請求網址
url = 'https://weibo.cn/comment/Hl2O21Xw1?uid=1732460543&rl=0&page=' + str(i)
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 評論信息
comments = soup.find_all(class_='ctt')
# 點贊數
praises = soup.find_all(class_='cc')
# 評論時間
date = soup.find_all(class_='ct')
# 獲取用戶名
name = re.findall('id="C_.*?href="/.*?">(.*?)</a>', html)
# 獲取用戶ID
user_ids = re.findall('id="C_.*?href="(.*?)">(.*?)</a>', html)
for j in range(len(name)):
# 用戶ID
user_id = user_ids[j][0]
(user_message, weibo_message) = get_user(user_id)
data['user_id'] = " ".join(user_id.split())
data['user_message'] = " ".join(user_message.split())
data['weibo_message'] = " ".join(weibo_message.split())
data['comment'] = " ".join(comments[j].get_text().split())
data['praise'] = " ".join(praises[j * 2].get_text().split())
data['date'] = " ".join(date[j].get_text().split())
print(data)
# 寫入數據庫中
to_mysql(data)
if __name__ == '__main__':
get_message()
最後成功獲取評論信息。

3天14萬條評論,着實可怕。
有時我不禁在想,到底是誰天天會那麼無聊去刷評論。
職業黑粉,職業水軍嗎?好像還真的有。
/ 03 / 數據清洗
清洗代碼如下。
import pandas as pd
import pymysql
# 設置列名與數據對齊
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
# 顯示10列
pd.set_option('display.max_columns', 10)
# 顯示10行
pd.set_option('display.max_rows', 10)
# 設置顯示寬度爲500,這樣就不會在IDE中換行了
pd.set_option('display.width', 2000)
# 讀取數據
conn = pymysql.connect(host='localhost', user='root', password='774110919', port=3306, db='weibo', charset='utf8mb4')
cursor = conn.cursor()
sql = "select * from comments"
db = pd.read_sql(sql, conn)
# 清洗數據
df = db['user_message'].str.split(' ', expand=True)
# 用戶名
df['name'] = df[0]
# 性別及地區
df1 = df[1].str.split('/', expand=True)
df['gender'] = df1[0]
df['province'] = df1[1]
# 用戶ID
df['id'] = db['user_id']
# 評論信息
df['comment'] = db['comment']
# 點贊數
df['praise'] = db['praise'].str.extract('(\d+)').astype("int")
# 微博數,關注數,粉絲數
df2 = db['weibo_message'].str.split(' ', expand=True)
df2 = df2[df2[0] != '未知']
df['tweeting'] = df2[0].str.extract('(\d+)').astype("int")
df['follows'] = df2[1].str.extract('(\d+)').astype("int")
df['followers'] = df2[2].str.extract('(\d+)').astype("int")
# 評論時間
df['time'] = db['date'].str.split(':', expand=True)[0]
df['time'] = pd.Series([i+'時' for i in df['time']])
df['day'] = df['time'].str.split(' ', expand=True)[0]
# 去除無用信息
df = df.ix[:, 3:]
df = df[df['name'] != '未知']
df = df[df['time'].str.contains("日")]
# 隨機輸出10行數據
print(df.sample(10))
輸出數據。

隨機輸出十條,就大致能看出評論區是什麼畫風了。
/ 04 / 數據可視化
01 評論用戶性別情況
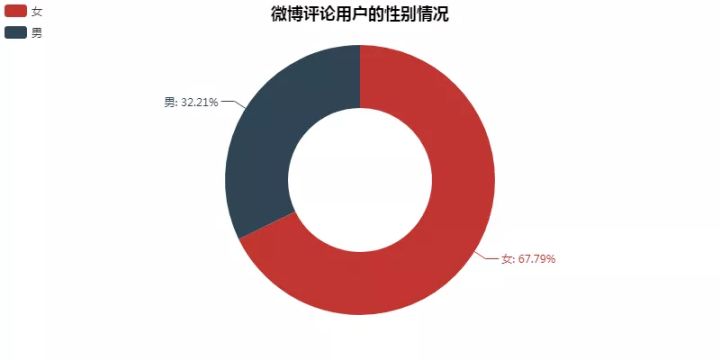

通過用戶ID對數據去重後,剩下約10萬+用戶。
第一張圖爲所有用戶的性別情況,其中男性3萬+,女性7萬+。
這確實也符合蔡徐坤的粉絲羣體。
第二張圖是因爲之前看到「Alfred數據室」對於蔡徐坤粉絲羣體的分析。
提到了很多蔡徐坤的粉絲喜歡用帶有「坤、蔡、葵、kun」的暱稱。
所以將暱稱包含這些字的用戶提取出來。
果不其然,女性1.2萬+,男性900+,更加符合了蔡徐坤的粉絲羣體。
可視化代碼如下。
from pyecharts import Pie, Map, Line
def create_gender(df):
# 全部用戶
# df = df.drop_duplicates('id')
# 包含關鍵字用戶
df = df[df['name'].str.contains("坤|蔡|葵|kun")].drop_duplicates('id')
# 分組彙總
gender_message = df.groupby(['gender'])
gender_com = gender_message['gender'].agg(['count'])
gender_com.reset_index(inplace=True)
# 生成餅圖
attr = gender_com['gender']
v1 = gender_com['count']
# pie = Pie("微博評論用戶的性別情況", title_pos='center', title_top=0)
# pie.add("", attr, v1, radius=[40, 75], label_text_color=None, is_label_show=True, legend_orient="vertical", legend_pos="left", legend_top="%10")
# pie.render("微博評論用戶的性別情況.html")
pie = Pie("微博評論用戶的性別情況(暱稱包含關鍵字)", title_pos='center', title_top=0)
pie.add("", attr, v1, radius=[40, 75], label_text_color=None, is_label_show=True, legend_orient="vertical", legend_pos="left", legend_top="%10")
pie.render("微博評論用戶的性別情況(暱稱包含關鍵字).html")
02 評論用戶區域分佈

廣東以8000+的評論用戶居於首位,隨後則是北京、山東,江蘇,浙江,四川。
這裏也與之前網易雲音樂評論用戶的分佈有點相似。
更加能說明這幾個地方的網民不少。
可視化代碼如下。
def create_map(df):
# 全部用戶
df = df.drop_duplicates('id')
# 分組彙總
loc_message = df.groupby(['province'])
loc_com = loc_message['province'].agg(['count'])
loc_com.reset_index(inplace=True)
# 繪製地圖
value = [i for i in loc_com['count']]
attr = [i for i in loc_com['province']]
map = Map("微博評論用戶的地區分佈圖", title_pos='center', title_top=0)
map.add("", attr, value, maptype="china", is_visualmap=True, visual_text_color="#000", is_map_symbol_show=False, visual_range=[0, 7000])
map.render('微博評論用戶的地區分佈圖.html')
03 評論用戶關注數分佈
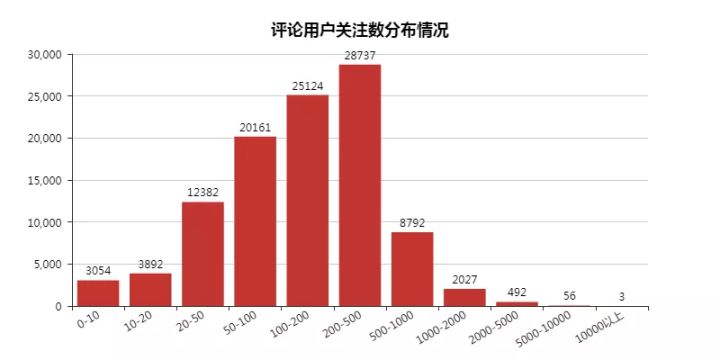
整體上符合常態,不過我也很好奇那些關注上千的用戶,是什麼樣的一個存在。
可視化代碼如下。
def create_follows(df):
"""
生成評論用戶關注數情況
"""
df = df.drop_duplicates('id')
follows = df['follows']
bins = [0, 10, 20, 50, 100, 200, 500, 1000, 2000, 5000, 10000, 20000]
level = ['0-10', '10-20', '20-50', '50-100', '100-200', '200-500', '500-1000', '1000-2000', '2000-5000', '5000-10000', '10000以上']
len_stage = pd.cut(follows, bins=bins, labels=level).value_counts().sort_index()
# 生成柱狀圖
attr = len_stage.index
v1 = len_stage.values
bar = Bar("評論用戶關注數分佈情況", title_pos='center', title_top='18', width=800, height=400)
bar.add("", attr, v1, is_stack=True, is_label_show=True, xaxis_interval=0, xaxis_rotate=30)
bar.render("評論用戶關注數分佈情況.html")
04 評論用戶粉絲數分佈

這裏發現粉絲數爲「0-10」的用戶不少,估摸着應該是水軍在作怪了。
粉絲數爲「50-100」的用戶最多。
可視化代碼如下。
def create_follows(df):
"""
生成評論用戶關注數情況
"""
df = df.drop_duplicates('id')
follows = df['follows']
bins = [0, 10, 20, 50, 100, 200, 500, 1000, 2000, 5000, 10000, 20000]
level = ['0-10', '10-20', '20-50', '50-100', '100-200', '200-500', '500-1000', '1000-2000', '2000-5000', '5000-10000', '10000以上']
len_stage = pd.cut(follows, bins=bins, labels=level).value_counts().sort_index()
# 生成柱狀圖
attr = len_stage.index
v1 = len_stage.values
bar = Bar("評論用戶關注數分佈情況", title_pos='center', title_top='18', width=800, height=400)
bar.add("", attr, v1, is_stack=True, is_label_show=True, xaxis_interval=0, xaxis_rotate=30)
bar.render("評論用戶關注數分佈情況.html")
05 評論時間分佈
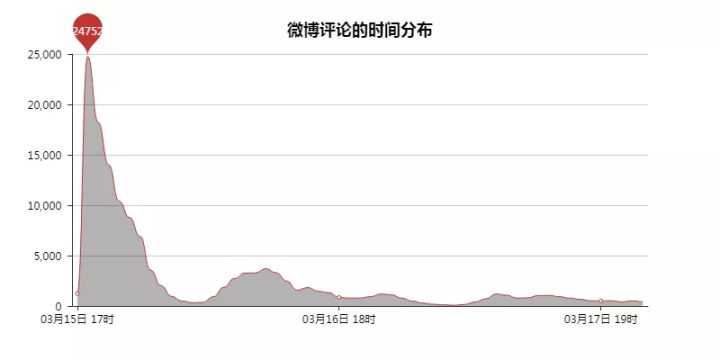
潘老師是在17時發出微博的,但是那時並沒有大量的評論出現,那個小時一共有1237條評論。
直到蔡徐坤在18時評論後,微博的評論一下就上去了,24752條。
而且目前一半的評論都是在蔡徐坤的回覆底下評論,點贊數多的也大多都在其中。
不得不說蔡徐坤的粉絲力量真大,可怕可怕~
可視化代碼如下。
def creat_date(df):
# 分組彙總
date_message = df.groupby(['time'])
date_com = date_message['time'].agg(['count'])
date_com.reset_index(inplace=True)
# 繪製走勢圖
attr = date_com['time']
v1 = date_com['count']
line = Line("微博評論的時間分佈", title_pos='center', title_top='18', width=800, height=400)
line.add("", attr, v1, is_smooth=True, is_fill=True, area_color="#000", xaxis_interval=24, is_xaxislabel_align=True, xaxis_min="dataMin", area_opacity=0.3, mark_point=["max"], mark_point_symbol="pin", mark_point_symbolsize=55)
line.render("微博評論的時間分佈.html")
06 評論詞雲

大體上言論還算好,沒有很偏激。
可視化代碼如下。
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import jieba
def create_wordcloud(df):
"""
生成評論詞雲
"""
words = pd.read_csv('chineseStopWords.txt', encoding='gbk', sep='\t', names=['stopword'])
# 分詞
text = ''
for line in df['comment']:
line = line.split(':')[-1]
text += ' '.join(jieba.cut(str(line), cut_all=False))
# 停用詞
stopwords = set('')
stopwords.update(words['stopword'])
backgroud_Image = plt.imread('article.jpg')
wc = WordCloud(
background_color='white',
mask=backgroud_Image,
font_path='C:\Windows\Fonts\華康儷金黑W8.TTF',
max_words=2000,
max_font_size=150,
min_font_size=15,
prefer_horizontal=1,
random_state=50,
stopwords=stopwords
)
wc.generate_from_text(text)
img_colors = ImageColorGenerator(backgroud_Image)
wc.recolor(color_func=img_colors)
# 高詞頻詞語
process_word = WordCloud.process_text(wc, text)
sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True)
print(sort[:50])
plt.imshow(wc)
plt.axis('off')
wc.to_file("微博評論詞雲.jpg")
print('生成詞雲成功!')
/ 05/ 總結
最後,照例來扒一扒哪位用戶評論最多。
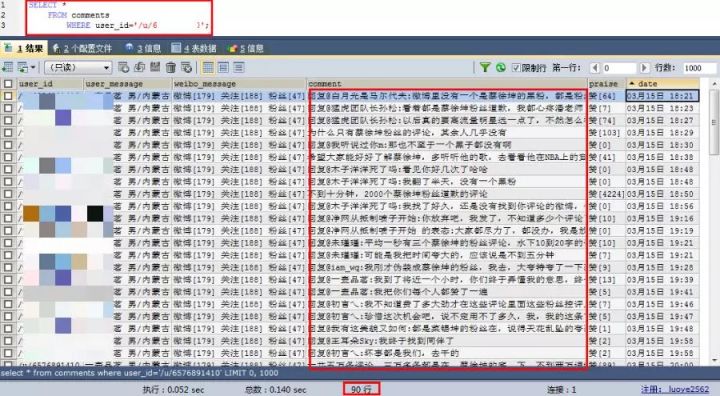
這位男性用戶,一共評論了90條,居於首位。
評論畫風有點迷,是來攪局的嗎?
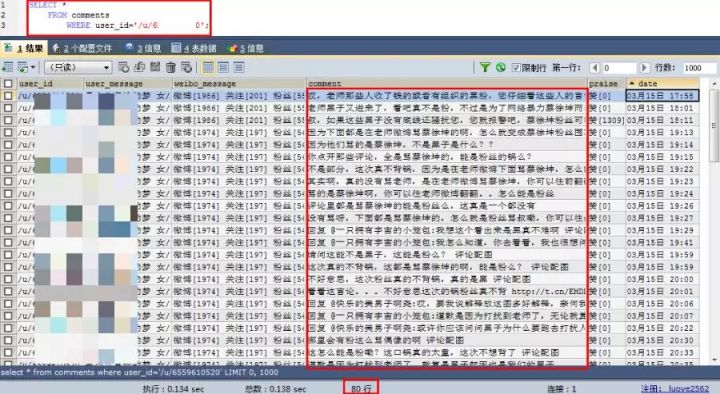
這位女性用戶,一共評論了80條。
大部分內容都是圍繞黑粉去說的。
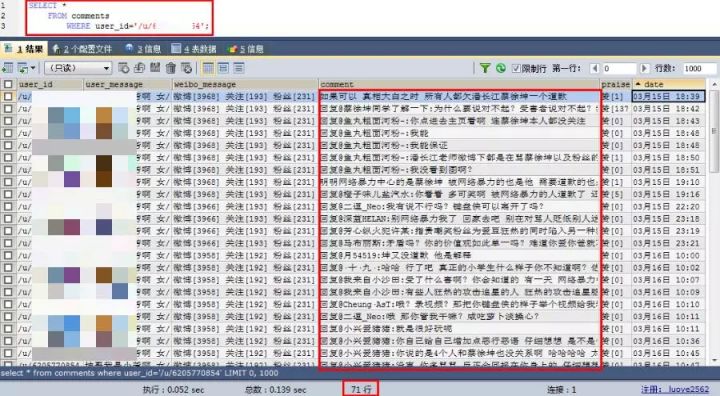
這位女性用戶,一共評論了71條。
瘋狂與評論區互動...
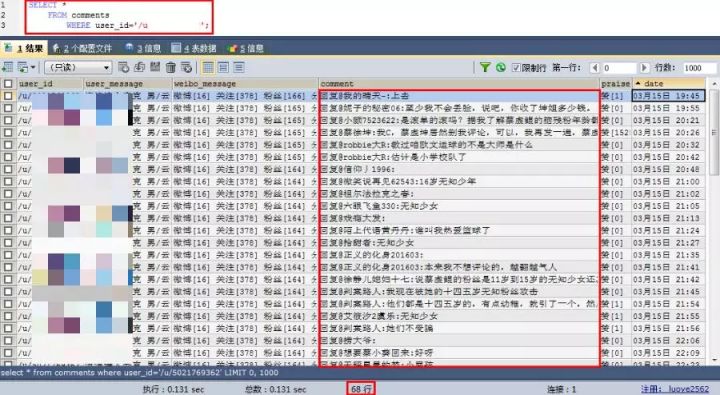
這位男性用戶,一共評論了68條。
也在與評論區互動,不過大多數評論情感傾向都是偏消極的。
觀察了評論數最多的10名用戶,發現其中男性用戶的評論都是偏負面的,女性評論都是正面的。
好了,作爲一名喫瓜羣衆,我是看看就好,也就不發表什麼言論了。
下面這段內容摘自公衆號「老馬小刀」,個人感覺有理。

萬水千山總是情,點個「在看」行不行。
本文來源法納斯特
本文版權歸原作者所有,內容爲作者個人觀點,轉載目的在於傳遞更多信息,如涉及作品內容、版權等問題,可聯繫本站刪除,謝謝。
更多交流諮詢:18080942131 (同微信 加好友備註:搜狐)。