北大新成果!首次成功地將CNN解碼器用於代碼生成|論文+代碼
乾明 發自 凹非寺
量子位 報道 | 公衆號 QbitAI
想象一下。
直接說你想幹什麼,就能生成相應的代碼,會是多麼“功德無量”一件事。
最直接受益的,就是程序員羣體。
再也不用飽受“996”的折磨,也不用摸着不斷後退的髮際線而黯然神傷。

現在,這一天又近了一些。
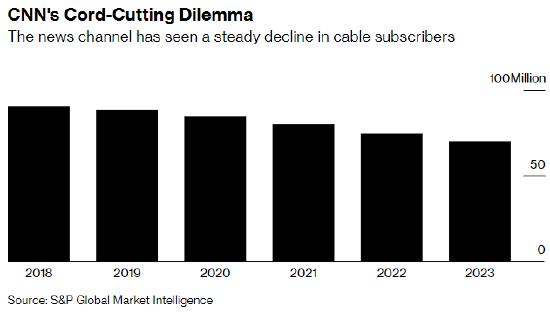
最近,有一篇論文提出了一種基於語法的結構化CNN代碼生成器,用《爐石傳說》(HearthStone)基準數據集進行實驗的結果表明:
準確性上明顯優於以前最先進的方法5個百分點。

這篇論文目前已經被AAAI 2019收錄。作者在論文中表示,他們是第一個成功地將CNN解碼器用於代碼生成的團隊。
那麼問題來了:
將CNN解碼器用到代碼生成,與之前的方法相比,到底有什麼不同?
他們的模型又有什麼特殊之處?效果到底好在哪?
下面,我們就來一一回答這些問題。
用CNN解碼器生成代碼的優勢
基於自然語言描述生成代碼,是挺難的一件事。
現在,通常用循環神經網絡( RNN)進行序列生成,生成一首詩、進行機器翻譯,都沒問題。
但用在生成代碼上,“麻煩”就來了。
程序中有很多結構化的信息,對程序建模很重要,但傳統的Seq2Seq神經網絡,並沒有明確對程序結構進行建模。就比如下面這個Python的抽象語法樹(AST)。

其中,n3和n6兩個節點應該作爲父子節點緊密交互,但如果使用傳統的Seq2Seq方法,就會導致他們“父子離散”,彼此遠離。
爲了解決這個問題,很多人都開始想各種辦法。其中一個關鍵方法就是用卷積神經網絡(CNN),畢竟人家效率高,訓練也簡單。
這篇論文,就是一個代表。而且是第一個成功地將CNN解碼器用於代碼生成的,頗具分水嶺意義。
在論文中,作者也介紹說,這比原來的RNN強多了。最主要的一點就是:
輸入的程序一半都比自然語言句子長得多,就算RNN有LSTM(long short-term memory)的加持,也會一直受到依賴性問題的困擾。
而CNN就不一樣了,可以通過滑動窗口(slide window)有效地捕捉不同區域的特徵。
那,這個模型是怎麼設計的呢?
模型設計
論文中介紹的CNN,是一種基於語法的結構化CNN。模型會根據AST的語法結構規則生成代碼,而且還能預測語法規則的順序,最終構建整個程序。
那,他們是如何預測語法規則的呢?主要基於三種類型的信息:
指定要生成的程序的源序列、之前預測的語法規則和已經生成的部分AST。
第一種很好理解,是編碼器的輸入。後兩種的任務,就是使解碼器能夠自迴歸(autoregressiveness),並且解碼器也以編碼器爲條件。
爲了讓這個結構化CNN更適合於代碼生成,他們還設計了幾個不同的組件:
第一,基於樹的卷積思想,在AST結構上應用滑動窗口。然後,設計另一個CNN模塊對部分AST中的節點進行前序遍歷。這兩種類型的CNN不僅捕獲序列中的“鄰居”信息,還捕獲樹結構中的“鄰居”信息。
第二,將另一個CNN模塊應用於要生成的節點的祖先,讓網絡知道,在某個步驟中在哪裏生成。從而增強“自迴歸性”。
第三,設計專門的注意力機制,將CNN的特徵與不同的CNN模塊進行交互。此外,作者表示,在代碼生成過程中考慮範圍名稱(例如,函數和方法名稱)是有用的,所以就使用了這樣的信息當作幾個池層的控制器。
於是,就得出了這樣的一個模型。

△模型概述。虛線箭頭表示注意力控制器。
這個模型,效果到底怎麼樣呢?
模型效果
作者用兩個任務評估了模型的效果。一個是生成《爐石傳說》遊戲的Python代碼,一個是用於語義解析的可執行邏輯形式生成。
生成《爐石傳說》的Python代碼
這個任務使用的是《爐石傳說》基準數據集,一共包括665張不同卡牌。
輸入是字段的半結構化描述,例如卡牌名、成本、攻擊、描述和其他屬性;

要輸出的是實現卡牌功能的Python代碼片段。

通過準確性與BLEU分數來測量模型的質量。在準確性方面,作者追蹤了之前大多數研究相同的方法,根據字符串匹配計算精度(表示爲StrAcc )。
有時候,幾個生成的程序使用了不同的變量名,但功能是正確的,這就需要人爲去調整。並用Acc +表示人爲調整的精度。
最後,用BLEU值評估生成的代碼的質量。
結果如下圖所示:
在準確性和BLEU分數方面,都優於之前的所有模型。StrAcc比之前最好的模型高出了5個百分點。經過人爲調整後的Acc+達到了30.3%,增加了3個百分點,之前的模型最好的效果提高了2%。
作者認爲,這顯示了他們方法的有效性。至於之前的模型跟他們的模型在BLEU分數上的相似性,作者解釋道,代碼生成還是要看細節。
語義解析任務
在語義解析任務中,使用的兩個語義解析數據集( ATIS和JOBS ),其中輸入是自然語言句子。ATIS的輸出是λ演算形式,而對於JOBS,輸出的是Prolog形式。

在這兩個數據集中,論文中提出的模型並沒有展現出什麼優勢。

作者在論文中表示,這可能是因爲語義解析的邏輯形式通常很短,因此,RNN和CNN都可以生成邏輯形式。
不過,這個實驗也證明了用CNN進行代碼生成的普遍性和靈活性。畢竟,整個模型基本上是爲長程序設計的,在語義解析方面也很好。
關於作者
按照署名順序,作者分別爲孫澤宇、朱琪豪、牟力立、熊英飛、李戈、張路,其中其中熊英飛爲通訊作者。作者單位爲北京大學信息科學技術學院。

傳送門
論文:
https://arxiv.org/abs/1811.06837
GitHub:
https://github.com/zysszy/GrammarCNN
— 完 —
誠摯招聘
量子位正在招募編輯/記者,工作地點在北京中關村。期待有才氣、有熱情的同學加入我們!相關細節,請在量子位公衆號(QbitAI)對話界面,回覆“招聘”兩個字。
量子位 QbitAI · 頭條號簽約作者
վ'ᴗ' ի 追蹤AI技術和產品新動態
查看原文 >>