快速瞭解hive


作者丨HappyMint
文章選摘:大數據與人工智能
這是作者的第7篇文章
本文主要針對從事大數據分析和架構相關工作,需要與hive打交道但目前對hive還沒有進行深層次瞭解的小夥伴,希望本文會讓你對hive有一個快速的瞭解。
內容主要包括什麼是hive、爲什麼要有hive、hive的架構、hive的數據組織以及hive的使用之DDL操作。
1.什麼是 hive?
1 是基於 Hadoop 的一個數據倉庫工具;
2 可以將結構化的數據映射爲一張數據庫表;
3 並提供 HQL(Hive SQL)查詢功能;
4 底層數據是存儲在 HDFS 上;
5 Hive的本質是將 SQL 語句轉換爲 MapReduce、Tez 或者 spark 等任務執行;
6 適用於離線的批量數據計算。

2. 爲什麼要有 hive?
如上文第5點已經提到的,hive可以封裝MapReduce、Tez、Spark等這些引擎的處理過程,讓使用者在不瞭解這些計算引擎具體執行細節的情況下就可以處理數據,使用者只需要學會如何寫sql即可。
hive可很好的解決直接使用 MapReduce、Tez、Spark等時所面臨的兩個主要問題:
① 直接使用 MapReduce、Tez、Spark學習成本太高,因爲需要了解底層具體執行引擎的處理邏輯,而且需要一定的編碼基礎;而Hive提供直接使用類sql語言即可進行數據查詢和處理的平臺或接口,只要使用者熟悉sql語言即可;
② MapReduce、Tez、Spark實現複雜查詢邏輯開發難度大,因爲需要自己寫代碼實現整個處理邏輯以及完成對數據處理過程的優化,而hive將很多數據統計邏輯封裝成了可直接使用的窗口函數,且支持自定義窗口函數來進行擴展,而且hive有邏輯和物理優化器,會對執行邏輯進行自動優化。
3. hive的架構
作爲hadoop的一個數據倉庫工具,hive的架構設計如下:

可以看出,Hive的內部架構總共分爲四大部分:
1 用戶接口層(cli、JDBC/ODBC、Web UI)
(1) cli (Command Line Interface),shell終端命令行,通過命令行與hive進行交互;
(2) JDBC/ODBC,是 Hive 的基於 JDBC 操作提供的客戶端,用戶(開發員,運維人員)通過客戶端連接至 Hive server 服務;
(3)Web UI,通過瀏覽器訪問hive。
2 元數據存儲系統
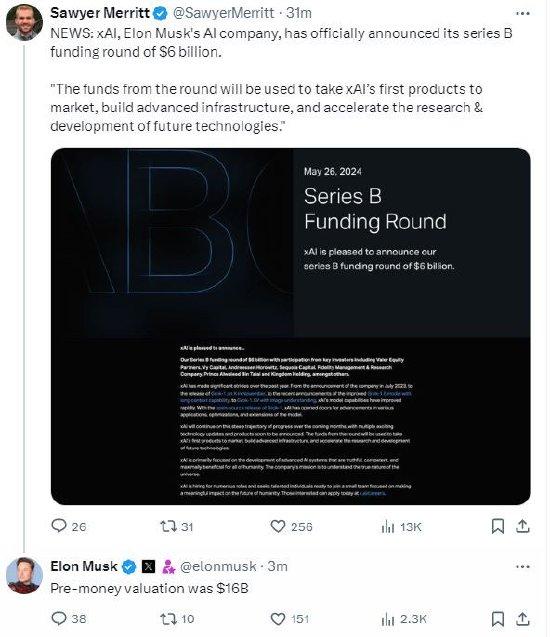
(1) 元數據 ,通俗的講,就是存儲在 Hive 中的數據的描述信息;
(2)Hive 中的元數據通常包括:表的名字,表的列和分區及其屬性,表的屬性(內部表和 外部表),表中數據所在的目錄;
(3)Metastore 默認存在自帶的 Derby 數據庫或者我們自己創建的 MySQL 庫中;
(4)Hive 和 MySQL或Derby 之間通過 MetaStore 服務交互。
3 Thrift Server-跨語言服務
Hive集成了Thrift Server,讓用戶可以使用多種不同語言來操作hive。
4 Driver(Compiler/Optimizer/Executor)
Driver完成HQL查詢語句的詞法分析、語法分析、編譯、優化以及查詢計劃的生成。生成的查詢計劃存儲在HDFS上,並由MapReduce調用執行。
整個過程的執行步驟如下:
(1) 解釋器完成詞法、語法和語義的分析以及中間代碼生成,最終轉換成抽象語法樹;
(2) 編譯器將語法樹編譯爲邏輯執行計劃;
(3) 邏輯層優化器對邏輯執行計劃進行優化,由於Hive最終生成的MapReduce任務中,而Map階段和Reduce階段均由OperatorTree組成,所以大部分邏輯層優化器通過變換OperatorTree,合併操作符,達到減少MapReduce Job和減少shuffle數據量的目的;
(4) 物理層優化器進行MapReduce任務的變換,生成最終的物理執行計劃;
(5) 執行器調用底層的運行框架執行最終的物理執行計劃。
4. hive的數據組織
通過上文對hive的內部架構進行的介紹和解析,相信大家對一條查詢語句的整個底層執行過程有了一點概念;接下來我們再來了解下hive的另一個重要知識點,即查詢語句中用到的庫表相關方面的知識——hive的數據組織方式。
hive數據組織:
1 Hive 的存儲結構包括數據庫、表、視圖、分區和表數據等。數據庫,表,分區等都對應HDFS上的一個目錄。表數據對應 HDFS 對應目錄下的文件。
2 Hive 中包含以下數據模型:
database:在 HDFS 中表現爲${hive.metastore.warehouse.dir}或者指定的目錄下的一個文件夾;
table:在 HDFS 中表現爲某個 database 目錄下一個文件夾;
external table:與 table 類似,在 HDFS 中也表現爲某個 database 目錄下一個文件夾;
partition:在 HDFS 中表現爲 table 目錄下的子目錄;
bucket:在 HDFS 中表現爲同一個表目錄或者分區目錄下根據某個字段的值進行 hash 散列之後的多個文件;
view:與傳統數據庫類似,只讀,基於基本表創建。
3 Hive 中的表分爲內部表、外部表、分區表和 Bucket 表。
內部表和外部表的區別:
1.內部表數據由Hive自身管理,外部表數據由HDFS管理;
2.刪除內部表會直接刪除元數據(metadata)及存儲數據;刪除外部表僅僅會刪除元數據,HDFS上的文件並不會被刪除。
分區表和分桶表的區別:
1.分區表,Hive 數據表可以根據某些字段進行分區操作,細化數據管理,讓部分查詢更快;
2.分桶表:表和分區也可以進一步被劃分爲桶,分桶表中的數據是按照某些分桶字段進行 hash 散列形成的多個文件。
5. hive的使用之DDL操作
關於hive的DDL(Data Definition Language)操作,以下分爲庫和表兩方面來歸納:
庫
(1) 創建庫

(2) 查看庫

(3) 刪除庫

(4) 切換庫

表
1 創建表
(1)創建默認的內部表

(2)創建外部表

(3)創建分區表

添加分區

(4)創建分桶表

(5)使用CTAS創建表
從一個查詢SQL的結果來創建一個表進行存儲;
(6)複製表結構

2 查看錶
(1) 查看錶列表

(2) 查看錶的詳細信息

(3) 修改表

(4) 刪除表

(5) 清空表
結語:
本文主要整體性的給大家介紹了下什麼是hive、使用hive的原因、hive的架構、hive的數據組織以及hive的DDL操作,希望閱讀完本文的小夥伴們,對hive有一個快速的瞭解。
-END-