jvm內部緩存選型?一篇文章爲你解答疑惑
jvm內部緩存有哪些
原生Java
簡單的在HashMap的鏈式法增加新的引用形成一個鏈表,即是一個HashMap又是一個鏈表,這樣輸出即有序,也可以根據訪問來動態調整順序,達到FIFO或者LRU的特點。
使用ConcurrentHashMap作爲緩存,沒有淘汰功能或者手動淘汰。但是尋找效率較高,而且線程安全
可以明顯看出這個存在的問題,線程不安全,需要額外加鎖,功能結構單一,沒有過期時間容易存在內存泄露
Guava
因爲LinkedHashMap存在的問題,所以大神們在此基礎上造出了Guava
既然HashMap線程不安全,那麼就使用CurrentHashMap(類似不完全是),爲了實現過期那麼就給數據加上時間戳標誌,爲了實現寫後過期,讀後過期,這兩種配置,就使用了多條隊列分別代表讀和寫
EHCHCHED
Ehcache支持持久化到本地磁盤,Guava不可以;
Ehcache有現成的集羣解決方案,Guava沒有。不過個人感覺比較雞肋,對JVM級別的緩存來講太重了
Ehcache jar包龐大,Guava Cache只是Guava jar包中的工具之一,而且後者遠遠小於Ehcache;
兩種緩存當緩存過期或者沒有命中的時候都可以通過load接口重載數據,調用方式略有不同。兩者的主要區別是Ehcache的緩存load的時候,允許用戶返回null,而Guava Cache則不允許返回爲null,因爲Guava Cache是根據value的值是否爲null來判斷是否需要load,所以不允許返回爲null,但是使用的時候可以使用空對象替換。不允許返回null是一個很好的考慮;
Ehcache有內存佔用大小統計,Guava Cache沒有,需要自己開發;
Ehcache在put緩存的時候,對K、V都做了包裝,對GC有一定影響。
Caffeine
Caffeine是Spring 5默認支持的Cache,可見Spring對它的看重,那麼Spring爲什麼喜新厭舊的拋棄Guava而追求Caffeine呢?
緩存的淘汰策略是爲了預測哪些數據在短期內最可能被再次用到,從而提升緩存的命中率。LRU由於實現簡單、高效的運行時表現以及在常規的使用場景下有不錯的命中率,或許是目前最佳的實現途徑。但 LRU 通過歷史數據來預測未來是侷限的,它會認爲最後到來的數據是最可能被再次訪問的,從而給與它最高的優先級。這樣就意味着淘汰真正熱點數據,爲了解決這個問題業界運用一些數據結構上的改進巧妙的解決這個問題。
下面的內容是轉載的一篇譯文,如果需要查看譯文原文,請點擊這裏,英語好的同學也可以直接查看英文原作。
緩存是提升性能的通用方法,現在大多數的緩存實現都使用了經典的技術。這篇文章中,我們會發掘Caffeine中的現代的實現方法。Caffeine是一個開源的Java緩存庫,它能提供高命中率和出色的併發能力。期望讀者們能被這些想法激發,進而將它們應用到任何你喜歡的編程語言中。
驅逐策略
緩存的驅逐策略是爲了預測哪些數據在短期內最可能被再次用到,從而提升緩存的命中率。由於簡潔的實現、高效的運行時表現以及在常規的使用場景下有不錯的命中率,LRU(Least Recently Used)策略或許是最流行的驅逐策略。但LRU通過歷史數據來預測未來是侷限的,它會認爲最後到來的數據是最可能被再次訪問的,從而給與它最高的優先級。
現代緩存擴展了對歷史數據的使用,結合就近程度(recency)和訪問頻次(frequency)來更好的預測數據。其中一種保留歷史信息的方式是使用popularity sketch(一種壓縮、概率性的數據結構)來從一大堆訪問事件中定位頻繁的訪問者。可以參考CountMin Sketch算法,它由計數矩陣和多個哈希方法實現。發生一次讀取時,矩陣中每行對應的計數器增加計數,估算頻率時,取數據對應是所有行中計數的最小值。這個方法讓我們從空間、效率、以及適配矩陣的長寬引起的哈希碰撞的錯誤率上做權衡。
Window TinyLFU(W-TinyLFU)算法將sketch作爲過濾器,當新來的數據比要驅逐的數據高頻時,這個數據纔會被緩存接納。這個許可窗口給予每個數據項積累熱度的機會,而不是立即過濾掉。這避免了持續的未命中,特別是在突然流量暴漲的的場景中,一些短暫的重複流量就不會被長期保留。爲了刷新歷史數據,一個時間衰減進程被週期性或增量的執行,給所有計數器減半。
對於長期保留的數據,W-TinyLFU使用了分段LRU(Segmented LRU,縮寫SLRU)策略。起初,一個數據項存儲被存儲在試用段(probationary segment)中,在後續被訪問到時,它會被提升到保護段(protected segment)中(保護段佔總容量的80%)。保護段滿後,有的數據會被淘汰回試用段,這也可能級聯的觸發試用段的淘汰。這套機制確保了訪問間隔小的熱數據被保存下來,而被重複訪問少的冷數據則被回收。
如圖中數據庫和搜索場景的結果展示,通過考慮就近程度和頻率能大大提升LRU的表現。一些高級的策略,像ARC,LIRS和W-TinyLFU都提供了接近最理想的命中率。想看更多的場景測試,請查看相應的論文,也可以在使用simulator來測試自己的場景。
過期策略
過期的實現裏,往往每個數據項擁有不同的過期時間。因爲容量的限制,過期後數據需要被懶淘汰,否則這些已過期的髒數據會污染到整個緩存。一般緩存中會啓用專有的清掃線程週期性的遍歷清理緩存。這個策略相比在每次讀寫操作時按照過期時間排序的優先隊列來清理過期緩存要好,因爲後臺線程隱藏了的過期數據清除的時間開銷。
鑑於大多數場景裏不同數據項使用的都是固定的過期時長,Caffien採用了統一過期時間的方式。這個限制讓用O(1)的有序隊列組織數據成爲可能。針對數據的寫後過期,維護了一個寫入順序隊列,針對讀後過期,維護了一個讀取順序隊列。緩存能複用驅逐策略下的隊列以及下面將要介紹的併發機制,讓過期的數據項在緩存的維護階段被拋棄掉。
併發
由於在大多數的緩存策略中,數據的讀取都會伴隨對緩存狀態的寫操作,併發的緩存讀取被視爲一個難點問題。傳統的解決方式是用同步鎖。這可以通過將緩存的數據劃成多個分區來進行鎖拆分優化。不幸的是熱點數據所持有的鎖會比其他數據更常的被佔有,在這種場景下鎖拆分的性能提升也就沒那麼好了。當單個鎖的競爭成爲瓶頸後,接下來的經典的優化方式是隻更新單個數據的元數據信息,以及使用隨機採樣、基於FIFO的驅逐策略來減少數據操作。這些策略會帶來高性能的讀和低性能的寫,同時在選擇驅逐對象時也比較困難。
另一種可行方案來自於數據庫理論,通過提交日誌的方式來擴展寫的性能。寫入操作先記入日誌中,隨後異步的批量執行,而不是立即寫入到數據結構中。這種思想可以應用到緩存中,執行哈希表的操作,將操作記錄到緩衝區,然後在合適的時機執行緩衝區中的內容。這個策略依然需要同步鎖或者tryLock,不同的是把對鎖的競爭轉移到對緩衝區的追加寫上。
在Caffeine中,有一組緩衝區被用來記錄讀寫。一次訪問首先會被因線程而異的哈希到stripped ring buffer上,當檢測到競爭時,緩衝區會自動擴容。一個ring buffer容量滿載後,會觸發異步的執行操作,而後續的對該ring buffer的寫入會被丟棄,直到這個ring buffer可被使用。雖然因爲ring buffer容量滿而無法被記錄該訪問,但緩存值依然會返回給調用方。這種策略信息的丟失不會帶來大的影響,因爲W-TinyLFU能識別出我們希望保存的熱點數據。通過使用因線程而異的哈希算法替代在數據項的鍵上做哈希,緩存避免了瞬時的熱點key的競爭問題。
寫數據時,採用更傳統的併發隊列,每次變更會引起一次立即的執行。雖然數據的損失是不可接受的,但我們仍然有很多方法可以來優化寫緩衝區。所有類型的緩衝區都被多個的線程寫入,但卻通過單個線程來執行。這種多生產者/單個消費者的模式允許了更簡單、高效的算法來實現。
緩衝區和細粒度的寫帶來了單個數據項的操作亂序的競態條件。插入、讀取、更新、刪除都可能被各種順序的重放,如果這個策略控制的不合適,則可能引起懸垂索引。解決方案是通過狀態機來定義單個數據項的生命週期。
在基準測試中,緩衝區隨着哈希表的增長而增長,它的的使用相對更節省資源。讀的性能隨着CPU的核數線性增長,是哈希表吞吐量的33%。寫入有10%的性能損耗,這是因爲更新哈希表時的競爭是最主要的開銷。
Caffeine
舉個例子
Mysql的緩存池,內部實現是一個LRU,但是其內部有個中間點,指向倒數3/8,一半是old區,另一半是young區,新數據插入是直接插入young區,這樣就保護了真正的老數據不會被沖刷掉。
多級隊列的形式
LFU結合頻率這一屬性給予更好的預測緩存數據是否在未來被使用。
但是傳統LFU有其侷限性:
LFU實現需要維護大而複雜的元數據(頻次統計數據等)
大多數實際工作負載中,訪問頻率隨着時間的推移而發生根本變化,而傳統LFU無法週期衰減頻率
傳統LFU的實現通過外接一個HashMap統計頻率,但是HashMap存在Hash衝突,這會導致頻率統計的不準確。
爲了解決這些問題,Caffeine提出一種新的算法W-TinyLFU,它可以解決頻率統計不準確以及訪問頻率衰減問題。這個方法讓我們從空間、效率、以及適配矩陣的長寬引起的哈希碰撞的錯誤率上做權衡。
傳統Hash存在Hash衝突的問題,使用LFU算法時候記錄頻率的話一旦發生hash衝突可能造成頻率的統計錯誤。
W-TinyLFU算法使用一種Count-Min Sketch解決維護空間大的問題,類似布隆過濾器,降低衝突可能性,原理是多次hash分散開來,取最小值作爲頻率,一次Hash衝突的幾率是1%的話,4次Hash的幾率就是1%的4次方,大大降低的衝突可能性。
在Caffeine中爲了實現Count-Min Sketch它在其中村政府,存放四個算法
其中randomSeed是一個隨機數,sampleSize=開始設置的緩存最大樹*10;table= 最大緩存數最接近的2的次方數(100的話是128,50是64);tableMask = table.length-1;size=0
在向緩存put數據的時候會調用
這個AddTask是一個Runnable,其中run方法會調用increment方法。
Caffeine比guava好在哪
W-TinyLFU
傳統的LFU受時間週期的影響比較大。所以各種LFU的變種出現了,基於時間週期進行衰減,或者在最近某個時間段內的頻率。同樣的LFU也會使用額外空間記錄每一個數據訪問的頻率,即使數據沒有在緩存中也需要記錄,所以需要維護的額外空間很大。
可以試想我們對這個維護空間建立一個hashMap,每個數據項都會存在這個hashMap中,當數據量特別大的時候,這個hashMap也會特別大。
再回到LRU,我們的LRU也不是那麼一無是處,LRU可以很好的應對突發流量的情況,因爲他不需要累計數據頻率。
所以W-TinyLFU結合了LRU和LFU,以及其他的算法的一些特點。
頻率記錄
首先要說到的就是頻率記錄的問題,我們要實現的目標是利用有限的空間可以記錄隨時間變化的訪問頻率。在W-TinyLFU中使用Count-Min Sketch記錄我們的訪問頻率,而這個也是布隆過濾器的一種變種。
如果需要記錄一個值,那我們需要通過多種Hash算法對其進行處理hash,然後在對應的hash算法的記錄中+1,爲什麼需要多種hash算法呢?由於這是一個壓縮算法必定會出現衝突,比如我們建立一個Long的數組,通過計算出每個數據的hash的位置。比如張三和李四,他們兩有可能hash值都是相同,比如都是1那Long[1]這個位置就會增加相應的頻率,張三訪問1萬次,李四訪問1次那Long[1]這個位置就是1萬零1,如果取李四的訪問評率的時候就會取出是1萬零1,但是李四命名只訪問了1次啊,爲了解決這個問題,所以用了多個hash算法可以理解爲long[][]二維數組的一個概念,比如在第一個算法張三和李四衝突了,但是在第二個,第三個中很大的概率不衝突,比如一個算法大概有1%的概率衝突,那四個算法一起衝突的概率是1%的四次方。通過這個模式我們取李四的訪問率的時候取所有算法中,李四訪問最低頻率的次數。所以他的名字叫Count-Min Sketch。
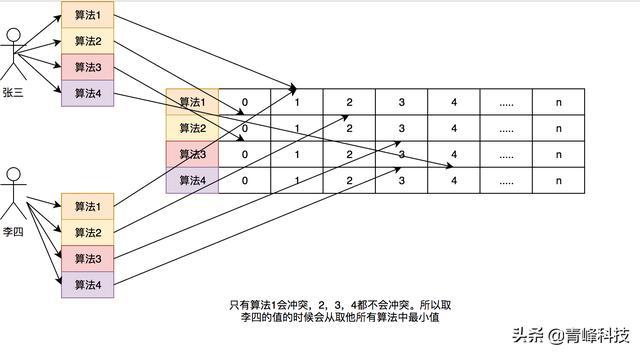
這裏和以前的做個對比,簡單的舉個例子:如果一個hashMap來記錄這個頻率,如果我有100個數據,那這個HashMap就得存儲100個這個數據的訪問頻率。哪怕我這個緩存的容量是1,因爲Lfu的規則我必須全部記錄這個100個數據的訪問頻率。如果有更多的數據我就有記錄更多的。
在Count-Min Sketch中,我這裏直接說caffeine中的實現吧(在FrequencySketch這個類中),如果你的緩存大小是100,他會生成一個long數組大小是和100最接近的2的冪的數,也就是128。而這個數組將會記錄我們的訪問頻率。在caffeine中規定頻率最大爲15,15的二進制位1111,總共是4位,而Long型是64位。所以每個Long型可以放16種算法,但是caffeine並沒有這麼做,只用了四種hash算法,每個Long型被分爲四段,每段裏面保存的是四個算法的頻率。這樣做的好處是可以進一步減少Hash衝突,原先128大小的hash,就變成了128X4。
一個Long的結構如下:
我們的4個段分爲A,B,C,D,在後面我也會這麼叫它們。而每個段裏面的四個算法我叫他s1,s2,s3,s4。下面舉個例子如果要添加一個訪問50的數字頻率應該怎麼做?我們這裏用size=100來舉例。
首先確定50這個hash是在哪個段裏面,通過hash & 3(3的二進制是11)必定能獲得小於4的數字,假設hash & 3=0,那就在A段。
對50的hash再用其他hash算法再做一次hash,得到long數組的位置,也就是在長度128數組中的位置。假設用s1算法得到1,s2算法得到3,s3算法得到4,s4算法得到0。
因爲S1算法得到的是1,所以在long[1]的A段裏面的s1位置進行+1,簡稱1As1加1,然後在3As2加1,在4As3加1,在0As4加1。

這個時候有人會質疑頻率最大爲15的這個是否太小?沒關係在這個算法中,比如size等於100,如果他全局提升了size*10也就是1000次就會全局除以2衰減,衰減之後也可以繼續增加,這個算法再W-TinyLFU的論文中證明了其可以較好的適應時間段的訪問頻率。
讀寫性能
在guava cache中我們說過其讀寫操作中夾雜着過期時間的處理,也就是你在一次Put操作中有可能還會做淘汰操作,所以其讀寫性能會受到一定影響,可以看上面的圖中,caffeine的確在讀寫操作上面完爆guava cache。主要是因爲在caffeine,對這些事件的操作是通過異步操作,他將事件提交至隊列,這裏的隊列的數據結構是RingBuffer,不清楚的可以看看這篇文章,你應該知道的高性能無鎖隊列Disruptor。然後會通過默認的ForkJoinPool.commonPool(),或者自己配置線程池,進行取隊列操作,然後在進行後續的淘汰,過期操作。
當然讀寫也是有不同的隊列,在caffeine中認爲緩存讀比寫多很多,所以對於寫操作是所有線程共享一個Ringbuffer。

對於讀操作比寫操作更加頻繁,進一步減少競爭,其爲每個線程配備了一個RingBuffer:
數據淘汰策略
在caffeine所有的數據都在ConcurrentHashMap中,這個和guava cache不同,guava cache是自己實現了個類似ConcurrentHashMap的結構。在caffeine中有三個記錄引用的LRU隊列:
Eden隊列:在caffeine中規定只能爲緩存容量的%1,如果size=100,那這個隊列的有效大小就等於1。這個隊列中記錄的是新到的數據,防止突發流量由於之前沒有訪問頻率,而導致被淘汰。比如有一部新劇上線,在最開始其實是沒有訪問頻率的,防止上線之後被其他緩存淘汰出去,而加入這個區域。伊甸區,最舒服最安逸的區域,在這裏很難被其他數據淘汰。
Probation隊列:叫做緩刑隊列,在這個隊列就代表你的數據相對比較冷,馬上就要被淘汰了。這個有效大小爲size減去eden減去protected。
Protected隊列:在這個隊列中,可以稍微放心一下了,你暫時不會被淘汰,但是別急,如果Probation隊列沒有數據了或者Protected數據滿了,你也將會被面臨淘汰的尷尬局面。當然想要變成這個隊列,需要把Probation訪問一次之後,就會提升爲Protected隊列。這個有效大小爲(size減去eden) X 80% 如果size =100,就會是79。
這三個隊列關係如下:

所有的新數據都會進入Eden。
Eden滿了,淘汰進入Probation。
如果在Probation中訪問了其中某個數據,則這個數據升級爲Protected。
如果Protected滿了又會繼續降級爲Probation。
對於發生數據淘汰的時候,會從Probation中進行淘汰。會把這個隊列中的數據隊頭稱爲受害者,這個隊頭肯定是最早進入的,按照LRU隊列的算法的話那他其實他就應該被淘汰,但是在這裏只能叫他受害者,這個隊列是緩刑隊列,代表馬上要給他行刑了。這裏會取出隊尾叫候選者,也叫攻擊者。這裏受害者會和攻擊者皇城PK決出我們應該被淘汰的。
通過我們的Count-Min Sketch中的記錄的頻率數據有以下幾個判斷:
如果攻擊者大於受害者,那麼受害者就直接被淘汰。
如果攻擊者<=5,那麼直接淘汰攻擊者。這個邏輯在他的註釋中有解釋:
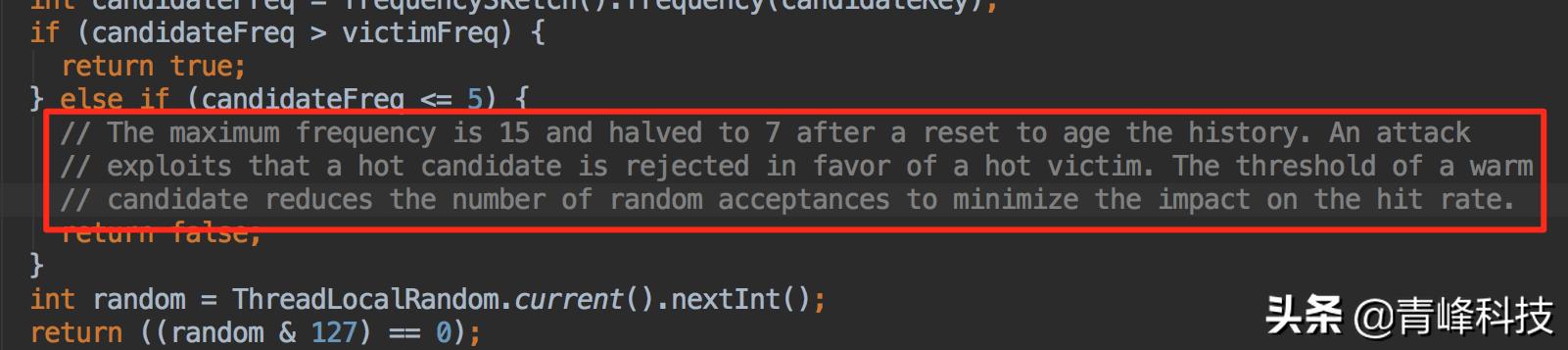
他認爲設置一個預熱的門檻會讓整體命中率更高。
其他情況,隨機淘汰。
【責任編輯:武曉燕 TEL:(010)68476606】









