美團搜索中 NER 技術的探索與實踐
1. 背景
命名實體識別(Named Entity Recognition,簡稱 NER),又稱作“專名識別”,是指識別文本中具有特定意義的實體,主要包括人名、地名、機構名、專有名詞等。在美團搜索場景下,NER 是深度查詢理解(Deep Query Understanding,簡稱 DQU)的底層基礎信號,主要應用於搜索召回、用戶意圖識別、實體鏈接等環節,NER 信號的質量,直接影響到用戶的搜索體驗。
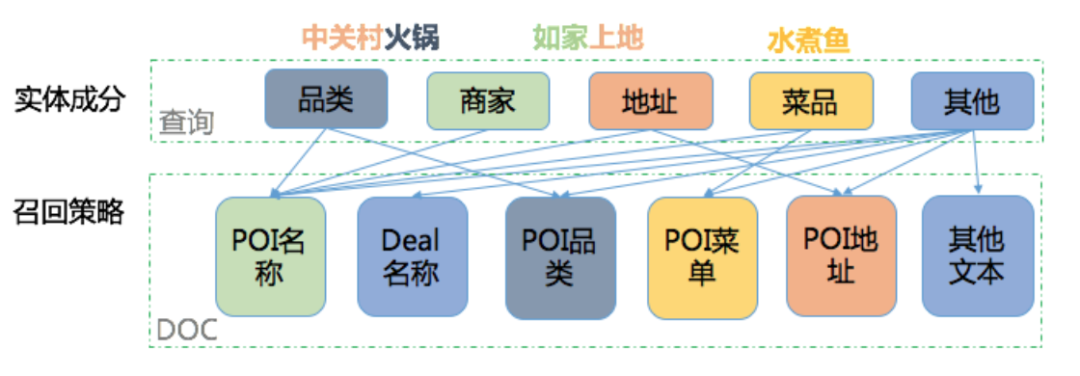
下面將簡述一下實體識別在搜索召回中的應用。在 O2O 搜索中,對商家 POI 的描述是商家名稱、地址、品類等多個互相之間相關性並不高的文本域。如果對 O2O 搜索引擎也採用全部文本域命中求交的方式,就可能會產生大量的誤召回。
我們的解決方法如下圖 1 所示,讓特定的查詢只在特定的文本域做倒排檢索,我們稱之爲“結構化召回”,可保證召回商家的強相關性。舉例來說,對於“海底撈”這樣的請求,有些商家地址會描述爲“海底撈附近幾百米”,若採用全文本域檢索這些商家就會被召回,顯然這並不是用戶想要的。而結構化召回基於 NER 將“海底撈”識別爲商家,然後只在商家名相關文本域檢索,從而只召回海底撈品牌商家,精準地滿足了用戶需求。
有別於其他應用場景,美團搜索的 NER 任務具有以下特點:
- 新增實體數量龐大且增速較快 :本地生活服務領域發展迅速,新店、新商品、新服務品類層出不窮;用戶 Query 往往夾雜很多非標準化表達、簡稱和熱詞(如“牽腸掛肚”、“吸貓”等),這對實現高準確率、高覆蓋率的 NER 造成了很大挑戰。
- 領域相關性強 :搜索中的實體識別與業務供給高度相關,除通用語義外需加入業務相關知識輔助判斷,比如“剪了個頭發”,通用理解是泛化描述實體,在搜索中卻是個商家實體。
- 性能要求高 :從用戶發起搜索到最終結果呈現給用戶時間很短,NER 作爲 DQU 的基礎模塊,需要在毫秒級的時間內完成。近期,很多基於深度網絡的研究與實踐顯著提高了 NER 的效果,但這些模型往往計算量較大、預測耗時長,如何優化模型性能,使之能滿足 NER 對計算時間的要求,也是 NER 實踐中的一大挑戰。
2. 技術選型
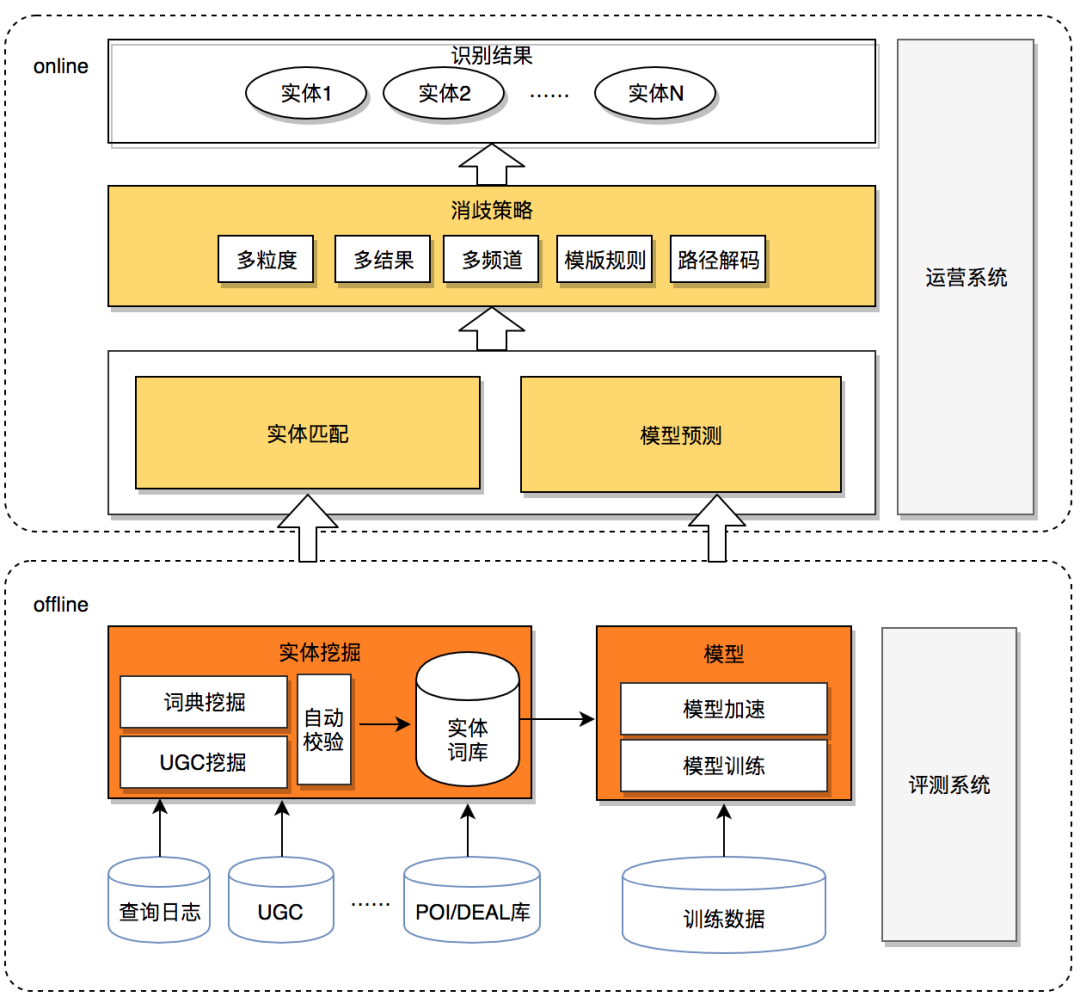
針對 O2O 領域 NER 任務的特點,我們整體的技術選型是“實體詞典匹配 + 模型預測”的框架,如圖下 2 所示。實體詞典匹配和模型預測兩者解決的問題各有側重,在當前階段缺一不可。下面通過對三個問題的解答來說明我們爲什麼這麼選。
爲什麼需要實體詞典匹配?
答: 主要有以下四個原因:
一是搜索中用戶查詢的頭部流量通常較短、表達形式簡單,且集中在商戶、品類、地址等三類實體搜索,實體詞典匹配雖簡單但處理這類查詢準確率也可達到 90% 以上。
二是 NER 領域相關,通過挖掘業務數據資源獲取業務實體詞典,經過在線詞典匹配後可保證識別結果是領域適配的。
三是新業務接入更加靈活,只需提供業務相關的實體詞表就可完成新業務場景下的實體識別。
四是 NER 下游使用方中有些對響應時間要求極高,詞典匹配速度快,基本不存在性能問題。
有了實體詞典匹配爲什麼還要模型預測?
答: 有以下兩方面的原因:
一是隨着搜索體量的不斷增大,中長尾搜索流量表述複雜,越來越多 OOV(Out Of Vocabulary)問題開始出現,實體詞典已經無法滿足日益多樣化的用戶需求,模型預測具備泛化能力,可作爲詞典匹配的有效補充。
二是實體詞典匹配無法解決歧義問題,比如“黃鶴樓美食”,“黃鶴樓”在實體詞典中同時是武漢的景點、北京的商家、香菸產品,詞典匹配不具備消歧能力,這三種類型都會輸出,而模型預測則可結合上下文,不會輸出“黃鶴樓”是香菸產品。
實體詞典匹配、模型預測兩路結果是怎麼合併輸出的?
答: 目前我們採用訓練好的 CRF 權重網絡作爲打分器,來對實體詞典匹配、模型預測兩路輸出的 NER 路徑進行打分。在詞典匹配無結果或是其路徑打分值明顯低於模型預測時,採用模型識別的結果,其他情況仍然採用詞典匹配結果。
在介紹完我們的技術選型後,接下來會展開介紹下我們在實體詞典匹配、模型在線預測等兩方面的工作,希望能爲大家在 O2O NER 領域的探索提供一些幫助。
3. 實體詞典匹配
傳統的 NER 技術僅能處理通用領域既定、既有的實體,但無法應對垂直領域所特有的實體類型。在美團搜索場景下,通過對 POI 結構化信息、商戶評論數據、搜索日誌等獨有數據進行離線挖掘,可以很好地解決領域實體識別問題。經過離線實體庫不斷的豐富完善累積後,在線使用輕量級的詞庫匹配實體識別方式簡單、高效、可控,且可以很好地覆蓋頭部和腰部流量。目前,基於實體庫的在線 NER 識別率可以達到 92%。
3.1 離線挖掘
美團具有豐富多樣的結構化數據,通過對領域內結構化數據的加工處理可以獲得高精度的初始實體庫。例如:從商戶基礎信息中,可以獲取商戶名、類目、地址、售賣商品或服務等類型實體。從貓眼文娛數據中,可以獲取電影、電視劇、藝人等類型實體。然而,用戶搜索的實體名往往夾雜很多非標準化表達,與業務定義的標準實體名之間存在差異,如何從非標準表達中挖掘領域實體變得尤爲重要。
現有的新詞挖掘技術主要分爲無監督學習、有監督學習和遠程監督學習。無監督學習通過頻繁序列產生候選集,並通過計算緊密度和自由度指標進行篩選,這種方法雖然可以產生充分的候選集合,但僅通過特徵閾值過濾無法有效地平衡精確率與召回率,現實應用中通常挑選較高的閾值保證精度而犧牲召回。先進的新詞挖掘算法大多爲有監督學習,這類算法通常涉及複雜的語法分析模型或深度網絡模型,且依賴領域專家設計繁多規則或大量的人工標記數據。遠程監督學習通過開源知識庫生成少量的標記數據,雖然一定程度上緩解了人力標註成本高的問題。然而小樣本量的標記數據僅能學習簡單的統計模型,無法訓練具有高泛化能力的複雜模型。
我們的離線實體挖掘是多源多方法的,涉及到的數據源包括結構化的商家信息庫、百科詞條,半結構化的搜索日誌,以及非結構化的用戶評論(UGC)等。使用的挖掘方法也包含多種,包括規則、傳統機器學習模型、深度學習模型等。UGC 作爲一種非結構化文本,蘊含了大量非標準表達實體名。下面我們將詳細介紹一種針對 UGC 的垂直領域新詞自動挖掘方法,該方法主要包含三個步驟,如下圖 3 所示:
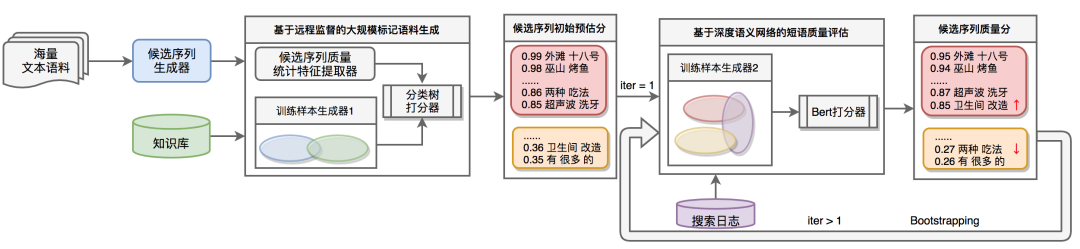
Step1:候選序列挖掘。頻繁連續出現的詞序列,是潛在新型詞彙的有效候選,我們採用頻繁序列產生充足候選集合。
Step2:基於遠程監督的大規模有標記語料生成。頻繁序列隨着給定語料的變化而改變,因此人工標記成本極高。我們利用領域已有累積的實體詞典作爲遠程監督詞庫,將 Step1 中候選序列與實體詞典的交集作爲訓練正例樣本。同時,通過對候選序列分析發現,在上百萬的頻繁 Ngram 中僅約 10% 左右的候選是真正的高質新型詞彙。因此,對於負例樣本,採用負採樣方式生產訓練負例集 [1]。針對海量 UGC 語料,我們設計並定義了四個維度的統計特徵來衡量候選短語可用性:
- 頻率 :有意義的新詞在語料中應當滿足一定的頻率,該指標由 Step1 計算得到。
- 緊密度 :主要用於評估新短語中連續元素的共現強度,包括 T 分佈檢驗、皮爾森卡方檢驗、逐點互信息、似然比等指標。
- 信息度 :新發現詞彙應具有真實意義,指代某個新的實體或概念,該特徵主要考慮了詞組在語料中的逆文檔頻率、詞性分佈以及停用詞分佈。
- 完整性 :新發現詞彙應當在給定的上下文環境中作爲整體解釋存在,因此應同時考慮詞組的子集短語以及超集短語的緊密度,從而衡量詞組的完整性。
在經過小樣本標記數據構建和多維度統計特徵提取後,訓練二元分類器來計算候選短語預估質量。由於訓練數據負例樣本採用了負採樣的方式,這部分數據中混合了少量高質量的短語,爲了減少負例噪聲對短語預估質量分的影響,可以通過集成多個弱分類器的方式減少誤差。對候選序列集合進行模型預測後,將得分超過一定閾值的集合作爲正例池,較低分數的集合作爲負例池。
Step3: 基於深度語義網絡的短語質量評估。在有大量標記數據的情況下,深度網絡模型可以自動有效地學習語料特徵,併產出具有泛化能力的高效模型。BERT 通過海量自然語言文本和深度模型學習文本語義表徵,並經過簡單微調在多個自然語言理解任務上刷新了記錄,因此我們基於 BERT 訓練短語質量打分器。爲了更好地提升訓練數據的質量,我們利用搜索日誌數據對 Step2 中生成的大規模正負例池數據進行遠程指導,將有大量搜索記錄的詞條作爲有意義的關鍵詞。我們將正例池與搜索日誌重合的部分作爲模型正樣本,而將負例池減去搜索日誌集合的部分作爲模型負樣本,進而提升訓練數據的可靠性和多樣性。此外,我們採用 Bootstrapping 方式,在初次得到短語質量分後,重新根據已有短語質量分以及遠程語料搜索日誌更新訓練樣本,迭代訓練提升短語質量打分器效果,有效減少了僞正例和僞負例。
在 UGC 語料中抽取出大量新詞或短語後,參考 AutoNER[2] 對新挖掘詞語進行類型預測,從而擴充離線的實體庫。
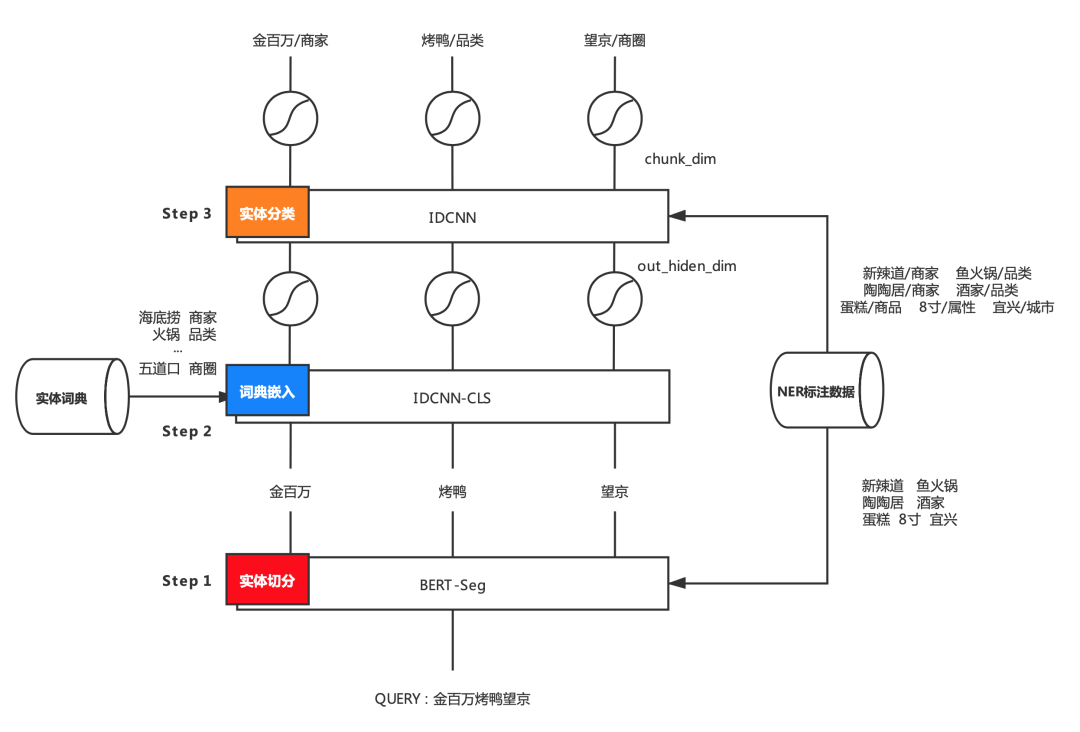
3.2 在線匹配
原始的在線 NER 詞典匹配方法直接針對 Query 做雙向最大匹配,從而獲得成分識別候選集合,再基於詞頻(這裏指實體搜索量)篩選輸出最終結果。這種策略比較簡陋,對詞庫準確度和覆蓋度要求極高,所以存在以下幾個問題:
- 當 Query 包含詞庫未覆蓋實體時,基於字符的最大匹配算法易引起切分錯誤。例如,搜索詞“海坨山谷”,詞庫僅能匹配到“海坨山”,因此出現“海坨山 / 谷”的錯誤切分。
- 粒度不可控。例如,搜索詞“星巴克咖啡”的切分結果,取決於詞庫對“星巴克”、“咖啡”以及“星巴克咖啡”的覆蓋。
- 節點權重定義不合理。例如,直接基於實體搜索量作爲實體節點權重,當用戶搜索“信陽菜館”時,“信陽菜 / 館”的得分大於“信陽 / 菜館”。
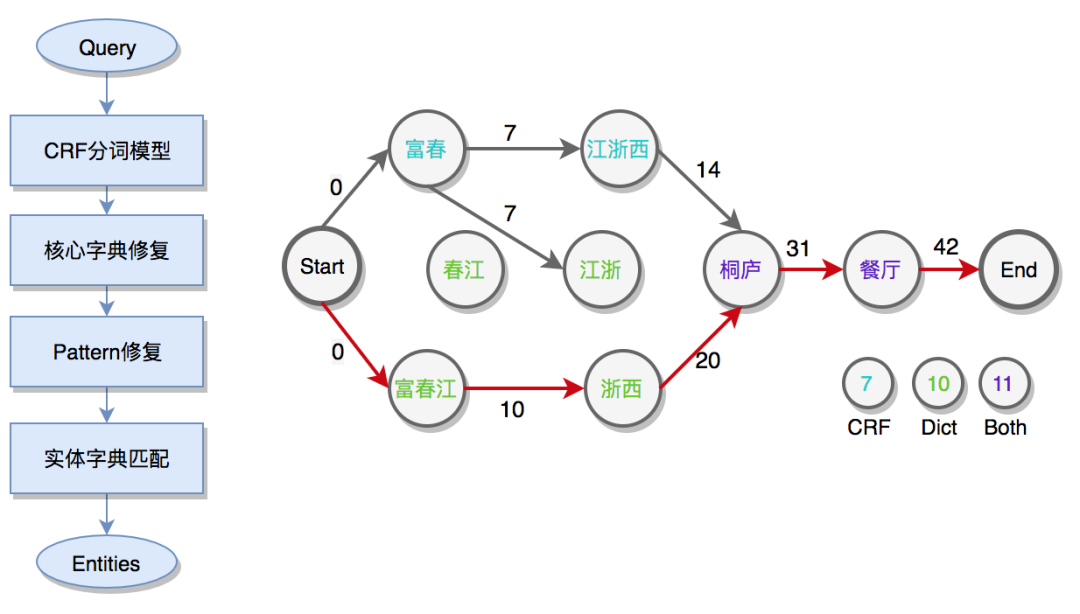
爲了解決以上問題,在進行實體字典匹配前引入了 CRF 分詞模型,針對垂直領域美團搜索制定分詞準則,人工標註訓練語料並訓練 CRF 分詞模型。同時,針對模型分詞錯誤問題,設計兩階段修復方式:
- 結合模型分詞 Term 和基於領域字典匹配 Term,根據動態規劃求解 Term 序列權重和的最優解。
- 基於 Pattern 正則表達式的強修復規則。最後,輸出基於實體庫匹配的成分識別結果。
4. 模型在線預測
對於長尾、未登錄查詢,我們使用模型進行在線識別。NER 模型的演進經歷瞭如下圖 5 所示的幾個階段,目前線上使用的主模型是 BERT[3] 以及 BERT+LR 級聯模型,另外還有一些在探索中模型的離線效果也證實有效,後續我們會綜合考慮性能和收益逐步進行上線。搜索中 NER 線上模型的構建主要面臨三個問題:
- 性能要求高 :NER 作爲基礎模塊,模型預測需要在毫秒級時間內完成,而目前基於深度學習的模型都有計算量大、預測時間較長的問題。
- 領域強相關 :搜索中的實體類型與業務供給高度相關,只考慮通用語義很難保證模型識別的準確性。
- 標註數據缺乏 :NER 標註任務相對較難,需給出實體邊界切分、實體類型信息,標註過程費時費力,大規模標註數據難以獲取。
針對性能要求高的問題,我們的線上模型在升級爲 BERT 時進行了一系列的性能調優;針對 NER 領域相關問題,我們提出了融合搜索日誌特徵、實體詞典信息的知識增強 NER 方法;針對訓練數據難以獲取的問題,我們提出一種弱監督的 NER 方法。下面我們詳細介紹下這些技術點。
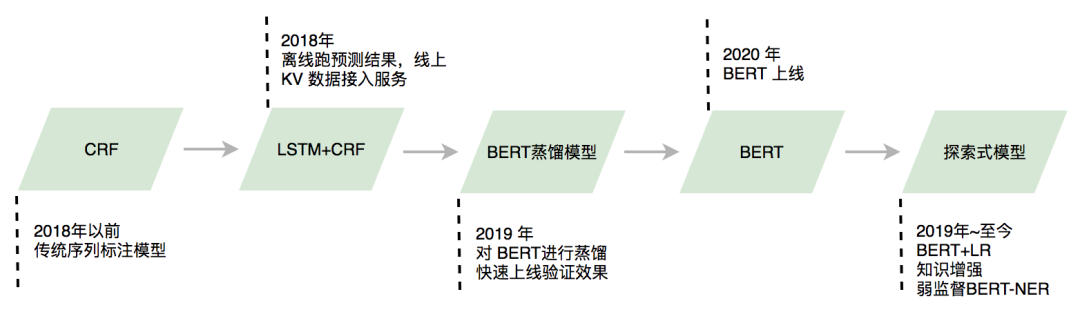
4.1 BERT 模型
BERT 是谷歌於 2018 年 10 月公開的一種自然語言處理方法。該方法一經發布,就引起了學術界以及工業界的廣泛關注。在效果方面,BERT 刷新了 11 個 NLP 任務的當前最優效果,該方法也被評爲 2018 年 NLP 的重大進展以及 NAACL 2019 的 best paper[4,5]。BERT 和早前 OpenAI 發佈的 GPT 方法技術路線基本一致,只是在技術細節上存在略微差異。兩個工作的主要貢獻在於使用預訓練 + 微調的思路來解決自然語言處理問題。以 BERT 爲例,模型應用包括 2 個環節:
- 預訓練(Pre-training) ,該環節在大量通用語料上學習網絡參數,通用語料包括 Wikipedia、Book Corpus,這些語料包含了大量的文本,能夠提供豐富的語言相關現象。
- 微調(Fine-tuning) ,該環節使用“任務相關”的標註數據對網絡參數進行微調,不需要再爲目標任務設計 Task-specific 網絡從頭訓練。
將 BERT 應用於實體識別線上預測時面臨一個挑戰,即預測速度慢。我們從模型蒸餾、預測加速兩個方面進行了探索,分階段上線了 BERT 蒸餾模型、BERT+Softmax、BERT+CRF 模型。
4.1.1 模型蒸餾
我們嘗試了對 BERT 模型進行剪裁和蒸餾兩種方式,結果證明,剪裁對於 NER 這種複雜 NLP 任務精度損失嚴重,而模型蒸餾是可行的。模型蒸餾是用簡單模型來逼近複雜模型的輸出,目的是降低預測所需的計算量,同時保證預測效果。Hinton 在 2015 年的論文中闡述了核心思想 [6],複雜模型一般稱作 Teacher Model,蒸餾後的簡單模型一般稱作 Student Model。Hinton 的蒸餾方法使用僞標註數據的概率分佈來訓練 Student Model,而沒有使用僞標註數據的標籤來訓練。作者的觀點是概率分佈相比標籤能夠提供更多信息以及更強約束,能夠更好地保證 Student Model 與 Teacher Model 的預測效果達到一致。在 2018 年 NeurIPS 的 Workshop 上,[7] 提出一種新的網絡結構 BlendCNN 來逼近 GPT 的預測效果,本質上也是模型蒸餾。BlendCNN 預測速度相對原始 GPT 提升了 300 倍,另外在特定任務上,預測準確率還略有提升。關於模型蒸餾,基本可以得到以下結論:
- 模型蒸餾本質是函數逼近 。針對具體任務,筆者認爲只要 Student Model 的複雜度能夠滿足問題的複雜度,那麼 Student Model 可以與 Teacher Model 完全不同,選擇 Student Model 的示例如下圖 6 所示。舉個例子,假設問題中的樣本(x,y)從多項式函數中抽樣得到,最高指數次數 d=2;可用的 Teacher Model 使用了更高指數次數(比如 d=5),此時,要選擇一個 Student Model 來進行預測,Student Model 的模型複雜度不能低於問題本身的複雜度,即對應的指數次數至少達到 d=2。
- 根據無標註數據的規模,蒸餾使用的約束可以不同 。如圖 7 所示,如果無標註數據規模小,可以採用值(logits)近似進行學習,施加強約束;如果無標註數據規模中等,可以採用分佈近似;如果無標註數據規模很大,可以採用標籤近似進行學習,即只使用 Teacher Model 的預測標籤來指導模型學習。
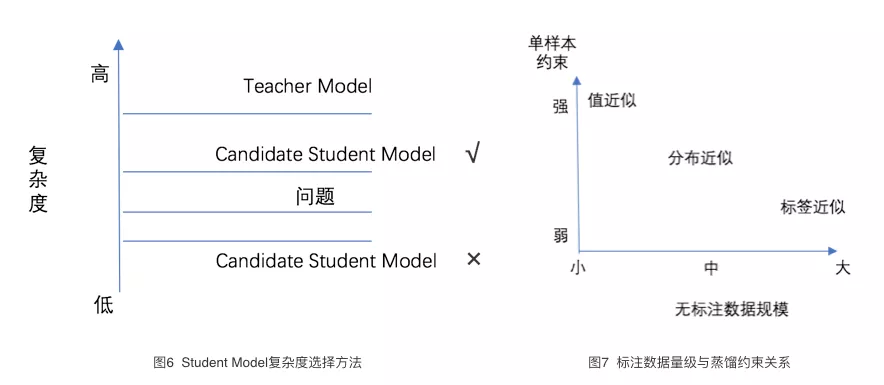
有了上面的結論,我們如何在搜索 NER 任務中應用模型蒸餾呢?首先先分析一下該任務。與文獻中的相關任務相比,搜索 NER 存在有一個顯著不同:作爲線上應用,搜索有大量無標註數據。用戶查詢可以達到千萬 / 天的量級,數據規模上遠超一些離線測評能夠提供的數據。據此,我們對蒸餾過程進行簡化:不限制 Student Model 的形式,選擇主流的推斷速度快的神經網絡模型對 BERT 進行近似;訓練不使用值近似、分佈近似作爲學習目標,直接使用標籤近似作爲目標來指導 Student Model 的學習。
我們使用 IDCNN-CRF 來近似 BERT 實體識別模型,IDCNN(Iterated Dilated CNN)是一種多層 CNN 網絡,其中低層卷積使用普通卷積操作,通過滑動窗口圈定的位置進行加權求和得到卷積結果,此時滑動窗口圈定的各個位置的距離間隔等於 1。高層卷積使用膨脹卷積(Atrous Convolution)操作,滑動窗口圈定的各個位置的距離間隔等於 d(d>1)。通過在高層使用膨脹卷積可以減少卷積計算量,同時在序列依賴計算上也不會有損失。在文本挖掘中,IDCNN 常用於對 LSTM 進行替換。實驗結果表明,相較於原始 BERT 模型,在沒有明顯精度損失的前提下,蒸餾模型的在線預測速度有數十倍的提升。
4.1.2 預測加速
BERT 中大量小算子以及 Attention 計算量的問題,使得其在實際線上應用時,預測時長較高。我們主要使用以下三種方法加速模型預測,同時對於搜索日誌中的高頻 Query,我們將預測結果以詞典方式上傳到緩存,進一步減少模型在線預測的 QPS 壓力。下面介紹下模型預測加速的三種方法:
1. 算子融合:通過降低 Kernel Launch 次數和提高小算子訪存效率來減少 BERT 中小算子的耗時開銷。我們這裏調研了 Faster Transformer 的實現。平均時延上,有 1.4x~2x 左右加速比;TP999 上,有 2.1x~3x 左右的加速比。該方法適合標準的 BERT 模型。開源版本的 Faster Transformer 工程質量較低,易用性和穩定性上存在較多問題,無法直接應用,我們基於 NV 開源的 Faster Transformer 進行了二次開發,主要在穩定性和易用性進行了改進:
- 易用性 :支持自動轉換,支持 Dynamic Batch,支持 Auto Tuning。
- 穩定性 :修復內存泄漏和線程安全問題。
2. Batching:Batching 的原理主要是將多次請求合併到一個 Batch 進行推理,降低 Kernel Launch 次數、充分利用多個 GPU SM,從而提高整體吞吐。在 max_batch_size 設置爲 4 的情況下,原生 BERT 模型,可以在將平均 Latency 控制在 6ms 以內,最高吞吐可達 1300 QPS。該方法十分適合美團搜索場景下的 BERT 模型優化,原因是搜索有明顯的高低峯期,可提升高峯期模型的吞吐量。
3. 混合精度:混合精度指的是 FP32 和 FP16 混合的方式,使用混合精度可以加速 BERT 訓練和預測過程並且減少顯存開銷,同時兼顧 FP32 的穩定性和 FP16 的速度。在模型計算過程中使用 FP16 加速計算過程,模型訓練過程中權重會存儲成 FP32 格式,參數更新時採用 FP32 類型。利用 FP32 Master-weights 在 FP32 數據類型下進行參數更新,可有效避免溢出。混合精度在基本不影響效果的基礎上,模型訓練和預測速度都有一定的提升。
4.2 知識增強的 NER
如何將特定領域的外部知識作爲輔助信息嵌入到語言模型中,一直是近些年的研究熱點。K-BERT[8]、ERNIE[9] 等模型探索了知識圖譜與 BERT 的結合方法,爲我們提供了很好的借鑑。美團搜索中的 NER 是領域相關的,實體類型的判定與業務供給高度相關。因此,我們也探索瞭如何將供給 POI 信息、用戶點擊、領域實體詞庫等外部知識融入到 NER 模型中。
4.2.1 融合搜索日誌特徵的 Lattice-LSTM
在 O2O 垂直搜索領域,大量的實體由商家自定義(如商家名、團單名等),實體信息隱藏在供給 POI 的屬性中,單使用傳統的語義方式識別效果差。Lattice-LSTM[10] 針對中文實體識別,通過增加詞向量的輸入,豐富語義信息。我們借鑑這個思路,結合搜索用戶行爲,挖掘 Query 中潛在短語,這些短語蘊含了 POI 屬性信息,然後將這些隱藏的信息嵌入到模型中,在一定程度上解決領域新詞發現問題。與原始 Lattice-LSTM 方法對比,識別準確率千分位提升 5 個點。
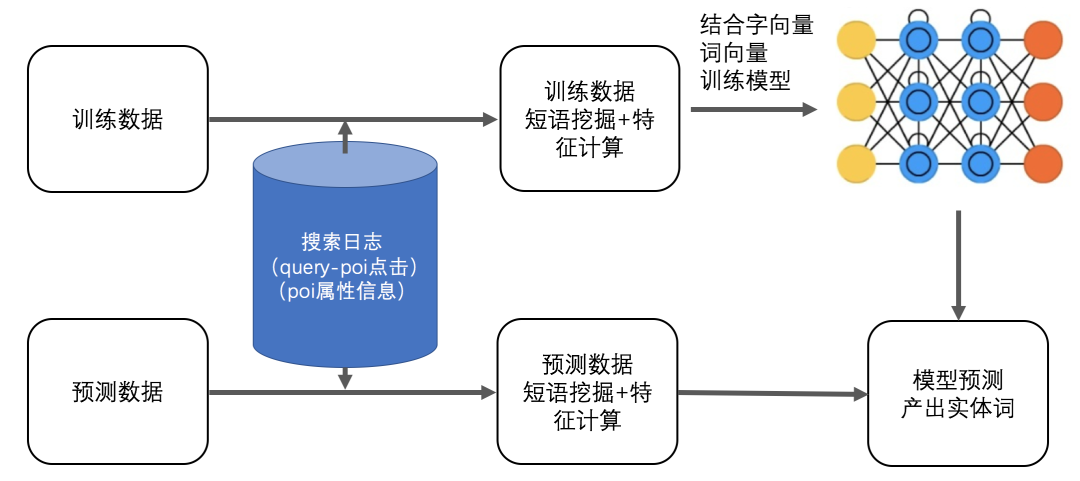
(1)短語挖掘及特徵計算
該過程主要包括兩步:匹配位置計算、短語生成,下面詳細展開介紹。
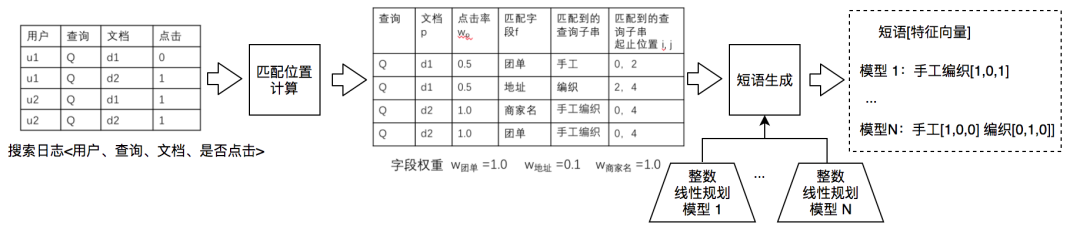
Step1:匹配位置計算。對搜索日誌進行處理,重點計算查詢與文檔字段的詳細匹配情況以及計算文檔權重(比如點擊率)。如圖 9 所示,用戶輸入查詢是“手工編織”,對於文檔 d1(搜索中就是 POI),“手工”出現在字段“團單”,“編織”出現在字段“地址”。對於文檔 2,“手工編織”同時出現在“商家名”和“團單”。匹配開始位置、匹配結束位置分別對應有匹配的查詢子串的開始位置以及結束位置。
Step2:短語生成。以 Step1 的結果作爲輸入,使用模型推斷候選短語。可以使用多個模型,從而生成滿足多個假設的結果。我們將候選短語生成建模爲整數線性規劃(Integer Linear Programmingm,ILP)問題,並且定義了一個優化框架,模型中的超參數可以根據業務需求進行定製計算,從而獲得滿足不用假設的結果。
對於一個具體查詢 Q,每種切分結果都可以使用整數變量 xij 來表示:xij=1 表示查詢 i 到 j 的位置構成短語,即 Qij 是一個短語,xij=0 表示查詢 i 到 j 的位置不構成短語。優化目標可以形式化爲:在給定不同切分 xij 的情況下,使收集到的匹配得分最大化。
優化目標及約束函數如圖 10 所示,其中 p:文檔,f:字段,w:文檔 p 的權重,wf:字段 f 的權重。xijpf:查詢子串 Qij 是否出現在文檔 p 的 f 字段,且最終切分方案會考慮該觀測證據,Score(xijpf):最終切分方案考慮的觀測得分,w(xij):切分 Qij 對應的權重,yijpf : 觀測到的匹配,查詢子串 Qij 出現在文檔 p 的 f 字段中。χmax:查詢包含的最大短語數。這裏,χmax、wp、wf 、w(xij) 是超參數,在求解 ILP 問題前需要完成設置,這些變量可以根據不同假設進行設置:可以根據經驗人工設置,另外也可以基於其他信號來設置,設置可參考圖 10 給出的方法。最終短語的特徵向量表徵爲在 POI 各屬性字段的點擊分佈。

(2)模型結構
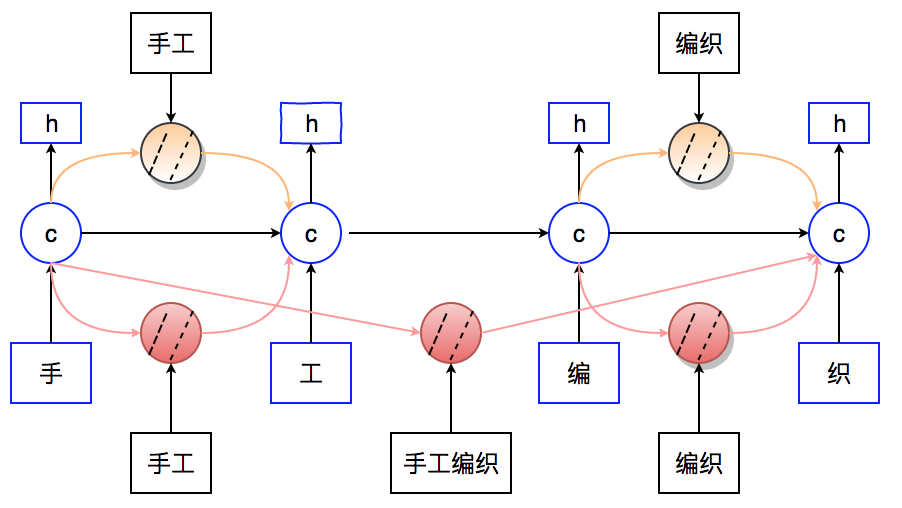
模型結構如圖 11 所示,藍色部分表示一層標準的 LSTM 網絡(可以單獨訓練,也可以與其他模型組合),輸入爲字向量,橙色部分表示當前查詢中所有詞向量,紅色部分表示當前查詢中的通過 Step1 計算得到的所有短語向量。對於 LSTM 的隱狀態輸入,主要由兩個層面的特徵組成:當前文本語義特徵,包括當前字向量輸入和前一時刻字向量隱層輸出;潛在的實體知識特徵,包括當前字的短語特徵和詞特徵。下面介紹當前時刻潛在知識特徵的計算以及特徵組合的方法。(下列公式中,σ表示 sigmoid 函數,⊙表示矩陣乘法)


4.2.2 融合實體詞典的兩階段 NER
我們考慮將領域詞典知識融合到模型中,提出了兩階段的 NER 識別方法。該方法是將 NER 任務拆分成實體邊界識別和實體標籤識別兩個子任務。相較於傳統的端到端的 NER 方法,這種方法的優勢是實體切分可以跨領域複用。另外,在實體標籤識別階段可以充分使用已積累的實體數據和實體鏈接等技術提高標籤識別準確率,缺點是會存在錯誤傳播的問題。
在第一階段,讓 BERT 模型專注於實體邊界的確定,而第二階段將實體詞典帶來的信息增益融入到實體分類模型中。第二階段的實體分類可以單獨對每個實體進行預測,但這種做法會丟失實體上下文信息,我們的處理方法是:將實體詞典用作訓練數據訓練一個 IDCNN 分類模型,該模型對第一階段輸出的切分結果進行編碼,並將編碼信息加入到第二階段的標籤識別模型中,聯合上下文詞彙完成解碼。基於 Benchmark 標註數據進行評估,該模型相比於 BERT-NER 在 Query 粒度的準確率上獲得了 1% 的提升。這裏我們使用 IDCNN 主要是考慮到模型性能問題,大家可視使用場景替換成 BERT 或其他分類模型。
4.3 弱監督 NER
針對標註數據難獲取問題,我們提出了一種弱監督方案,該方案包含兩個流程,分別是弱監督標註數據生成、模型訓練。下面詳細描述下這兩個流程。
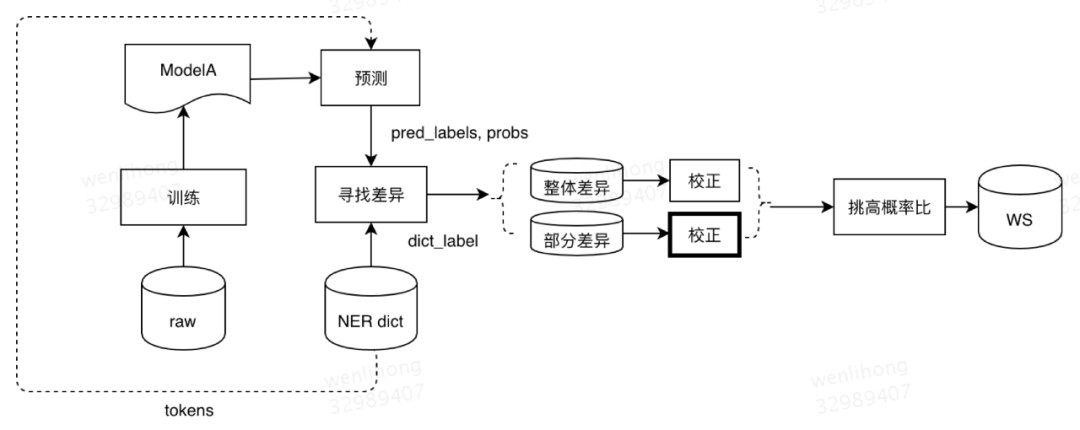
Step1:弱監督標註樣本生成
(1)初版模型:利用已標註的小批量數據集訓練實體識別模型,這裏使用的是最新的 BERT 模型,得到初版模型 ModelA。
(2)詞典數據預測:實體識別模塊目前沉澱下百萬量級的高質量實體數據作爲詞典,數據格式爲實體文本、實體類型、屬性信息。用上一步得到的 ModelA 預測改詞典數據輸出實體識別結果。
(3)預測結果校正:實體詞典中實體精度較高,理論上來講模型預測的結果給出的實體類型至少有一個應該是實體詞典中給出的該實體類型,否則說明模型對於這類輸入的識別效果並不好,需要針對性地補充樣本,我們對這類輸入的模型結果進行校正後得到標註文本。校正方法我們嘗試了兩種,分別是整體校正和部分校正,整體校正是指整個輸入校正爲詞典實體類型,部分校正是指對模型切分出的單個 Term 進行類型校正。舉個例子來說明,“兄弟燒烤個性 diy”詞典中給出的實體類型爲商家,模型預測結果爲修飾詞 + 菜品 + 品類,沒有 Term 屬於商家類型,模型預測結果和詞典有差異,這時候我們需要對模型輸出標籤進行校正。校正候選就是三種,分別是“商家 + 菜品 + 品類”、“修飾詞 + 商家 + 品類”、“修飾詞 + 菜品 + 商家”。我們選擇最接近於模型預測的一種,這樣選擇的理論意義在於模型已經收斂到預測分佈最接近於真實分佈,我們只需要在預測分佈上進行微調,而不是大幅度改變這個分佈。那從校正候選中如何選出最接近於模型預測的一種呢?我們使用的方法是計算校正候選在該模型下的概率得分,然後與模型當前預測結果(當前模型認爲的最優結果)計算概率比,概率比計算公式如公式 2 所示,概率比最大的那個就是最終得到的校正候選,也就是最終得到的弱監督標註樣本。在“兄弟燒烤個性 diy”這個例子中,“商家 + 菜品 + 品類”這個校正候選與模型輸出的“修飾詞 + 菜品 + 品類”概率比最大,將得到“兄弟 / 商家 燒烤 / 菜品 個性 diy/ 品類”標註數據。


Step2:弱監督模型訓練
弱監督模型訓練方法包括兩種:一是將生成的弱監督樣本和標註樣本進行混合不區分重新進行模型訓練;二是在標註樣本訓練生成的 ModelA 基礎上,用弱監督樣本進行 Fine-tuning 訓練。這兩種方式我們都進行了嘗試。從實驗結果來看,Fine-tuning 效果更好。
5. 總結和展望
本文介紹了 O2O 搜索場景下 NER 任務的特點及技術選型,詳述了在實體詞典匹配和模型構建方面的探索與實踐。
實體詞典匹配針對線上頭腰部流量,離線對 POI 結構化信息、商戶評論數據、搜索日誌等獨有數據進行挖掘,可以很好的解決領域實體識別問題,在這一部分我們介紹了一種適用於垂直領域的新詞自動挖掘方法。除此之外,我們也積累了其他可處理多源數據的挖掘技術,如有需要可以進行約線下進行技術交流。
模型方面,我們圍繞搜索中 NER 模型的構建的三個核心問題(性能要求高、領域強相關、標註數據缺乏)進行了探索。針對性能要求高採用了模型蒸餾,預測加速的方法, 使得 NER 線上主模型順利升級爲效果更好的 BERT。在解決領域相關問題上,分別提出了融合搜索日誌、實體詞典領域知識的方法,實驗結果表明這兩種方法可一定程度提升預測準確率。針對標註數據難獲取問題,我們提出了一種弱監督方案,一定程度緩解了標註數據少模型預測效果差的問題。
未來,我們會在解決 NER 未登錄識別、歧義多義、領域相關問題上繼續深入研究,歡迎業界同行一起交流。
6. 參考資料
[1] Automated Phrase Mining from Massive Text Corpora. 2018.
[2] Learning Named Entity Tagger using Domain-Specific Dictionary. 2018.
[3] Bidirectional Encoder Representations from Transformers. 2018
[4] https://www.jiqizhixin.com/articles/2018-12-30
[5] https://naacl2019.org/blog/best-papers/
[6] Hinton et al.Distilling the Knowledge in a Neural Network. 2015.
[7] Yew Ken Chia et al. Transformer to CNN: Label-scarce distillation for efficient text classification. 2018.
[8] K-BERT:Enabling Language Representation with Knowledge Graph. 2019.
[9] Enhanced Language Representation with Informative Entities. 2019.
[10] Chinese NER Using Lattice LSTM. 2018.
作者介紹:
麗紅,星池,燕華,馬璐,廖羣,志安,劉亮,李超,張弓,雲森,永超等,均來自美團搜索與 NLP 部。


