並非里程碑!Facebook100種語言互譯模型誇大宣傳遭質疑

歡迎關注“創事記”的微信訂閱號:sinachuangshiji
文/reddit
來源:新智元(ID:AI_era)
【新智元導讀】昨天,Facebook宣佈其最新的神經機器翻譯模型不依賴英語就能實現100種語言的互譯,並稱之爲「里程碑式」進展。今天就有網友發帖質疑,「里程碑」的說法有點誇大宣傳,「不依賴英語」也不夠準確,對前輩谷歌在該領域的研究更是隻字未提。
Facebook又翻車了?
昨天,Facebook剛剛宣佈其機器翻譯取得里程碑式進展,可在100種語言之間實現互譯,並且不依賴英語這個「中介」,今天reddit網友就來掀車了。

該網友稱,Facebook此前也有過誇大宣傳,但這次有點過了。
Facebook 的100種語言互譯並非里程碑?
Facebook聲稱,最新的模型可直接進行多達100種語言的機器翻譯,比如從漢語到法語,且訓練的時候的無需英語作爲中介。在評估機器翻譯廣泛使用的 BLEU 指標上,它比以英語爲中心的翻譯系統性能高出10個百分點。
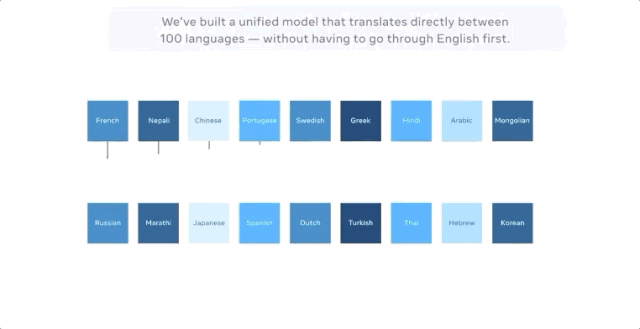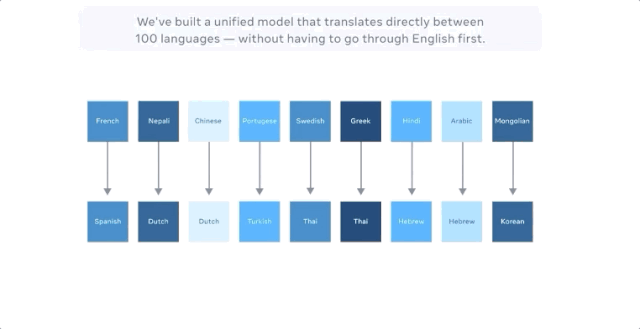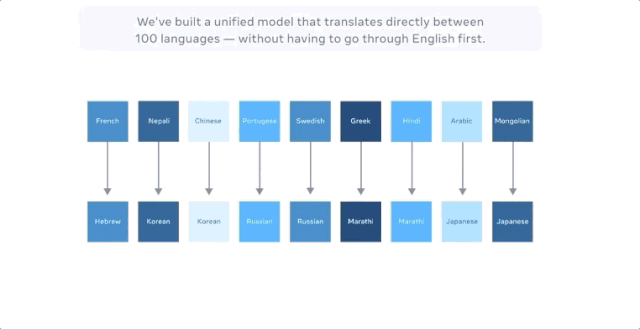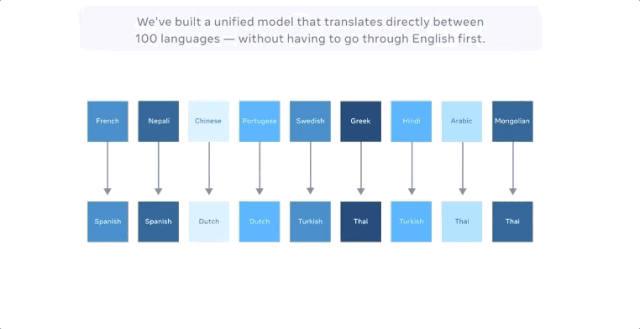
而FacebookAI實驗室的博客中並未提及,谷歌早在4年前就做了這件事。

谷歌在16年發佈的這一研究成果,也是一個端到端的學習框架,從數以百萬計的例子中學習,並顯著提高了翻譯質量。
這個翻譯系統不僅提高了測試數據上的翻譯質量,而且可以支持103種語言的互譯,每天翻譯超過1400億個單詞。雖然還面臨一些問題,但是谷歌確實做到了100種語言。
那我們來看看,谷歌的這套系統是如何運作的。
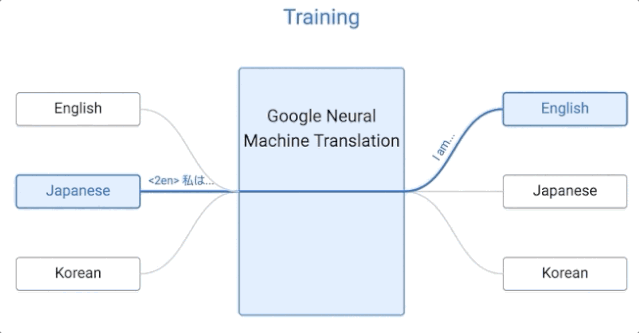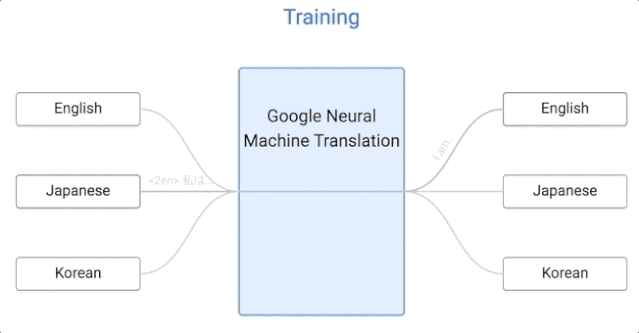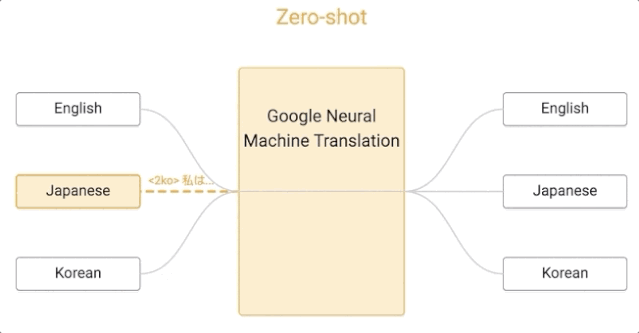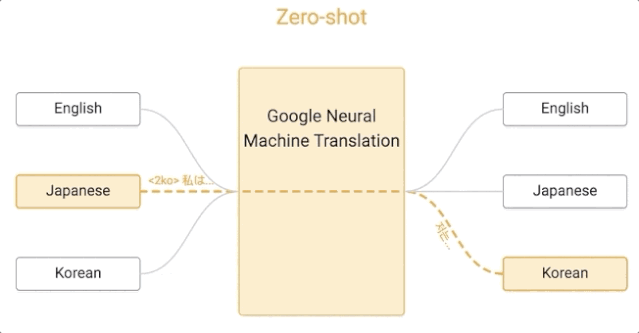
谷歌的這一算法是零樣本學習的,假設我們用日語、英語和韓語的例子來實現一個多語言翻譯系統,與單個 GNMT 系統的大小相同,它通過共享參數來在這幾個不同的語言對之間進行翻譯。這種共享使系統能夠將「翻譯經驗」從一種語言對轉移到另一種語言對。
「Facebook宣稱的不依賴英語數據,也是不準確的」。
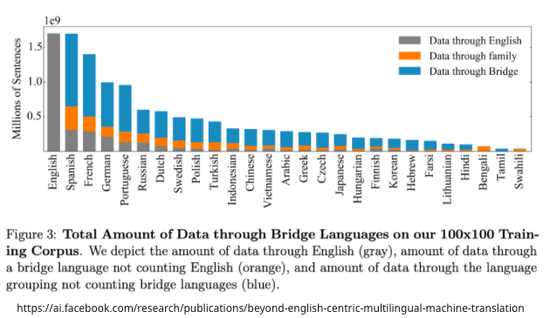
Facebook的論文圖表顯示,使用的數據集中有一部分是包含英語的,要說完全沒有依賴英語,有點抹殺英語起到的作用了。
到目前爲止,谷歌有論文討論關於103種語言的訓練,以及一篇不「依賴英語數據」的單獨論文。

谷歌2019年發表的大規模多語言機器翻譯,支持103種語言,但是源語言或者目標語言是英語。
從技術準確性的角度來看,的確很難找到一篇能同時滿足兩個要求的論文: 不依賴英語數據和超過100種語言。
網友認爲,一個非誤導性的說法應該是,「Facebook 創造了一個巨大的NMT 數據集,並在上面訓練一個Transformer。」
不管Facebook的說法準不準確,它的模型效果確實比以前更好了,也開源了相關的數據集和代碼,有計算資源的同學可以去驗證一下。
那麼,人類翻譯會被機器翻譯所取代嗎?
機器翻譯將全面取代人類翻譯?想多了!
隨着機器翻譯技術的不斷進步,這也成爲越來越多的人尤其是翻譯行業的人,最關心的問題。
這並非「杞人憂天」。
無論是Facebook最近開源的M2M-100模型,還是谷歌之前發佈的支持103種語言的AI翻譯,都顯示出機器翻譯在取代人類翻譯上的巨大可能性。
不過,就機器翻譯目前的發展情況來看,想要完全取代人類翻譯還是不太現實的。
從技術上來看,目前機器翻譯還存有很多技術難點亟待攻克,比如語序混亂、詞義不準確、孤立地進行句法分析等。
從實際應用上來看,在一些偏口語化的翻譯場景、對專業知識背景要求比較高的場景以及大段對話的場景,機器翻譯都無法做到準確而迅速的翻譯。
此前就有媒體爆料出許多機器翻譯的「翻車」事件,例如大型會議的機器同傳翻譯出現大段語句不通的內容,一些人名無法識別,一些日常對話也被翻譯得啼笑皆非…
儘管從表現上來看不那麼盡如人意,但機器翻譯的快速發展無疑會淘汰掉一批低水平的人類翻譯者,那些只能進行「低端」翻譯的人類翻譯者無疑會被機器翻譯所替代。
而真正的高水平翻譯者則完全不需要擔心這個問題。即便是目前最先進的機器翻譯,距離「信、達、雅」的翻譯要求也還有很大差距。
相反,機器翻譯可以把高水平的翻譯者們從一些機械、枯燥的簡單翻譯工作中解放出來,讓機器翻譯成爲工具,抽出精力去從事更富有創造性的工作。

實際上,未來的譯者可能更接近編輯和質量把關專家,更多的是對機器翻譯的初稿進行修改潤色和文學創作。
總而言之,機器翻譯全面取代人類翻譯目前來看是個沒譜的事。
AI公司喜歡誇大宣傳,人工智能基於「ifelse」?
Facebook這個看似要替代人類翻譯的模型,引起了不少討論。
有網友甚至認爲機器學習領域總是被輿論誤導。

一些大公司的研究或者發聲更容易被聽到,甚至在論文接受上,也享有一定的優勢。

雖然現在大多數頂會的論文審覈都是雙盲的,但是審稿人很容易判斷作者的背景情況,比如說論文中的模型使用了幾千個TPU,那來自大廠無疑了。
谷歌、Facebook這樣的大型科技公司確實佔據了很多有利地位。
一些AI公司喜歡利用這些論文,誇大AI在實際中的作用。
而且新聞稿有時是由非研究人員根據有限的描述或論文摘要撰寫的,可能沒有進行任何事實覈查,導致一定的偏差。
之前,推特上有一條點Uber的消息吸引了不少關注,這則推文引用了一份新聞稿,其中指出:「Uber 將使用人工智能來識別醉酒的乘客,AI系統使用當前時間、上車地點以及用戶的猶豫時間等參數來判斷。」

下面寫了一句:「那不是AI。那只是if語句而已」,還給出了實現這一智能識別系統的代碼,一共需要兩行:

事實上可能並不這麼簡單。
Uber 可能會使用機器學習,並根據以往的數據來微調模型的權重,還可以把錯誤的判斷用來更新預測模型,但是有些AI應用的確沒有論文中那麼好。
那麼,你寫過基於ifelse的人工智能應用嗎?