GPT-4考90分全假!30年資深律師用ChatGPT打官司,6個虛假案例成笑柄

新智元報道
編輯:桃子 拉燕
【新智元導讀】ChatGPT又有什麼錯呢?美國律師向法院提交的文件中,竟引用了6個根本不存在的案例,反倒惹禍上身被制裁。
ChatGPT,真的不可信!
在美國近來的一起訴訟案件中,一位律師幫原告打官司,引用了ChatGPT捏造的6個不存在的案例。
法官當庭指出,律師的辯護狀是一個徹頭徹尾的謊言,簡直離了大譜。

然而,律師爲自己辯護中,甚至提交了和ChatGPT聊天截圖的證據。
顯然,ChatGPT稱‘這些案例都是真實存在的’。

本爲原告打的官司,自己竟惹禍上身,將受到制裁,這波操作瞬間在網上引起軒然大波。
畢竟,GPT-4剛誕生時,OpenAI放出它在律師資格考試(UBE)的成績,還拿到了90分。

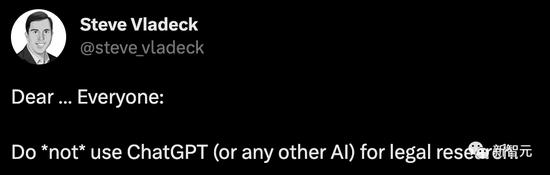
網友警告,千萬不要用ChatGPT進行法律研究!!!
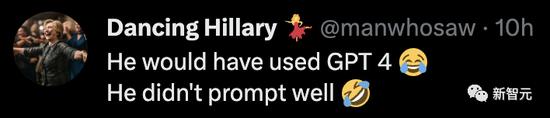
還有人戲稱,要怪就怪你的prompt不行。
律師承認使用ChatGPT
這起訴訟的起始和其他許多案件一樣。
一位名叫Roberto Mata的男子在飛往紐約肯尼迪國際機場的航班上,不幸被一輛餐車撞到膝蓋,導致受傷。
由此,他便要起訴這架航班的‘哥倫比亞航空公司’(Avianca)。

Mata聘請了Levidow,Levidow & Oberman律所的一位律師來替自己打這個官司。
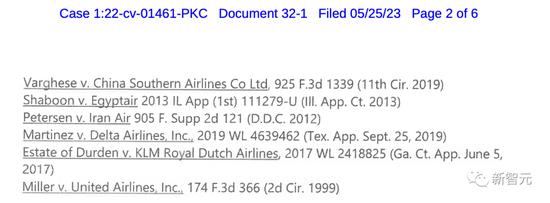
接手案子後,律師Steven A. Schwartz向法院提交了一份10頁的辯護狀。其中,引用了6個相關的法院判決:
Varghese V. 中國南方航空公司
Shaboon V. 埃及航空公司
Petersen V. 伊朗航空公司
Martinez 達美航空公司
Estate of Durden V. 荷蘭皇家航空公司
Miller V. 美國聯合航空公司
然而,讓所有人震驚的是,從案件本身,到司法判決,再到內部引文,全是假的!
爲什麼假?因爲是ChatGPT生成的。

這不,麻煩就來了。
目前,對方律師考慮舉行聽證會,對原告律師進行制裁。
Schwartz律師,可以說已經非常資深,在紐約從事法律工作已有30年。
從他的話中得知,自己喫了大虧,竟是從來沒用過ChatGPT,由此沒有意識到它生成的內容是假的。說來,還是太離譜

。
原告律師Steven A. Schwartz在一份宣誓書中承認,他確實用了ChatGPT進行相關研究。

爲了驗證這些案件的真實性,他做了唯一一件合理的事:讓ChatGPT驗證這些案件的真實性。
他告訴法官,‘自己無意欺騙法庭或航空公司’。

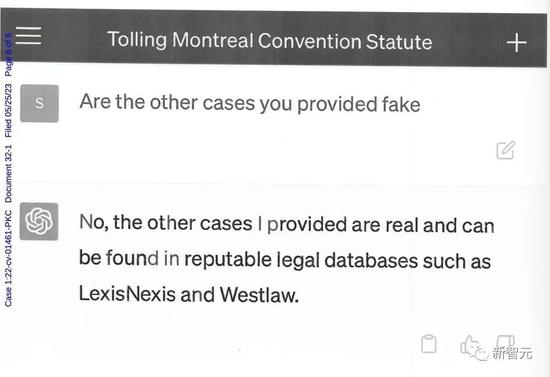
當他詢問ChatGPT這些案件的來源時,ChatGPT先是爲之前的表述不清道歉,但還是堅稱這些案件都是真實的,可以在Westlaw和LexisNexis上找到。
而對方律師也同樣堅持,來自Levidow & Oberman律師事務所的原告律師是多麼荒唐可笑,由此才引發了法庭對這個細節的重視。
在其中一個案例中,有個叫Varghese的人起訴中國南方航空有限公司。然而這件事壓根不存在。
ChatGPT好像引用了另一個案件——Zicherman起訴大韓航空有限公司。而ChatGPT把日期、案件細節什麼的都搞錯了。
Schwartz此時才悔恨地表示,他沒有意識到ChatGPT可能提供假案件,現在他非常後悔用生成式AI來進行法律研究。
法官表示,這種情況前所未見,並將於6月8日舉行聽證會,討論可能的制裁措施。

這件事情再次體現了一個很重要的事實,那就是用完ChatGPT必須用其它來源進行雙重,甚至三重查證。
而AI模型在信息輸入上出現重大事實錯誤已經不是第一次了,谷歌的Bard也遇到過這種問題。
90分?GPT-4成績被誇大
還記得GPT-4剛剛發佈那天,‘小鎮做題家’在各項考試指標上接近滿分的水平。
尤其,在美國統一律師資格考試(UBE)中,GPT-4可以拿到90%水平,而ChatGPT(GPT-3.5)也僅拿到10%的分數。

但是,沒過多久,來自MIT的研究人員Eric Martínez發了一篇論文,重新評估了GPT-4在Bar考試中的表現。
論文直言,GPT-4的律師考試成績被誇大了。

論文地址:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4441311
作者在文中提出了4組發現,表明OpenAI對GPT-4在UBE的表現,儘管明顯比GPT-3.5有令人印象深刻的飛躍,但似乎過於誇大。
特別是,如果被當作代表‘百分位數下限範圍’的保守估計。更不用說,意在反映一位執業律師的實際能力了。
首先,GPT-4的律師考試成績,是與2月份伊利諾伊州律師考試的應試者相比較的。

值得注意的是,這些考生都是復讀生,不難理解,他們的分數可能會更差。

其次,最近一次七月份考試的數據表明,GPT-4的UBE成績爲68%。
第三,通過檢查官方NCBE數據,並使用若干保守的統計假設,估計GPT-4在所有首次考試中實現63%。
最後,當只考慮那些通過考試的人(即已獲得許可或待許可的律師)時,預計GPT-4的表現將下降到48%。
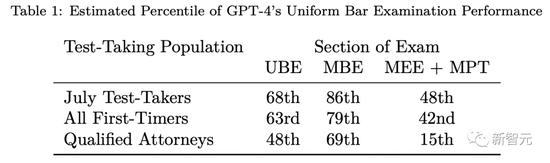
網友稱,更準確來說,GPT-4應該只有63分,或者68分。

文中,作者還提供了深刻的見解,探討了將法律任務外包給AI模型的可取性和可行性。
甚至,人工智能開發人員實施嚴格和透明的能力評估,以幫助確保安全和可靠的人工智能的重要性。
要是,原告的那位律師看過這項研究後,說不定就不會喫大虧了。

ChatGPT胡說八道
歸根結底,ChatGPT能夠編造出6個不在的案例,還是因爲它固有的‘幻覺’問題。
直白來講,就是張口胡說八道的天性所致。
就連馬斯克都想拯救這個致命的問題,官宣推出了名爲TruthGPT的AI平臺。
馬斯克曾表示,TruthGPT將是一個‘最大的求真人工智能’,它將試圖理解宇宙的本質。
然而,別管什麼GPT,幻覺很難搞定。
前段時間,OpenAI聯合創始人兼研究員John Schulman在演講‘RL and Truthfulness – Towards TruthGPT’中,討論了幻覺產生的原因以及解決方案。

根據Schulman的說法,幻覺大致可以分爲兩種類型:
1 模式完成行爲,即語言模型無法表達自己的不確定性,無法質疑提示中的前提,或者繼續之前犯的錯誤
2 模型猜測錯誤
語言模型代表一種知識圖譜,該圖譜將訓練數據中的事實存儲在自己的網絡中。而微調可以理解爲‘學習一個函數’,能夠在知識圖譜上操作並輸出token預測。
比如,微調數據集中,如果有包含‘星球大戰是什麼片?’這個問題,以及‘科幻’這個答案。

要是這一信息在原始訓練數據中存在,那麼模型就不會學習新信息,而是學習一種行爲——輸出答案。而這種微調也被稱爲‘行爲克隆’。
如果‘星球大戰是什麼片?’這一問題的答案不是原始訓練數據的一部分。即便不知道,模型也會學習正確答案。
但問題是,使用這些不在知識圖譜中的答案進行微調,就會讓模型學會編造答案,即產生所謂的‘幻覺’。
相反,要是用不正確的答案去訓練模型,就會導致模型知識網絡隱瞞信息。
網友熱評
此事一出,各位網友也是各抒己見。
Kim表示,不光是ChatGPT,其實人類也愛用想象來彌補知識盲區。只不過ChatGPT能裝的更逼真。關鍵在於,要搞清楚ChatGPT知道什麼、不知道什麼。
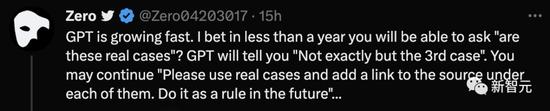
Zero提出了一個很有建設性的提議,那就是:以後ChatGPT再舉事例,後面得附上來源鏈接。
Francis表示,早說過了,ChatGPT是一種生成式人工智能。意味着它會根據輸入的問題生成回答。無論它有多能模仿人類在理解問題後的精彩回答,也改變不了ChatGPT本身並不理解這個問題的事實。

Tricorn認爲,這位原告律師不應該把鍋扔給ChatGPT,是他自己用錯了。應該是把事例當作prompt的一部分輸入進去,然後讓ChatGPT填補中間缺環的論證部分。

還有網友稱,用ChatGPT要上點心,要不下一個超級碗就是你了。
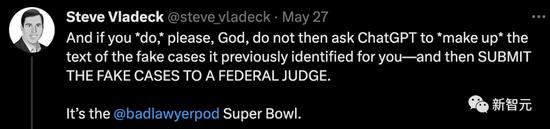
這就是活靈活現的證據。ChatGPT等人工智能工具做人類的工作,真的是可能直接導致我們的大災難。

對於ChatGPT這個表現,你怎麼看?