“不遜色 GPT-4”!百度最強大模型發佈,我們第一時間實測了一波
就在剛剛,文心大模型 4.0 版本正式發佈!
北京首鋼園現場,李彥宏直接放話:

話不多說,一起來看現場演示效果。
先來段倒裝 prompt:
不僅關鍵信息“北京工作”放在了最後,公積金具體是在哪裏交的也沒有明示。
但新版文心一言完全沒有被這些小陷阱坑到,順利給出了正確答案。

生成方面,當場剪出一整段數字人口播視頻,毫不費勁:

解起數學題來也得心應手,可以說是家長輔導作業神器了(doge)。

新版文心一言還現場寫起了武俠小說,即使持續添加人物角色、增加戲劇衝突,也不會出現記憶混亂、前言不搭後語的情況:

如此表現,着實是讓現場觀衆 high 了一把。
文心大模型 4.0 相關話題,也立刻被國內外網友們熱議起來。

據現場介紹,相比線上 3.5 版本的文心一言,文心大模型 4.0 進步明顯:僅 9 月啓動小流量測試這過去的一個月,就又提升了 30%。
那麼,問題來了:文心大模型 4.0 真有這麼好?具體與 GPT-4 相差幾何?
目前,文心大模型 4.0 已經開啓邀測,量子位也在第一時間拿到了測試資格。
我們直接實測走起。
獲得測試資格後,切換到文心大模型 4.0,就可以開始玩耍了。

相比文心大模型 3.5 剛出來的時候,文心大模型 4.0 現在已經進化出了更多功能,光是插件就有 8 個,包括一鏡流影(文字轉視頻)、說圖解畫(看圖說話)、E 言易圖(可視化數據分析)等。
這些插件還可以自由組合,來完成更復雜的任務。

百度在世界大會現場,重點演示的還是文心大模型 4.0 的圖文創作、數理邏輯推理等實用功能。那我們還是老樣子,從更基礎的角度出發,測測它的四大“基本功”——
理解、生成、邏輯和記憶能力。
理解能力,尤其是中文理解能力
第一波,先來看看文心大模型 4.0 的理解能力。
這裏我們主要考考它應對“語言陷阱”的能力,以及網絡段子的“識別力”。
先來個中文十級能力測試題,考考大模型究竟懂不懂“真的假的”是什麼意思。

文心大模型 4.0 的回答很簡潔,直接給出答案。

GPT-4 則要每一句話都仔細分析句意,最後再給出回答:

雖然更仔細,但總感覺有點像是在認真做中文測試的歪果仁(doge)。
再來上點難度,“小偷偷偷偷東西”。
文心大模型 4.0 很快拆解出了“小偷”、“偷偷”和“偷東西”三個詞,get 到了這句話的意思:

不過,GPT-4 反而一頭“栽”進了這個陷阱中,以爲中間的兩個“偷”也是動詞,最後還漏了一個偷……

考查完語言陷阱後,再來看看雙方對網絡段子的理解。
針對“哪李貴了”這個本土梗,文心大模型 4.0 很快給出了答案,人物事件都直觀:

GPT-4 如果沒有開搜索,會 get 不到 2022 年 1 月之後的梗:

但如果打開搜索,很快也能“與時俱進”,給出這個問題的答案:

同理,我們也試了試從國外傳入國內的梗。
文心大模型 4.0 和 GPT-4 都能回答出來,文心大模型 4.0 更概要一些,GPT-4 則是直接搬運了一套百科(更詳細,但 tokens 也更貴💰……):


網絡段子測評看下來,文心大模型 4.0 和加了搜索的 GPT-4 可以說是各有千秋。
多模態生成能力
那麼接下來這波,就要考驗當下最受關注的大模型多模態生成能力了。
先來試試圖像生成能力,順便考查一下對古詩“孤舟蓑笠翁,獨釣寒江雪”的理解。
文心大模型 4.0 很快給出了 4 張圖像,風格和基本意境都比較符合:

GPT-4 也利用 DALL・E 3 畫出了 4 幅畫,同樣畫風各異:

這一次雙方打了個平手。
那麼視頻生成呢?這裏我們調用一下文心大模型 4.0 的自帶插件,本想着只是生成一段落葉剪輯,沒想到連文案和字幕語音都配好了,完成度很高那種:
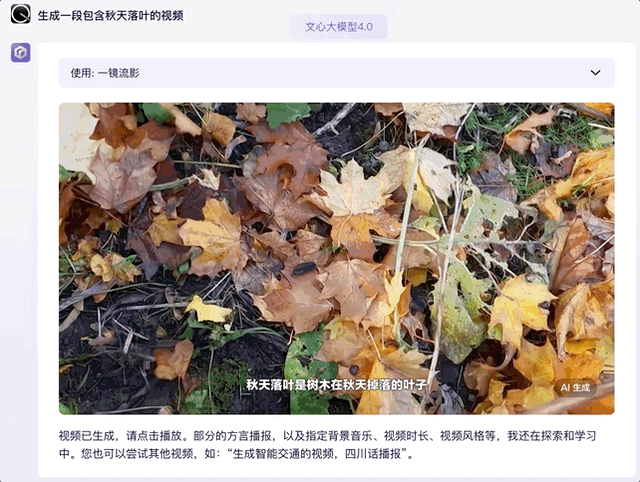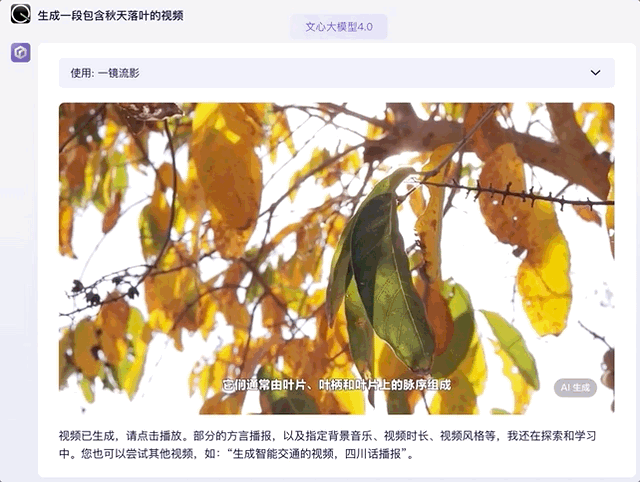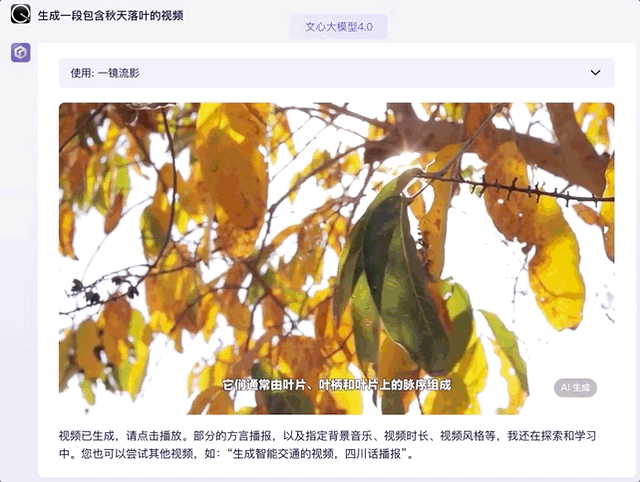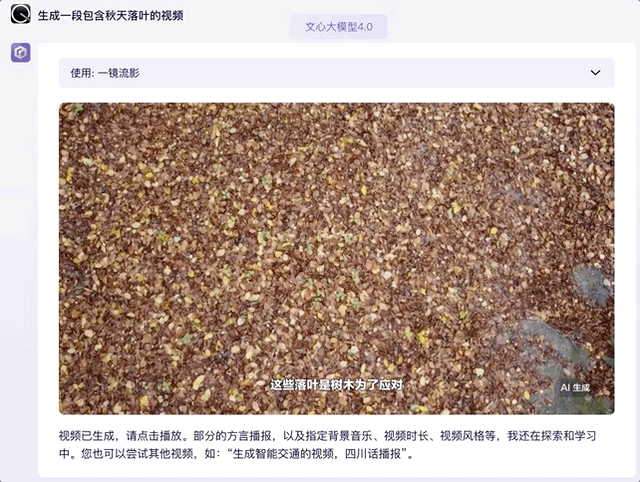
GPT-4 本體目前還不支持生成視頻,需要藉助外部插件(如 Capcut)實現這一功能。

邏輯能力
然後,就到了我們喜聞樂見的數學計算 + 邏輯推理能力測試了。
文心大模型 4.0 說是重點升級了數學計算能力,我們也不客氣,直接上難倒一片大模型的 Old McDonald 問題:
文心大模型 4.0 一口氣列出了 4 個未知數(doge),但解題過程還是比較嚴謹的,最終答案也沒有問題。

此前,我們曾將這個問題餵給 Claude、ChatGPT 等一衆大模型,“橫向評測”過一波它們的數學能力,當時只有 GPT-4 能做出來。

接下來,直接上弱智 benchmark,考考邏輯推理能力。
第一個問題,文心大模型 4.0 和 GPT-4 都很快給出了正確答案:


第二個問題,雙方的回答也很快,文心大模型 4.0 還順口給出了“七分海洋三分陸地”的地理題背誦口訣:


看起來雙方的數學、邏輯都不錯,點個贊。
記憶能力
大語言模型公認的評判標準之一,是多輪對話能力。GPT-4 的多輪對話已經有不少測試了,我們再來簡單看看文心大模型 4.0 的效果。
先來解讀一下長論文,沒什麼問題:

以這個爲主題寫一首詩歌,順便讓它改成英文,也能 hold 住:

試試讓它改得押韻一點,no problem:

最後再來提問一下詩歌中用到的 Transformer 知識點,並挑出其中的某個知識點要求解釋原理,也信手拈來:


另外,試着將上文中的知識點用“它”代替,文心大模型 4.0 同樣能承接上文的對話,並給出相關知識回答。

看來無論是長文本解讀、還是多輪對話,可以說都是難不倒文心大模型 4.0 了。
附加題
正經測試完畢,咱們最後整點樂子(doge)。
這段時間,一道神奇的考題又被拎出來,在小紅書等社交媒體上“難倒衆人”,題面是這樣的:
乍一眼還真看不出答案,不如交給文心大模型 4.0 和 GPT-4 回答試試。
文心大模型 4.0 給出的回答算是有理有據,雖然細看仍有一點 bug,但整體問題不大。

然而當我們將這個問題拋給 GPT-4 的時候,它先是停頓了好一會,然後直接被“急出母語”(doge)

翻譯一下大概就是,GPT-4 認爲 D 選項是正確的……

我們再嘗試一遍。這次 GPT-4 倒是用中文回答了,只不過好像開始打起了太極,對於每一個選項,它的回答都是:

測到這裏,不妨做個小小的總結:
整體來看,與 GPT-4 相比,文心大模型 4.0 在綜合能力上確實不落下風,尤其是在中文理解能力和通用知識能力上甚至更好。
那麼,這樣的大模型究竟是怎麼煉成的呢?
先來看看文心大模型 4.0 的“自進化”程度。
據百度 CTO 王海峯介紹,大模型表現出的創作、編程、解題、規劃等能力,實際上都依賴於背後的 4 大核心基礎能力 ——
理解、生成、邏輯和記憶能力。
相比 3.5 版本,文心大模型 4.0 的 4 大基礎能力均有了不少提升,而提升最大的,又要屬邏輯和記憶能力。
其中,邏輯的提升幅度達到了理解的近 3 倍,而記憶的提升幅度則達到了理解的 2 倍多:

以大模型寫代碼爲例。
目前,百度的不少員工已經用上了大模型寫代碼應用 Comate,平均代碼採納率達到 40%,高頻用戶達到 60%。
甚至現在百度每天新增的代碼中,20% 都是靠 Comate 生成的,比例還在不斷增加。

所以,文心一言背後的文心大模型 4.0,究竟是怎麼煉成的?
據王海峯表示,核心架構雖然還是從文心大模型 3.0 和 3.5 一脈相承,包括最初 3.0 的有監督精調、基於人類反饋的強化學習,以及 3.5 的知識點增強、邏輯推理增強、插件機制等。
但文心大模型 4.0 的技術改進,可以直接用三個“更”來總結:

訓練上,目前飛槳平臺已經能在萬卡算力上運行,基於集羣基礎設施、調度系統、軟硬件協同優化,支持大規模穩定高效訓練;同時,基於可再生訓練技術中的增量式參數調優,來節省訓練資源和時間。
基於這套技術,自 3 月份以來,文心大模型系列訓練算法已經累計提效 3.6 倍,周均訓練穩定有效率超過 98%:

數據上,團隊建設了一套多維數據體系,從數據挖掘、分析、合成標註和到評估,形成了一整套“流水線”,來進一步提升模型訓練效果。
算法上,則基於有監督、精調、偏好學習和強化學習等技術,進行了多階段的對齊,確保大模型能更好地與人類判斷和選擇進行對齊。
在這其中,有兩方面很關鍵的技術細節。
一方面是知識點增強的能力。
過去大模型可能只在一個階段做知識點增強,但現在百度在輸入和輸出兩方面同時進行了知識點增強。
輸入先用知識點增強,對用戶輸入的問題進行理解,拆解出回答問題所需知識點,基於搜索引擎、知識圖譜、數據庫查找知識,生成第一遍結果;
輸出再用知識點增強,對第一遍生成的結果進行分析,並用搜索引擎、知識圖譜、數據庫進行“double check”,對其中有差錯的地方進行修正。
另一方面是智能體機制。
《思考,快與慢》這本書中,將認知系統分成系統 1(反應快但易出錯)、系統 2(反應慢但更理性準確)。
根據這個原理,百度在大模型基礎上,進一步研製了系統 2。
也就是說,相比大模型直接給出答案,現在進一步讓它學會理解、規劃、反思和進化,這樣大模型執行就能更可靠、甚至完成自我進化,思考過程“白盒化”。
這兩大技術細節,也造就了文心大模型 4.0 水平的飛速提升,甚至光是過去一個月的時間裏,就提升了 30%。

這樣的技術,也讓文心大模型 4.0 的用戶和開發者人數增長得飛快。
截至目前,文心一言用戶規模已經達到 4500 萬人,開發者達到 5.4 萬人,遍佈 4300 多個使用場景,應用數量達到 825 個,並接入了超過 500 個插件。

而在技術之外,更值得關注的是,百度世界大會上透露出的信息顯示,文心大模型 4.0 已經全面重構了百度的搜索、GBI、文庫、網盤、地圖等數十款應用。

爲什麼這麼說?李彥宏在百度世界大會現場分享時強調:
無獨有偶,紅杉資本在《生成式 AI 進入第二階段》中同樣認爲,生成式 AI 市場正在進入“第二幕”:
底層的邏輯其實很簡單:底層技術的重要性毋庸置疑,但前沿技術想要真正在人們的生活中創造價值,還是需要通過應用的形式。
如果說,大模型掀起的是人機交互方式變革的風暴,那麼 AI 原生應用,正是純自然語言交互的具體體現形式。
正如百度現場所演示的,數據分析現在可以是醬嬸的 ——
直接對任意數據提問,AI 分分鐘就能展開具體分析,不再需要人工跨數據庫、跨表格分析。

在辦公軟件如流裏,交代出行計劃,AI 超級助手立馬就能把差旅機酒安排妥當。

根據文檔生成 PPT,也就是一句話的事,像百度文庫這樣的產品,直接化身“生產內容最好的起點”。

我們日常熟悉的網盤、地圖等 App,基於大模型能力,也湧現出了全新的體驗。
比如從網盤視頻裏直接提取重點內容。

比如在地圖指揮 AI 訂餐廳。
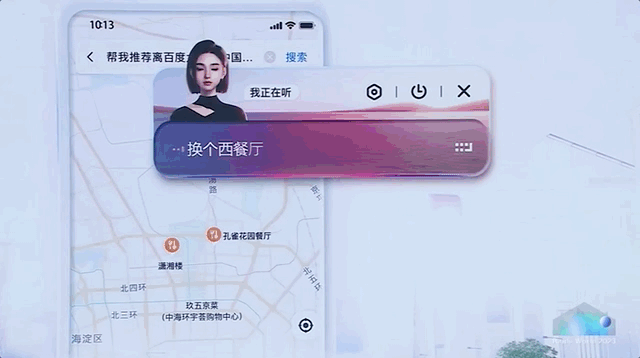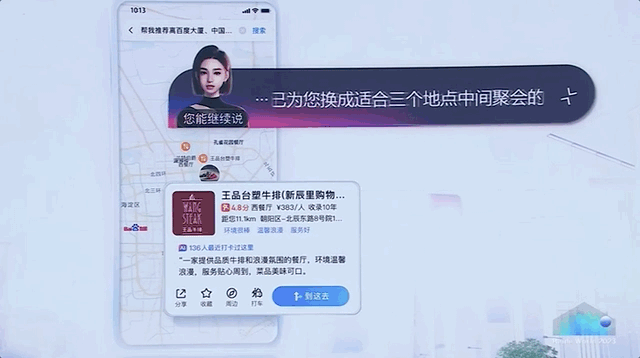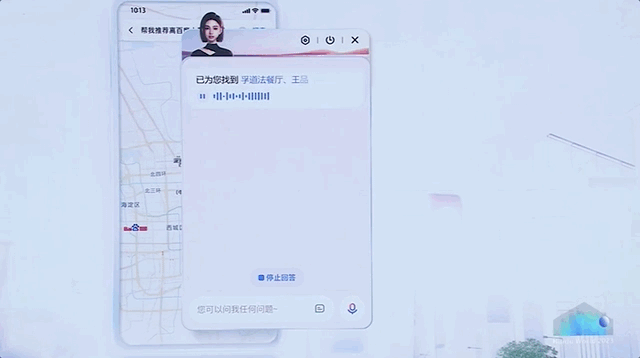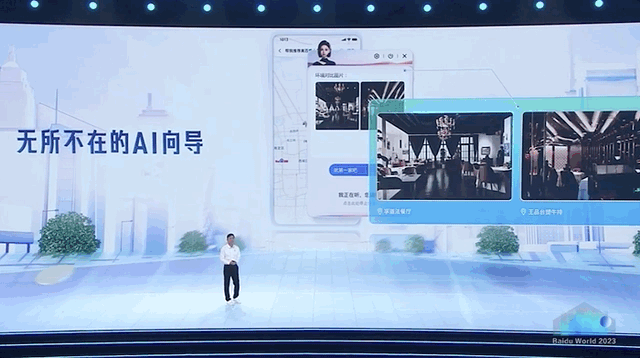
百度此番出手,可以說是直接展示了一把大模型全方位的應用滲透,揭開了 AI 原生時代大幕的一角。
而百度“第一個把全部產品用大模型重做一遍”的先手優勢,也已經在更大範圍內開始顯現。
李彥宏透露,百度的大模型技術已經應用在製造、能源、電力、化工、交通等實體產業中,17000 家企業已參與其中,大模型正在成爲新型工業化的重要推動力。

從 3 月份文心一言發佈,到年中文心大模型 3.5 版本更新,再到現在 4.0 驚豔亮相,百度文心大模型的迭代速度不可謂不迅速。
這背後既是國產大模型從技術 demo 到落地應用的激烈競爭,也再一次體現了百度在大模型領域深厚的技術積累。
並且隨着文心大模型 4.0 和百度一衆 AI 原生應用的亮相,大模型賽場上新一階段的競爭方向愈發明顯。
正如李彥宏所說:
在此過程之中,無論是國產大模型基礎能力的快速追趕,還是 AI 原生應用開發的主動進擊,都令人心潮澎湃。
AI 原生時代,在各種層面上,都越來越值得期待了。
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。