谷歌:堪比飛機首次上天里程碑 IBM科學家:結論有bug
摘要:最新一期《自然》期刊的封面文章,證實了谷歌在量子計算領域的重要進展:谷歌研製的量子計算機首次實現“量子霸權”,其用200秒就能解決的問題,當今最強的超級計算機需要花費1萬年。就在本週一,谷歌在量子計算領域的直接競爭對手IBM也發表了一篇未經同行評議的預印本論文,而這篇文章的矛頭直指谷歌宣稱的“量子霸權”。

圖片來源:Google
最新一期《自然》期刊的封面文章,證實了谷歌在量子計算領域的重要進展:谷歌研製的量子計算機首次實現“量子霸權”,其用200秒就能解決的問題,當今最強的超級計算機需要花費1萬年。但是,IBM卻指出,這項研究存在明顯的漏洞。這場爭議因何而起,量子計算究竟發展到了什麼階段?
一度撤下的重大突破
9月22日,NASA官網上出現了一篇關於谷歌量子計算的論文。儘管當時只是發表在預印本網站,但論文一經公佈,便引起轟動。因爲谷歌在論文中宣佈,他們取得了量子計算領域的里程碑式突破:一個包含53量子比特的處理器,首次實現了量子霸權。
量子計算機有着遠超傳統計算機的潛力,這已經是相關科學家的共識。一個直觀的理由是,傳統計算機的比特,也就是基本信息單位,只能是0、1這兩種狀態中的一個;而量子比特可以是0和1的疊加態,即同時處於這兩種狀態。因此,量子比特存儲信息的潛能比傳統的比特更強。
不過,雖然理論很誘人,但量子計算機的實踐卻並不順利。一個限制因素是時間:量子相干的時間是有限的,如果量子退相干之前,量子計算還沒有完成,那麼最終的運算結果自然沒有意義。此外,量子計算需要在接近絕對零度的低溫下進行,因爲熱量可能會干擾、破壞量子態。
因此,量子計算面臨着巨大的挑戰:參與耦合的量子比特越多,其運算能力將以驚人的雙指數增長;但與此同時,機器保持量子態的難度也越大。
2012年,加州理工學院的量子物理學教授約翰·普雷斯基爾(John Preskill)在一篇文章中提出了“量子霸權”(quantum supremacy;也有譯作“量子優越性”,但supremacy原有霸權、至上的涵義)的概念。簡單地說,量子霸權要求量子計算機能夠完成經典計算機幾乎不可能完成的任務。通常人們認爲,需要大約50個量子比特,能達到量子霸權。但很長一段時間內,這都是研究團隊難以企及的目標。
因此,當谷歌的論文在一個月前突然上線,很多人的第一反應是不可思議。而且,NASA網站上的論文很快又被刪除,這使得谷歌的量子計算研究又增添了一絲神祕色彩。如今,隨着這篇論文以封面論文的形式出現在最新一期的《自然》期刊,谷歌的工作最終得到了證實。在這項研究中,谷歌團隊是怎樣實現量子霸權的?
隨機數採樣實驗
在這篇論文中,約翰·馬丁尼斯(John Martinis)帶領的團隊構建了一個名爲Sycamore的量子芯片。這個芯片由140個量子比特構成。其中54個是Transmon量子比特,用於儲存信息;另外86個量子比特則用作耦合器,連接上述量子比特。最終,每個Transmon和4個耦合器相連,組成如下圖所示的量子電路。不過,由於其中一個Transmon出現了故障,最終用於演示量子霸權的量子比特是53個。
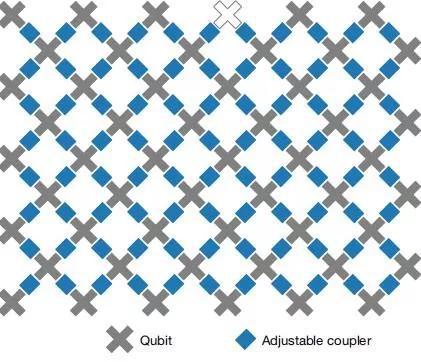
研究團隊首先利用這個系統進行了單量子比特和雙量子比特計算,其保真度在99%~99.9%之間——這是令研究者滿意的數據。隨後,他們設計了一項對傳統計算機而言非常困難的任務:對電路產生的隨機數進行採樣。正是在這項任務中,出現了報道中最震撼的數據:Sycamore在200秒內完成的任務,傳統計算機需要花費1萬年之久。
我們知道,每個量子比特可以生成0和1兩個數字中的一個,那麼這53個量子比特共同組成的數字串有253種可能性。如果是傳統的電路,每種結果出現的可能性是完全一致的,但量子電路卻並非如此:由於量子比特之間存在相干性,就像是干涉實驗中粒子集中在某些條紋,這項實驗中一些數字串出現的可能性也更高。研究者令Sycamore對量子電路進行採樣,運行100萬次後,計算字符串的概率分佈。採樣數量越多、每次採樣的深度越深,任務的難度也就越大。研究團隊還與目前最強的傳統計算機——美國橡樹嶺國家實驗室的Summit進行了對比。

Sycamore量子芯片
進行100萬次採樣、每次採樣的深度爲20層時,Sycamore用時200秒,保真度爲0.2%。而Summit超級計算機儘管包含了超過9000個強大的中央處理器,以及近2.8萬個圖像處理器,卻需要1萬年才能完成這一任務。如此大的差距,足以讓谷歌宣稱量子霸權的到來。
當然,需要說明的是,這項研究的目的不在於證明量子計算機的實際用途,他們挑選的任務也不具備真正的應用價值,而僅僅是展示量子計算機的能力。因此,距離量子計算的下一個重要里程碑——真正通用的量子計算機,依然遙遠。
又一個“Hello world”
但無論如何,這項成果仍舊令人振奮——至少谷歌CEO桑達爾·皮查伊(Sundar Pichai)是這樣認爲的。就在論文發表的當天,皮查伊在官網上發佈了一篇題爲《量子計算里程碑的意義》的博文。皮查伊在博文回顧了谷歌在量子計算領域的漫長研究歷程:
2006年,谷歌科學家、現爲谷歌AI量子實驗室主任的哈特穆特·內文(Hartmut Neven)開始探索,量子計算能否加速機器學習。在此基礎上,谷歌的AI量子團隊誕生。2014年,團隊迎來了重要人物:馬丁尼斯帶領他在加州大學聖塔芭芭拉分校的團隊加入谷歌。兩年後,塞爾吉奧·博伊克索(Sergio Boixo)發表了一篇文章後,團隊開始聚焦量子霸權的計算任務。不過,團隊此後的研究道路其實並不順利。轉折點出現在去年10月。當谷歌在聖塔芭芭拉的實驗室因南加州大火關閉時,研究團隊在被迫休假期間突然有了靈感,最終全新的思路轉化成今天的成果。
皮查伊寫道,這是一個期待已久的“Hello world”時刻:“今天的新聞,就像火箭第一次脫離地球引力、飛向太空時,人們會說,‘到了太空卻什麼都不做,這有什麼意義?’但在科學層面,這卻是重要的第一步,從此人們可以想象前往月球、火星,甚至是星際旅行。它向我們展示了什麼是可能發生的。無論如何,這是全球量子計算領域的里程碑:一個充滿可能性的時刻。”
在接受媒體採訪時,皮查伊還舉了另一個例子來說明成果的開創性意義:就像萊特兄弟發明飛機時的第一次試飛,儘管只有12秒,但它證明了人類飛行的可能性。
1萬年還是2.5天?
但是,也有人並不認同谷歌的說法。就在本週一,谷歌在量子計算領域的直接競爭對手IBM也發表了一篇未經同行評議的預印本論文,而這篇文章的矛頭直指谷歌宣稱的“量子霸權”。論文指出,谷歌的論文中有明顯的bug:他們低估了經典計算機的處理問題能力。IBM的科學家認爲,Summit超級計算機完成這項任務所需的時間不是1萬年,而是兩天半。如此巨大的差異,是如何出現的?
IBM的論文指出,谷歌之所以得出1萬年的結論,是因爲他們只考慮了經典計算機的內存。在谷歌的論文中,超級計算機通過薛定諤算法模擬量子態。但問題來了,一旦量子比特數超過40,超級計算機的內存就不夠用了。這時,研究者只能採用薛定諤-費曼混合算法,即將電路分爲兩部分、分別採用薛定諤算法,再通過類似於費曼路徑積分的方法連接兩個模塊。通俗地說,這種方法用時間換取了空間:內存不足的問題解決了,但也消耗了大量時間。但是,谷歌團隊忽略了計算機的硬盤。如果結合內存和硬盤的存儲能力,那麼計算機將不需要使用薛定諤-費曼混合算法。
再加上論文中超級計算機使用的算法可以進一步優化,綜合考慮這些因素,Summit執行這項任務只需要兩天半——這還只是最保守的估計。即使到了54個量子比特,Summit的用時也只不過是6天。

因此IBM認爲,儘管谷歌的量子芯片依然擁有速度優勢,但相較於谷歌提出的10億倍的差距,200秒與兩天半的差距顯然談不上“霸權”。
IBM提出質疑的另一個原因是,他們認爲“量子霸權”這個詞的使用逐漸脫離了本意,而且對公衆而言存在誤導性:量子霸權只是在特定的問題上具有優勢,而且,量子計算機並不是要真正“超越”傳統計算機。相反,未來兩者將共同協作,更加高效地解決問題。
對此,谷歌論文的通訊作者Martinis在電話發佈會上給出了回應。他歡迎其他人使用超級計算機對實驗結果進行驗證:“我們期待有人在Summit上進行運算、檢驗相關數據,因爲這是科學流程的一部分。只有經過測試,我們才能確定,IBM提出的算法能否奏效。”Martinis也堅稱,即使如IBM所言,目前的超算可以在3天內解決這個問題,但谷歌量子芯片的優勢依然可以稱得上是“量子霸權”。
IBM的論文觀點如何,還有待同行評議。但無論如何,谷歌的最新研究使得量子計算前進了一大步。正如皮查伊在採訪中說的那樣,希望人們不要過度糾結於量子霸權是否實現,而是更多地關注研究本身,以及領域的長期發展。







