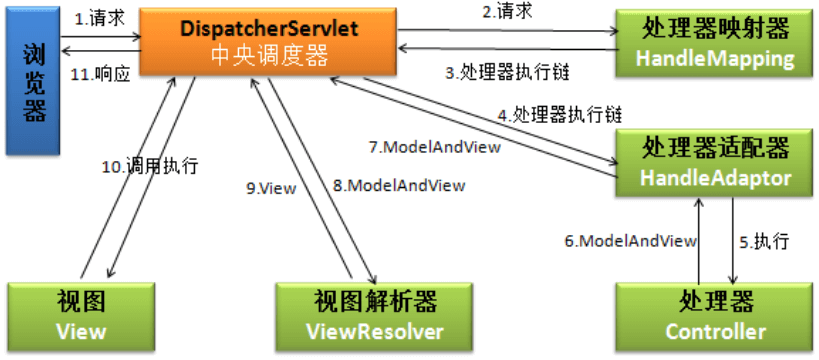
框架和項目模擬面試題目,分享給跳槽轉行的朋友
1. Struts2 框架題目
1.1. struts2 工作流程

Struts 2框架本身大致可以分爲3個部分:
核心控制器FilterDispatcher、業務控制器Action和用戶實現的企業業務邏輯組件。
核心控制器FilterDispatcher是Struts 2框架的基礎,
包含了框架內部的控制流程和處理機制。
業務控制器Action和業務邏輯組件是需要用戶來自己實現的。
用戶在開發Action和業務邏輯組件的同時,還需要編寫相關的配置文件,
供核心控制器FilterDispatcher來使用。
Struts 2的工作流程相對於Struts 1要簡單,與WebWork框架基本相同,
所以說Struts 2是WebWork的升級版本。基本簡要流程如下:
1 、客戶端初始化一個指向Servlet容器的請求;
2、 這個請求經過一系列的過濾器(Filter)
(這些過濾器中有一個叫做ActionContextCleanUp的可選過濾器,
這個過濾器對於Struts2和其他框架的集成很有幫助,例如:SiteMesh Plugin)
3 、接着FilterDispatcher被調用,
FilterDispatcher詢問ActionMapper來決定這個請是否需要調用某個Action
4、如果ActionMapper決定需要調用某個Action,
FilterDispatcher把請求的處理交給ActionProxy
5、ActionProxy通過Configuration Manager詢問框架的配置文件,
找到需要調用的Action類
6、ActionProxy創建一個ActionInvocation的實例。
7、ActionInvocation實例使用命名模式來調用,
在調用Action的過程前後,涉及到相關攔截器(Intercepter)的調用。
8、一旦Action執行完畢,ActionInvocation負責根據struts.xml中的配置找到對應的返回結果。返回結果通常是(但不總是,也可 能是另外的一個Action鏈)一個需要被表示的JSP或者FreeMarker的模版。在表示的過程中可以使用Struts2 框架中繼承的標籤。在這個過程中需要涉及到ActionMapper
9、響應的返回是通過我們在web.xml中配置的過濾器
10、如果ActionContextCleanUp是當前使用的,則FilterDispatecher將不會清理sreadlocal ActionContext;如果ActionContextCleanUp不使用,則將會去清理sreadlocals。
1.2. 過濾器Filter和struts2攔截器的區別
1、攔截器是基於java反射機制的,而過濾器是基於函數回調的。
2、過濾器依賴於servlet容器,而攔截器不依賴於servlet容器。
3、攔截器只能對Action請求起作用,而過濾器則可以對幾乎所有請求起作用。
4、攔截器可以訪問Action上下文、值棧裏的對象,而過濾器不能。
1.3. 爲什麼要使用struts2框架
Struts2 是一個相當強大的Java Web開源框架,是一個基於POJO的Action的MVC Web框架。它基於當年的Webwork和XWork框架,繼承其優點,同時做了相當的改進。
1.Struts2基於MVC架構,框架結構清晰,開發流程一目瞭然,開發人員可以很好的掌控開發的過程。
2使用OGNL進行參數傳遞。
OGNL提供了在Struts2裏訪問各種作用域中的數據的簡單方式,你可以方便的獲取Request,Attribute,Application,Session,Parameters中的數據。大大簡化了開發人員在獲取這些數據時的代碼量。
3強大的攔截器
Struts2 的攔截器是一個Action級別的AOP,Struts2中的許多特性都是通過攔截器來實現的,例如異常處理,文件上傳,驗證等。攔截器是可配置與重用的,可以將一些通用的功能如:登錄驗證,權限驗證等置於攔截器中以完成一些Java Web項目中比較通用的功能。在我實現的的一Web項目中,就是使用Struts2的攔截器來完成了系統中的權限驗證功能。
4易於測試
Struts2的Action都是簡單的POJO,這樣可以方便的對Struts2的Action編寫測試用例,大大方便了Java Web項目的測試。
易於擴展的插件機制在Struts2添加擴展是一件愉快而輕鬆的事情,只需要將所需要的Jar包放到WEB-INF/lib文件夾中,在struts.xml中作一些簡單的設置就可以實現擴展。
6模塊化管理
Struts2已經把模塊化作爲了體系架構中的基本思想,可以通過三種方法來將應用程序模塊化:將配置信息拆分成多個文件把自包含的應用模塊創建爲插件創建新的框架特性,即將與特定應用無關的新功能組織成插件,以添加到多個應用中去。
7全局結果與聲明式異常
爲應用程序添加全局的Result,和在配置文件中對異常進行處理,這樣當處理過程中出現指定異常時,可以跳轉到特定頁面。
他的如此之多的優點,是很多人比較的青睞,與spring ,Hibernate進行結合,組成了現在比較流行的ssh框架,當然每個公司都要自己的框架,也是ssh變異的產品。
1.4. struts2 有哪些優點
1)在軟件設計上Struts2的應用可以不依賴於Servlet API和struts API。 Struts2的這種設計屬於無侵入式設計;
2)攔截器,實現如參數攔截注入等功能;
3)類型轉換器,可以把特殊的請求參數轉換成需要的類型;
4)多種表現層技術,如:JSP、freeMarker、Velocity等;
5)Struts2的輸入校驗可以對指定某個方法進行校驗;
6)提供了全局範圍、包範圍和Action範圍的國際化資源文件管理實現
1.5. struts2 框架的核心控制器是什麼?它有什麼作用?
1)Struts2框架的核心控制器是StrutsPrepareAndExecuteFilter。
2)作用:
負責攔截由
不帶後綴或者後綴以.action結尾,這時請求將被轉入struts2框架處理,否則struts2框架將略過該請求的處理。
可以通過常量"struts.action.extension"修改action的後綴,如:
如果用戶需要指定多個請求後綴,則多個後綴之間以英文逗號(,)隔開。
1.6. struts2的配置文件的加載順序
struts2 core 核心包 org/apache/struts2/default.properties (定義Struts2 常量)
struts2 core 核心包 struts-default.xml (定義struts2 默認 package 、 攔截器、 結果類型)
struts2 plugin 插件包 struts-plugin.xml(定義struts2 插件的配置)
struts.xml (自定義struts2 配置文件)
struts.properties (自定義struts2 常量文件)
web.xml 中定義的struts2 常量
1.7. struts2 如何訪問HttpServletRequest、HttpSession、ServletContext 三個域對象?
方案一:
HttpServletRequest request =ServletActionContext.getRequest();
HttpServletResponse response =ServletActionContext.getResponse();
HttpSession session= request.getSession();
ServletContext servletContext=ServletActionContext.getServletContext();
方案二:
類 implements ServletRequestAware,ServletResponseAware,SessionAware,ServletContextAware
注意:框架自動傳入對應的域對象
ps:ActionContext.getContext() 可以獲得三個Map對象,間接對三個域對象中數據進行操作
1.8. struts2如何對指定的方法進行驗證?
1)validate()方法會校驗action中所有與execute方法簽名相同的方法;
2)要校驗指定的方法通過重寫validateXxx()方法實現, validateXxx()只會校驗action中方法名爲Xxx的方法。其中Xxx的第一個字母要大寫;
3)當某個數據校驗失敗時,調用addFieldError()方法往系統的fieldErrors添加校驗失敗信息(爲了使用addFieldError()方法,action可以繼承ActionSupport), 如果系統 的fieldErrors包含失敗信息,struts2會將請求轉發到名爲input的result;
4)在input視圖中可以通過
5)先執行validateXxxx()->validate()->如果出錯了,會轉發
1.9. struts2 默認能解決get和post亂碼問題嗎
不能。struts.i18n.encoding=UTF-8屬性值只能解析POST提交下的亂碼問題。
1.10. 請說出struts2中至少5個默認攔截器
fileUpload 提供文件上傳功能
i18n 記錄用戶選擇的locale
cookies 使用配置的name,value來是指cookies
checkbox 添加了checkbox自動處理代碼,將沒有選中的checkbox的內容設定爲false,而html默認情況下不提交沒有選中的checkbox。
chain 讓前一個Action的屬性可以被後一個Action訪問,現在和chain類型的result()結合使用。
params 將請求參數封裝到Struts2 Action中
validate 執行struts2 的請求參數校驗
workflow 判斷流程中是否存在FieldError ,如果存在,跳轉到input對象視圖
modelDriven 將struts2 Action 實現ModelDriven 接口提供model對象壓入root棧頂部
token 防止頁面表單重複提交
1.11. 值棧ValueStack的原理和生命週期
1)ValueStack貫穿整個 Action 的生命週期,保存在request域中,所以ValueStack和request的生命週期一樣。當Struts2接受一個請求時,會迅速創建ActionContext,
ValueStack,action。然後把action存放進ValueStack,所以action的實例變量可以被OGNL訪問。 請求來的時候,action、ValueStack的生命開始,請求結束,action、 ValueStack的生命結束;
2)action是多例的,和Servlet不一樣,Servelt是單例的;
3)每個action的都有一個對應的值棧,值棧存放的數據類型是該action的實例,以及該action中的實例變量,Action對象默認保存在棧頂;
4)ValueStack本質上就是一個ArrayList;
5)關於ContextMap,Struts 會把下面這些映射壓入 ContextMap 中:
parameters : 該 Map 中包含當前請求的請求參數
request : 該 Map 中包含當前 request 對象中的所有屬性 session :該 Map 中包含當前 session 對象中的所有屬性
application :該 Map 中包含當前 application 對象中的所有屬性
attr:該 Map 按如下順序來檢索某個屬性: request, session, application
6)使用OGNL訪問值棧的內容時,不需要#號,而訪問request、session、application、attr時,需要加#號;
7)注意: Struts2中,OGNL表達式需要配合Struts標籤纔可以使用。如:
8)在struts2配置文件中引用ognl表達式 ,引用值棧的值 ,此時使用的"$",而不是#或者%;
1.12. ActionContext、ServletContext、pageContext區別?
1)ActionContext是當前的Action的上下文環境,通過ActionContext可以獲取到request、session、ServletContext等與Action有關的對象的引用;
2)ServletContext是域對象,一個web應用中只有一個ServletContext,生命週期伴隨整個web應用;
3)pageContext是JSP中的最重要的一個內置對象,可以通過pageContext獲取其他域對象的應用,同時它是一個域對象,作用範圍只針對當前頁面,當前頁面結束時,pageContext銷燬, 生命週期是JSP四個域對象中最小的。
1.13. resul的type屬性中有哪些結果類型?
dispatcherstruts默認的結果類型,把控制權轉發給應用程序裏的某個資源不能把控制權轉發給一個外部資源,若需要把控制權重定向到一個外部資源, 應該使用
redirect 把響應重定向到另一個資源(包括一個外部資源)
redirectAction把響應重定向到另一個 Action
freemarker、velocity、chain、httpheader、xslt、plainText、stream
struts2-json-plugin 自定義 json 結果類型,用於返回json格式數據
1.14. 攔截器的生命週期與工作過程
1)每個攔截器都是實現了Interceptor接口的 Java 類;
2)init(): 該方法將在攔截器被創建後立即被調用, 它在攔截器的生命週期內只被調用一次. 可以在該方法中對相關資源進行必要的初始化;
3)intercept(ActionInvocation invocation): 每攔截一個動作請求, 該方法就會被調用一次;
4)destroy: 該方法將在攔截器被銷燬之前被調用, 它在攔截器的生命週期內也只被調用一次;
2. Hibernate3 框架題目
2.1. 爲什麼要使用Hibernate框架?它有什麼優勢?
² Hibernate對JDBC訪問數據庫的代碼做了封裝,大大簡化了數據訪問層繁瑣的重複性代碼。
² Hibernate是一個基於JDBC的主流持久化框架,是一個優秀的ORM實現,它很大程度的簡化了DAO層編碼工作。
² Hibernate使用Java的反射機制,而不是字節碼增強程序類實現透明性。
² 因爲它是一個輕量級框架。映射的靈活性很出色。它支持很多關係型數據庫,從一對一到多對多的各種複雜關係。
2.2. Hibernate工作原理(編程步驟)
1.讀取並解析Hibernate核心配置文件hibernate.cfg.xml
2.讀取並解析Hibernate映射文件,創建SessionFactory
3.打開Sesssion
4.創建事務Transation
5.持久化操作
6.提交事務
7.關閉Session
8.關閉SesstionFactory
2.3. Hibernate是如何實現延遲加載的?
延遲加載機制是爲了避免一些無謂的性能開銷而提出來的,所謂延遲加載就是當在真正需要數據的時候,才真正執行數據加載操作。在Hibernate中提供了對實體對象的延遲加載、對集合的延遲加載和對屬性的延遲加載。
當Hibernate在查詢數據的時候,數據並沒有存儲在內存中,只是使用Javassist爲目標類創建子類代理對象,當程序真正對數據的進行操作時,代理對象的handler纔去訪問數據,加載對象存在於內存中,這就實現了延遲加載,它節省了服務器的內存開銷,從而提高了服務器的性能。
2.4. Hibernate 有那幾種查詢方式
(1) 導航對象圖查詢
(2) OID查詢
(3) HQL查詢
(4) QBC查詢
(5) 本地SQL查詢
2.5. Hibernate中load方法和get方法區別
區別1:如果數據庫中沒有userId對應的記錄,通過get方法加載,則返回的是null值;如果通過load方法加載,則返回一個代理對象,當通過user對象調用某個方法(比如user.getPassword())時,會拋出異常:org.hibernate.ObjectNotFoundException;
區別2:load支持延遲加載,get不支持延遲加載。
2.6. Hibernate持久化對象有幾種狀態?
臨時狀態、遊離狀態、持久化狀態
2.7. HQL和SQL語句的區別?
HQL面向對象,而SQL操縱關係型數據庫
2.8. 說下Hibernate的緩存機制
緩存是介於應用程序和物理數據源之間,其作用是爲了降低應用程序對物理數據源訪問的頻次,從而提高了應用的運行性能。
Hibernate的緩存包括:Session的緩存(一級緩存)和SessionFactory的緩存(二級緩存)。
其中SessionFactory的緩存又可以分爲兩類:內置緩存和外置緩存。Session的緩存是內置的,不能被卸載,也被稱爲Hibernate的第一級緩存。
SessionFactory的內置緩存和Session的緩存在實現方式上比較相似,前者是SessionFactory對象的一些集合屬性包含的數據,後者是指Session的一些集合屬性包含的數據。SessionFactory的內置緩存中存放了映射元數據和預定義SQL語句,映射元數據是映射文件中數據的拷貝,而預定義SQL語句是在Hibernate初始化階段根據映射元數據推導出來,SessionFactory的內置緩存是隻讀的,應用程序不能修改緩存中的映射元數據和預定義SQL語句,因此SessionFactory不需要進行內置緩存與映射文件的同步。SessionFactory的外置緩存是一個可配置的插件。在默認情況下,SessionFactory不會啓用這個插件。外置緩存的數據是數據庫數據的拷貝,外置緩存的介質可以是內存或者硬盤。SessionFactory的外置緩存也被稱爲Hibernate的第二級緩存。
2.9. 如何優化Hibernate?
初用HIBERNATE的人也許都遇到過性能問題,實現同一功能,用HIBERNATE與用JDBC性能相差十幾倍很正常,如果不及早調整,很可能影響整個項目的進度。
大體上,對於HIBERNATE性能調優的主要考慮點如下:
Ø 數據庫設計調整
Ø HQL優化
Ø API的正確使用(如根據不同的業務類型選用不同的集合及查詢API)
Ø 主配置參數(日誌,查詢緩存,fetch_size, batch_size等)
Ø 映射文件優化(ID生成策略,二級緩存,延遲加載,關聯優化)
Ø 一級緩存的管理
Ø 針對二級緩存,還有許多特有的策略
Ø 事務控制策略。
1、 數據庫設計
a) 降低關聯的複雜性
b) 儘量不使用聯合主鍵
c) ID的生成機制,不同的數據庫所提供的機制並不完全一樣
d) 適當的冗餘數據,不過分追求高範式
2、 HQL優化
HQL如果拋開它同HIBERNATE本身一些緩存機制的關聯,HQL的優化技巧同普通的SQL優化技巧一樣,可以很容易在網上找到一些經驗之談。
在性能瓶頸的地方使用硬編碼的 JDBC。
3、 主配置
a) 查詢緩存,同下面講的緩存不太一樣,它是針對HQL語句的緩存,即完全一樣的語句再次執行時可以利用緩存數據。但是,查詢緩存在一個交易系統(數據變更頻繁,查詢條件相同的機率並不大)中可能會起反作用:它會白白耗費大量的系統資源但卻難以派上用場。
b) fetch_size,同JDBC的相關參數作用類似,參數並不是越大越好,而應根據業務特徵去設置
c) batch_size同上。
d) 生產系統中,切記要關掉SQL語句打印。
4、 緩存
a) 數據庫級緩存:這級緩存是最高效和安全的,但不同的數據庫可管理的層次並不一樣,比如,在ORACLE中,可以在建表時指定將整個表置於緩存當中。
b) SESSION緩存:在一個HIBERNATE SESSION有效,這級緩存的可干預性不強,大多於HIBERNATE自動管理,但它提供清除緩存的方法,這在大批量增加/更新操作是有效的。比如,同時增加十萬條記錄,按常規方式進行,很可能會發現OutofMemeroy的異常,這時可能需要手動清除這一級緩存:Session.evict以及Session.clear
c) 應用緩存:在一個SESSIONFACTORY中有效,因此也是優化的重中之重,因此,各類策略也考慮的較多,在將數據放入這一級緩存之前,需要考慮一些前提條件:
i. 數據不會被第三方修改(比如,是否有另一個應用也在修改這些數據?)
ii. 數據不會太大
iii. 數據不會頻繁更新(否則使用CACHE可能適得其反)
iv. 數據會被頻繁查詢
v. 數據不是關鍵數據(如涉及錢,安全等方面的問題)。
緩存有幾種形式,可以在映射文件中配置:read-only(只讀,適用於很少變更的靜態數據/歷史數據),nonstrict-read-write,read-write(比較普遍的形式,效率一般),transactional(JTA中,且支持的緩存產品較少)
d) 分佈式緩存:同c)的配置一樣,只是緩存產品的選用不同,在目前的HIBERNATE中可供選擇的不多,oscache, jboss cache,目前的大多數項目,對它們的用於集羣的使用(特別是關鍵交易系統)都持保守態度。在集羣環境中,只利用數據庫級的緩存是最安全的。
5、 延遲加載
a) 實體延遲加載:通過使用動態代理實現
b) 集合延遲加載:通過實現自有的SET/LIST,HIBERNATE提供了這方面的支持
c) 屬性延遲加載:
6、 方法選用
a) 完成同樣一件事,HIBERNATE提供了可供選擇的一些方式,但具體使用什麼方式,可能用性能/代碼都會有影響。顯示,一次返回十萬條記錄(List/Set/Bag/Map等)進行處理,很可能導致內存不夠的問題,而如果用基於遊標(ScrollableResults)或Iterator的結果集,則不存在這樣的問題。
b) Session的load/get方法,前者會使用二級緩存,而後者則不使用。
c) Query和list/iterator,如果去仔細研究一下它們,你可能會發現很多有意思的情況,二者主要區別(如果使用了Spring,在HibernateTemplate中對應find,iterator方法):
i. list只能利用查詢緩存(但在交易系統中查詢緩存作用不大),無法利用二級緩存中的單個實體,但list查出的對象會寫入二級緩存,但它一般只生成較少的執行SQL語句,很多情況就是一條(無關聯)。
ii. iterator則可以利用二級緩存,對於一條查詢語句,它會先從數據庫中找出所有符合條件的記錄的ID,再通過ID去緩存找,對於緩存中沒有的記錄,再構造語句從數據庫中查出,因此很容易知道,如果緩存中沒有任何符合條件的記錄,使用iterator會產生N+1條SQL語句(N爲符合條件的記錄數)
iii. 通過iterator,配合緩存管理API,在海量數據查詢中可以很好的解決內存問題,如:
while(it.hasNext()){
YouObject object = (YouObject)it.next();
session.evict(youObject);
sessionFactory.evice(YouObject.class, youObject.getId());
}
如果用list方法,很可能就出OutofMemory錯誤了。
iv. 通過上面的說明,我想你應該知道如何去使用這兩個方法了。
7、 集合的選用
在HIBERNATE 3.6文檔的“21.5理解集合性能”中有詳細的說明。
² ists,maps 和 sets 用於更新效率最高
² Bag 和 list 是反向集合類中效率最高的
² 一次性刪除(One shot delete)
8、 事務控制
事務方面對性能有影響的主要包括:事務方式的選用,事務隔離級別以及鎖的選用
a) 事務方式選用:如果不涉及多個事務管理器事務的話,不需要使用JTA,只有JDBC的事務控制就可以。
b) 事務隔離級別:參見標準的SQL事務隔離級別
c) 鎖的選用:悲觀鎖(一般由具體的事務管理器實現),對於長事務效率低,但安全。樂觀鎖(一般在應用級別實現),如在HIBERNATE中可以定義VERSION字段,顯然,如果有多個應用操作數據,且這些應用不是用同一種樂觀鎖機制,則樂觀鎖會失效。因此,針對不同的數據應有不同的策略,同前面許多情況一樣,很多時候我們是在效率與安全/準確性上找一個平衡點,無論如何,優化都不是一個純技術的問題,你應該對你的應用和業務特徵有足夠的瞭解。
9、 批量操作
即使是使用JDBC,在進行大批數據更新時,BATCH與不使用BATCH有效率上也有很大的差別。我們可以通過設置batch_size來讓其支持批量操作。
舉個例子,要批量刪除某表中的對象,如“delete Account”,打出來的語句,會發現HIBERNATE找出了所有ACCOUNT的ID,再進行刪除,這主要是爲了維護二級緩存,這樣效率肯定高不了,在後續的版本中增加了bulk delete/update,但這也無法解決緩存的維護問題。也就是說,由於有了二級緩存的維護問題,HIBERNATE的批量操作效率並不盡如人意!
從前面許多要點可以看出,很多時候我們是在效率與安全/準 確性上找一個平衡點,無論如何,優化都不是一個純技術的問題,你應該對你的應用和業務特徵有足夠的瞭解,一般的,優化方案應在架構設計期就基本確定,否則 可能導致沒必要的返工,致使項目延期,而作爲架構師和項目經理,還要面對開發人員可能的抱怨,必竟,我們對用戶需求更改的控制力不大,但技術/架構風險是應該在初期意識到並制定好相關的對策。
還有一點要注意,應用層的緩存只是錦上添花,永遠不要把它當救命稻草,應用的根基(數據庫設計,算法,高效的操作語句,恰當API的選擇等)纔是最重要的。
2.10. 如何解決關聯數據延遲加載NoSession問題
² 在確定關聯數據是必須時,可以配置 lazy=false 使用立即加載策略
² 使用OpenSessionInView 模式,在需要數據時,纔去加載
² 在程序中,根據業務需要,手動Hibernate.initialize() 手動初始化延遲加載數據
2.11. Hibernate 的 sessionfactory 和 session 的區別是什麼?如何處理 session 線程不安全問題?
sessionfactory 是一個數據源對應着一個 sessionfactory,也就說他是屬於二級緩存,如果是
集羣環境,他可以動態的配置使用這個數據源或者不使用這個數據源。
session 是等於一次回話,也就是說是一級緩存,並且是由 sessionfactory
創建的,再有 sessionfactory 是線程安全的,相反的session 不安全的;
解決 session 不安全的問題,就是大家通常用的常規寫法,一次會話後關閉 session,避免
session 重用;
2.12. Hibernate 如何實現動態查詢?DetachedCriteria 與 Criteria 的區別是什麼?
條件查詢。,編程的方式代替 HQL 語句,DetachedCriteria 單詞很簡明瞭,Detached 是分離,
分離什麼,當然是業務層的應用,原本的Criteria 是與 session 綁定的,現在用DetachedCriteria這個來分離。(沒解釋清楚)
3. Spring3 框架題目
3.1. Spring框架的優點
² 方便解耦,簡化開發
n Spring就是一個大工廠,可以將所有對象創建和依賴關係維護,交給Spring管理
² AOP編程的支持
n Spring提供面向切面編程,可以方便的實現對程序進行權限攔截、運行監控等功能
² 聲明式事務的支持
n 只需要通過配置就可以完成對事務的管理,而無需手動編程
² 方便程序的測試
n Spring對Junit4支持,可以通過註解方便的測試Spring程序。
² 方便集成各種優秀框架
n Spring不排斥各種優秀的開源框架,其內部提供了對各種優秀框架(如:Struts、Hibernate、MyBatis、Quartz等)的直接支持
² 降低JavaEE API的使用難度
n Spring 對JavaEE開發中非常難用的一些API(JDBC、JavaMail、遠程調用等),都提供了封裝,使這些API應用難度大大降低
3.2. 談談你理解的IoC和DI
IOC是Inversion of Control的縮寫,控制反轉,簡單來說就是把複雜系統分解成相互合作的對象,藉助於“第三方”實現具有依賴關係的對象之間的解耦。 這裏的第三方 就是指Ioc容器(Spring 框架),所有對象的創建權,都交由Spring管理。
DI的出現,是對IoC的更近一步分析,既然IOC是控制反轉,那麼到底是“哪些方面的控制被反轉了呢?經過詳細地分析和論證後,他得出了答案:“獲得依賴對象的過程被反轉了”。控制被反轉之後,獲得依賴對象的過程由自身管理變爲了由IOC容器主動注入。
依賴注入(DI)和控制反轉(IOC)是從不同的角度描述的同一件事情,就是指通過引入IOC容器,利用依賴關係注入的方式,實現對象之間的解耦。
3.3. Spring中BeanFactory和ApplicationContext 的作用和區別?
作用:
1. BeanFactory負責讀取bean配置文檔,管理bean的加載,實例化,維護bean之間的依賴關係,負責bean的聲明週期。
2. ApplicationContext除了提供上述BeanFactory所能提供的功能之外,還提供了更完整的框架功能:
a. 國際化支持
b. 資源訪問:Resource rs = ctx. getResource(”classpath:config.properties”), “file:c:/config.properties”
c. 事件傳遞:通過實現ApplicationContextAware接口
3.4. Spring 中有幾種事務管理?
編程式事務管理,通過TransactionTemplate 實現
聲明式事務管理,基於AOP 切面編程實現 ,無需編碼,靈活性更高
3.5. Spring 的 Bean作用域
在spring2.0之前bean只有2種作用域即:singleton(單例)、non-singleton(也稱 prototype),Spring2.0以後,增加了session、request、global session三種專用於Web應用程序上下文的Bean。因此,默認情況下Spring2.0現在有五種類型的Bean。
1、singleton作用域
當一個bean的作用域設置爲singleton,那麼Spring IOC容器中只會存在一個共享的bean實例,並且所有對bean的請求,只要id與該bean定義相匹配,則只會返回bean的同一實例。換言之,當把一個bean定義設置爲singleton作用域時,Spring IOC容器只會創建該bean定義的唯一實例。這個單一實例會被存儲到單例緩存(singleton cache)中,並且所有針對該bean的後續請求和引用都將返回被緩存的對象實例,這裏要注意的是singleton作用域和GOF設計模式中的單例是完全不同的,單例設計模式表示一個ClassLoader中只有一個class存在,而這裏的singleton則表示一個容器對應一個bean,也就是說當一個bean被標識爲singleton時候,spring的IOC容器中只會存在一個該bean。
2、prototype
prototype作用域部署的bean,每一次請求(將其注入到另一個bean中,或者以程序的方式調用容器的getBean()方法)都會產生一個新的bean實例,相當於一個new的操作,對於prototype作用域的bean,有一點非常重要,那就是Spring不能對一個 prototype bean的整個生命週期負責,容器在初始化、配置、裝飾或者是裝配完一個prototype實例後,將它交給客戶端,隨後就對該prototype實例不聞不問了。不管何種作用域,容器都會調用所有對象的初始化生命週期回調方法,而對prototype而言,任何配置好的析構生命週期回調方法都將不會被調用。
3.6. Spring使用屬性注入方式
兩種依賴注入的類型分別是setter注入和構造方法注入。
setter注入: 一般情況下所有的java bean, 我們都會使用setter方法和getter方法去設置和獲取屬性的值。
構造方法注入:使用帶參數的構造方法
3.7. Spring配置文件applicationContext.xml 能不能改名
ContextLoaderListener是一個ServletContextListener, 它在你的web應用啓動的時候初始化。缺省情況下, 它會在WEB-INF/applicationContext.xml文件找Spring的配置。 你可以通過定義一個
3.8. Spring的聲明式事務的如何實現的?
使用內置 TransactionProxyFactoryBean 爲目標對象創建AOP代理對象,通過指定TransactionManager 對目標對象的方法添加事務管理操作 。
3.9. Spring AOP編程原理?項目中如何使用的?
將傳統繼承的代碼複用,變爲代碼的橫向抽取機制,通過 代理機制,向目標對象織入增強代碼。
Spring AOP底層基於 Jdk動態代理和Cglib 動態代理 實現
項目中用到的Spring中的切面編程最多的地方:聲明式事務管理。
a、定義一個事務管理器
b、配置事務特性(相當於聲明通知。一般在業務層的類的一些方法上定義事務)
c、配置哪些類的哪些方法需要配置事務(相當於切入點。一般是業務類的方法上)
3.10. Spring提供哪些事務傳播行爲 ?
PROPAGATION_REQUIRED–支持當前事務,如果當前沒有事務,就新建一個事務。這是最常見的選擇。
PROPAGATION_SUPPORTS–支持當前事務,如果當前沒有事務,就以非事務方式執行。
PROPAGATION_MANDATORY–支持當前事務,如果當前沒有事務,就拋出異常。
PROPAGATION_REQUIRES_NEW–新建事務,如果當前存在事務,把當前事務掛起。
PROPAGATION_NOT_SUPPORTED–以非事務方式執行操作,如果當前存在事務,就把當前事務掛起。
PROPAGATION_NEVER–以非事務方式執行,如果當前存在事務,則拋出異常。
PROPAGATION_NESTED–如果當前存在事務,則在嵌套事務內執行。如果當前沒有事務,則進行與PROPAGATION_REQUIRED類似的操作。
事務傳播行爲,主要用於解決,兩個事務方法互相調用的問題,例如A方法開啓事務,調用B方法,B方法也進行事務管理,A方法和B方法的事務是怎樣的關係問題。
4. 項目題目
4.1. 你先介紹下你開發的這個項目?
從項目的背景、項目業務進行介紹
4.2. 你負責項目中哪個部分?
4.3. 你負責的這個模塊,都實現了哪些功能?
4.4. Xxx功能模塊是如何實現的 ?
通常問到這個問題後,就會進入一些技術細節的問題
4.5. 你在項目開發中有沒有遇到什麼難解決的問題?最終是如何解決的?
4.6. Xxx技術在項目中是如何應用的?
4.7. JBPM的開發流程
流程設計 ---- 流程定義發佈 ---- 流程實例啓動 ---- 組任務查詢 --- 任務拾取 ---- 個人任務查詢 ---- 根據form屬性跳轉到辦理頁面 --- 任務辦理 --- 流程流轉
4.8. 數據庫是如何優化的?
4.9. Lucene的存儲結構,如何和數據庫關聯的?
4.10. Hibernate二級緩存在項目中是如何應用的?
PS: 項目這部分,還是有項目的模擬面試老師自己去把控吧,很難寫清楚!