你的文字,看不懂!是機器翻譯出來的嗎?
來源:果殼
這是我非常困惑的事情,本不願意在大家面前多說,但是事已至此被坑了一遍又一遍,想了很久,本不想佔用果殼頭條的我不得不說——爲什麼用機器翻譯出來的內容,總是讓人看不懂啊!

網友試圖將鄭爽的微博翻譯成英文,竟莫名通順了起來。喫瓜羣衆不免猜測, 鄭爽的微博之所以看不懂,或許是機器翻譯的結果 | 截圖自豆瓣@chemistry
機器翻譯已經很努力了!
古早的機器翻譯,通常是直接把句子拆成幾塊,然後一塊一塊去翻譯。
但人類翻譯並不是這樣。我們通常會通讀整個句子,來理解其中的含義,再用另外一種語言來表達相近的意思。傳統機翻與人類的閱讀方式不同,是翻譯不順滑的一個主要原因。
後來,科學家們找到了一種名叫“神經機器翻譯”(Neural Machine Translation,NMT)的新方法,儘量貼近人類的翻譯方式。

“我是學生”的英文翻譯爲法文 | TensorFlow
這類算法在看到一個句子之後,會用編碼器把整句話轉換成一個向量,也就是用一串數代表這句話的含義。然後,再用一個解碼器,把這串數字轉換成目標語言。
這樣的 AI,能夠更好地捕捉字與字之間的相互依賴關係,哪怕兩個字之間的距離比較遠,中間隔了一些字,也可能考慮到句子結構等等因素。
那麼,編碼器與解碼器這個組合的能力如何修煉?當人類源源不斷地給算法投餵文本數據(大多是雙語對照數據),它們便能從中歸納更多的規律,讓翻譯技能變得越來越強。
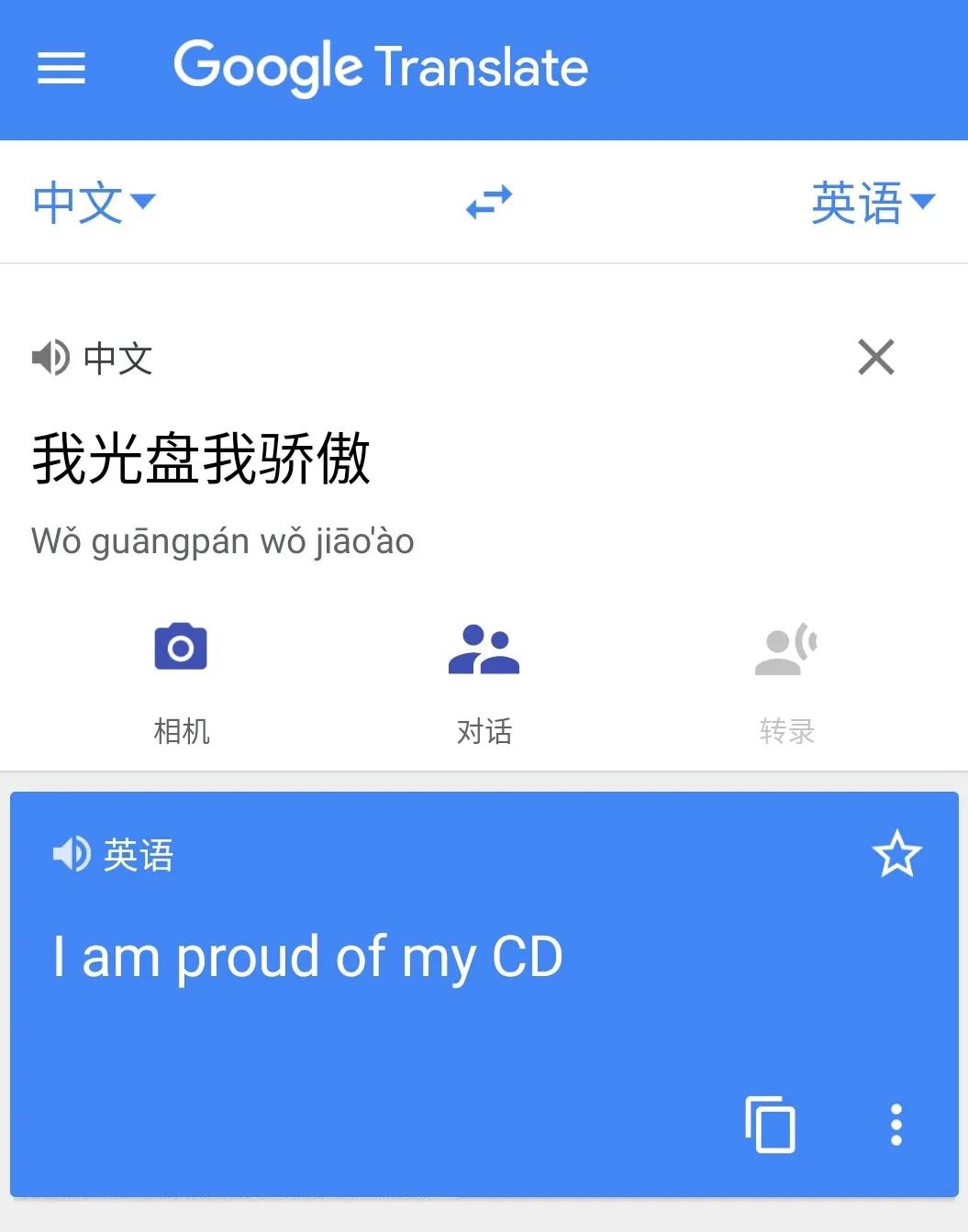
即使不斷學習,機器翻譯還是會有許多看不懂的結果 | 谷歌翻譯
但還是有各種 bug
不過,一隻 AI 就算學得再多,也只是給出統計學意義上的答案,並不能真正理解語言當中的邏輯關係。比如,谷歌翻譯曾經有過一個經典錯誤。輸入“北大不如清華”,得到“Beijing University is better than Qinghua”。而人類翻譯不太可能出現這樣的錯誤。

北大不如清華 | 谷歌翻譯
除此之外,AI 要把中文翻譯成另外一種語言,還會遇到另外一個難點——如何分詞。
漢語裏的詞彙常常由兩個字或者更多個字組成,但詞與詞之間卻沒有間隔。熟悉這種語言的人類不易出錯,AI 卻要先了解哪些字會組成詞語或固定搭配,才能實現更準確的翻譯。
近年有不少出色的分詞工具陸續誕生,比如百度工程師 Sun Junyi 開發的結巴分詞、清華出品的 THULAC、北大出品的 pkuseg 等等。它們不負責翻譯,但也是用大量文本訓練而成的 AI。
當然,再機智的分詞AI也未必能拯救“帝國主義把我們的地瓜分掉”“我們中出了叛徒”這些刁鑽句子的機翻。

另外,機器翻譯還逃不開一個熟悉的問題:每個詞都認識,整個句子也知道什麼意思,但總覺得不像人話。
嘿,我的老夥計,這不是翻譯腔嗎?
帶有翻譯腔的文字往往是在形式上過於忠於原文,忽視了翻譯出來的語言本身的表達習慣。在不合適的情境下,翻譯腔會讓人覺得不自然、費解甚至可笑。這種現象在人工翻譯中已經越來越少見,但機器翻譯往往對長句子、上下文語境難以判斷,容易出現“翻譯腔”的結果,有時候還不如直接讀原文理解得更好。

忽視中文表達習慣的一個典型 | 編輯供圖
看不懂?譯後編輯很重要!
機器翻譯大大提高了信息傳遞的效率,如果只需要提供大概的意思,直接使用機器翻譯的輸出譯文,通常不會有什麼大問題。但在正式的文本,甚至文學著作裏,如果有人敢直接使用機翻結果,那真可謂勇士了。
對翻譯效率要求較高的文字內容,“機器翻譯+人工編輯”是翻譯得又快又準確的方法之一。這一需求催生了一個新的職業——譯後編輯(Postediting)。
譯後編輯的工作看起來就像是讓機器翻譯“說人話”,不過這個過程並不容易:一方面要快速識別機翻譯文中的特徵錯誤,另一方面要根據譯文的用途,確定和修飾翻譯的結果。

有提供譯後編輯服務的公司 | eliteasia.co
你可能會問:這和翻譯審校的工作不是差不多嗎?實際上,差別挺大的。除了對翻譯前後的語言有基礎的理解,譯後編輯還需要掌握機翻的原理知識和基本的編程技能,從而爲機器翻譯編制相關的詞典。
作爲信息交流的工具,機器翻譯會越來越聰明,輸出的句子也會越來越清晰。不過,語言本身不只是工具,譯後編輯的工作正是將機器翻譯的高效與人工翻譯的準確結合在一起,讓人能夠快速獲得看得懂,甚至是有風格、有情緒的信息。
畢竟,如果有了譯後編輯,應該就不會這種翻譯了吧👇













