少數派投資:不能盡知數據之害者 不能得數據之利
原標題:不能盡知數據之害者,不能得數據之利(少數派投資)
來源:少數派投資

語言描述是很主觀的,只有數據才客觀,這是多數人的共識。
該層思維批判瞭如下情景:無視數據,只憑主觀感覺下判斷。此類問題,只要查一下數據就能明辨是非。
上述共識適用於對最淺層快思維直覺的否定,但還存在更慢的思維:
現實中,數據往往披着婆娑的外衣,有着更多的迂迴和扭曲,並不是有了“數據支撐”就可以妄下結論,也不是有了數據就可以迷之自信、一路坦途。
本文借用《孫子兵法》的表述:不能盡知數據之害者,不能得數據之利。
注:原文爲“不能盡知用兵之害者,不能得用兵之利”
我們先看一組案例:
例1:一則新聞:1924級耶魯畢業生平均年收入爲25111美元。(1949年統計)
例2:某感冒藥廣告:實驗室數據顯示,僅半盎司該藥劑量在11秒鐘內就殺死了試管中31108個細菌。
例3:2018年,某知名財經媒體發文《在自己先祖的土地上流浪》,其中引用規模以上民企數據,將調出規模以上口徑的民企視爲已死掉。
例4:某牙膏廣告:“用戶反映使用Doakes牌牙膏將使蛀牙減少23%”,該結論出自一家信譽良好的“獨立實驗室”,且通過了註冊會計師的證實。
例5:智力測試中,小明101分,小亮99分,小明是否比小亮更聰明?
例6:某香菸品牌宣傳:一家國家級雜誌主持的實驗證明該香菸在尼古丁含量方面“排名最後”,因此對人體傷害最小。
例7:觀察數據:公雞打鳴時間在天亮之前,得出結論:雞叫是天亮的原因。
例8:亞里士多德統計了羽毛和石頭的落地時間,前者用時更長,由此得出結論:重的物體比輕的物體落地更快。
例9:觀察某股票價格變化,發現其一旦上漲會持續一段時間、下跌也有持續性,體現出某種股市中存在的可重複模式。

例10:一個50年的回測,無論是1968-1998年的樣本內測試,還是1989-2015年的樣本外測試收益都非常出色,且與其他主流因子,如市值、估值、動量等相關係數很低,年換手率僅10%。
本文圍繞上述10個案例展開,我們不去探討如何改進統計方法、多數情況下並不具備條件可以再統計一遍,而是從數據接受者的視角出發,思考如何減少有偏數據的誤導,避免掉入“似是而非”的陷阱,從而看到數據背後更多的可能:
例1:耶魯畢業生收入(數據的隱含假設)
1924級(此時已畢業25年)25111美元的人均收入,即便是真實的,也只是代表了“能夠聯繫上的,並願意站出來說出收入的一個特殊羣體”,還要保證聯繫人能說真話。
通過還原隱含假設,我們看到了數據本身的“代表性”:這樣的假設下的統計對象顯然與我們內心默認的不是一回事。
想一想這些數據會是怎麼統計的?有哪些隱含的假設?所反映的對象真的是我們普遍共識的樣本嗎?由此你會避免接受很多似是而非的數據。
《統計數字會撒謊》進一步提醒我們:
“即使你找不到任何破壞性的誤差來源,但只要有產生誤差的可能性,你就有必要對結果保留一定的懷疑。”
例2、3:感冒藥廣告與規模以上民企(偷換概念)
消費者心中的有效藥物是能治好感冒,而藥商宣傳的卻是能殺死試管中的細菌。
問題在於,到底是什麼引起了感冒?試管中的細菌和感冒有沒有關係?是不是同一種細菌?還是病毒?另外,試管中有效的、稀釋後在人體內是否還有作用?對此,正在流鼻涕的患者們不會深究。
例3中,規模以上企業的定義是年主營業務收入爲2000萬及以上企業,當年不再滿足的企業很可能是收入下降到了2000萬以下,而不是倒閉死掉了。
正如《統計數字會撒謊》所言:
“如果你想證明某事,卻發現沒有能力辦到,那麼就試着解釋其他相關事情,並假裝它們是一回事。”
反觀股票市場研究,目前主流的“反應不足”、“反應過度”的代理變量設置類似於此,從事前來看,原本就沒有“反映適中”的合理定義,何來“不足”與“過度”?混淆事前與事後,強行用市值、換手率等指標來代理,打着旗號卻根本沒有解決問題本身。
例4:牙膏廣告(選擇性小樣本數據拷問)
蛀牙減少23%的數據,即便有權威機構背書,也不可信。
關鍵在於數據的獲取過程:多克斯公司讓規模不大的一組人連續記錄6個月的蛀牙數,接着使用多克斯牙膏。此後必然會出現如下三種結果中的一種:
①蛀牙增多;②蛀牙減少;③蛀牙不變
如果結果是①或③,多克斯公司會將之藏起、重新實驗,由於機遇的作用,遲早有一組測試者將證明有很好的效果,“足以好到作爲標題直至引發一場廣告戰”。
這是一個典型的故意拷問不充分小樣本以誤導消費者的案例。
現實中,別人展示給我們的數據,背後都有各種利益訴求,或多或少存在類似的問題,要關注常識、不應簡單相信。
例5、6:智力測試與香菸廣告(過分關注不必要誤差)
智力測試只是一種測量工具,測量人們處理事先準備好的抽象問題的能力,但對這些能力我們甚至無法給出確切定義。
同時,該測試只是智力水平的一個抽樣,具有統計誤差,正常的智商並不是一個數值而是一個範圍,處於這個範圍、相差不大的比較則毫無意義。
至於香菸公司所引用的雜誌數據,則是《讀者文摘》某編輯發起的一項實驗,其結論是“所有品牌的香菸是一樣的,無論你吸的是什麼牌子的香菸,不會有任何差異。”
但問題在於,在一長串具有相同有害物質的品牌名單上,總會有一個排在最後,就是這家香菸品牌,但它在宣傳時對於危害差異並不大的關鍵信息卻省略掉了。
股票市場上,對歷史數據的回測統計更應該警惕該問題。歷史的股價中可能有必然的東西,但也有更大程度的偶然成分,正如《機器學習發展》一書所言“已有的演繹路徑只是隨機過程的可能結果之一,且未必是最有可能的未來”。
在此基礎上,反覆拷問出的回測更優很可能只是誤差而已,不能簡單作爲評判標準,更不足以“恃”,由此帶來的自以爲的可把握感與迷之自信反而會導致預留的安全墊不足。
相比之下,各維度統計所反映的共性成分反而更有價值,適度抽象地理解數據結論會有更好的適用性。
例7:日出與公雞打鳴(因先後發生而因果倒置)
日出與雞叫有明顯的相關性,該案有意思的一點在於,雞叫一般發生在日出前,先發生的一定就是原因嗎?中國古人就有“雄雞一唱天下白”的詩句。
現代人瞭解更多的科學知識,從更高的框架下俯視,自然容易明辨是非。
但是,諸如此類有明確先後的相關現象,背後的因果解釋真的就那麼篤定嗎?有沒有其他的可能?該案至少是一個警示。
例8:亞里士多德(數據的真正用途是驗證)
亞里士多德基於石頭比羽毛更快落地的數據,得出了重的物體更快落地的結論,是一個典型的“有數據支撐”的誤判。
並不是基於數據能夠歸納出的規律就是對的,數據的真正用途是:驗證。
基於亞里士多德的解釋,伽利略做了一個簡單推論:既然重的更快落地,那麼10斤鐵球應該比5斤鐵球更快落地。
數據驗證(證僞)了該推論:兩個球同時落地,從而徹底推翻了亞里士多德的理論。
該案指出了大多數人使用數據的誤區:數據導向,邏輯附和。
即先有統計結果,再倒過來想解釋、拼湊理論,是當前經管類學術文獻的通病,不要低估人自圓其說的能力,約束自身非理性就是行爲金融學的應用。
恰當的姿勢應當是:邏輯導向,數據驗證。
觀察到現象,先有理論的推導、得出合情假設,再用數據去驗證,如此纔可能是有意義的研究。
關鍵在於邏輯的推演,並提出可以用數據驗證的預測(假說)。數據是死的,它任人擺佈、沒有可推演性、不具有證明能力,但邏輯不是這樣,數據的價值只在於對嚴密邏輯的驗證。
例9:看似規律性的股價圖(隨機數據也會給人規律性的錯覺)
圖1是《漫步華爾街》的一張圖,它顯示的是一隻初始價格爲50美元,隨後每天的收盤價由拋硬幣決定:如果是正面則漲0.5個百分點,反之則下跌0.5個百分點。
換言之,從概率視角看,這隻假想股票的走勢圖由隨機的拋硬幣決定,它本身也是隨機、無規律可言的。
多數人眼中的“規律性”可能只是“統計幻覺”的結果,這是對人性弱點的揭示。
對歷史的覆盤,尤其是低頻的歷史事件,我們要警惕“頻率”倒推“概率”。
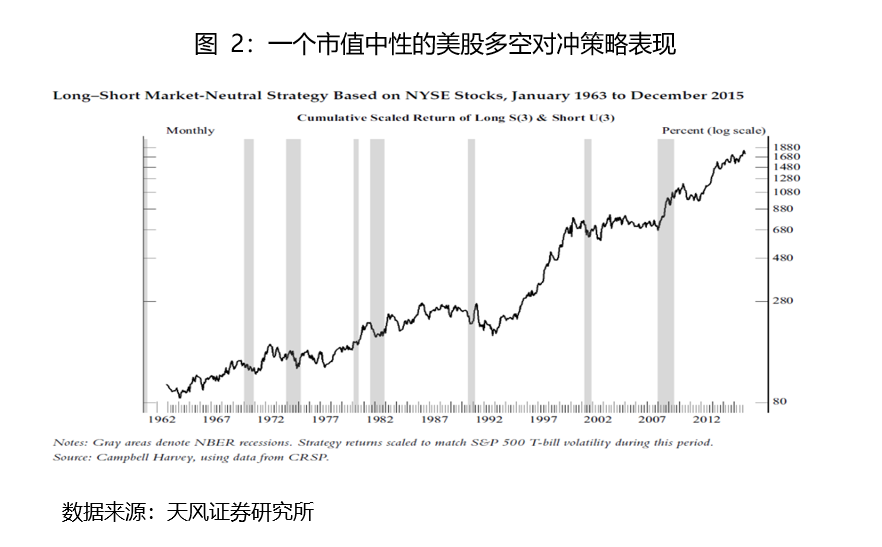
例10:樣本內外均有效的策略(多數人低估了歷史回測產生偶然高收益的可能)
僅僅基於圖2中的回測數據,不少人或許已經迫不及待想要投資了。
事實上,該策略是數據挖掘的結果,就是簡單買入美股代碼前三個字母中帶有S的股票,並做空前三個字母含有U的股票,這是機器學習方法,在成千上萬個策略中選擇出來的表現最好的策略。
瞭解了這些大家可能不再願意接受它,這只是因爲其原理已經荒誕到了足夠的程度,至於其他能扯上一點所謂合理解釋的反覆拷問結果,就本質而言,又有什麼區別?“似是而非”的危害遠大於明顯荒誕,因爲前者還有“似是”的成分,更具迷惑性,結果卻是一樣的。
多數人其實低估了回測中產生偶然高收益的可能性,事後迎合着給出合理解釋,並不能降低預判未來的不確定性。
綜上所述,我們通過10個案例介紹了常見的數據誤用,並提出了“邏輯導向,數據驗證”的研究思路。需要注意的是,指出數據應用的誤區,並不是要否定數據本身,而是站在數據接受者的角度,探討如何更加客觀地用好可得的數據。
數據不會說話,數據不可論證,數據是死的,但人是活的。



