世界盃將是壓垮Twitter的最後一根稻草?歷經馬斯克“血洗”後,全世界在等Twitter宕機

歡迎關注“新浪科技”的微信訂閱號:techsina
整理/褚杏娟、核子可樂
來源:AI前線(ID:ai-front)
有報道稱,卡塔爾世界盃可能是壓垮Twitter的最後一根稻草。一位離職的Twitter員工對外媒表示,Twitter有50%的概率會在爲期29天的世界盃期間發生重大服務中斷。他認爲,Twitter在世界盃期間肯定會發生一些事故,比如服務響應緩慢或錯誤,用戶能看到的概率有90%。
當被問及Twitter有什麼計劃來解決世界盃期間可能出現的問題時,他說:“據我所知沒有。我們本應該在幾周前就開始準備了。”
1
關鍵運行團隊離開,Twitter故障問題初顯
曾應對過2014年世界盃的Twitter前軟件工程師JohnIoannidis表示,即使擁有最好的設備和硬件,突然湧入的流量也會造成問題。根據Ioannidis介紹,2014年巴西世界盃時,Twitter一直在監控自己的基礎設施,以確保整個世界盃期間保持在線。據悉,2010年世界盃期間,Twitter就因無法應對高流量而下線。
對比賽期間可能出現的高流量,薩里大學網絡安全教授AlanWoodward感到十分擔憂,“Twitter現在似乎在賭運氣,根據我的經驗,這不是一種可靠的方法。”
而實際上,在世界盃開始前,已經有跡象表明Twitter背後錯綜複雜的基礎設施已經出現問題,如轉發無法正常使用、雙重身份驗證報錯致難以登陸、保存的草稿莫名被刪除等。
當然,造成這些擔憂和問題的直接原因就是現在的Twitter確實沒有足夠的工程師來進行準備和維護工作。據媒體稱,Twitter負責流量高峯期管理網站的團隊已經有三分之一的工程師離職,另外Twitter核心系統庫的團隊也已經解散,有前員工形容“沒有這個團隊,你就無法運營Twitter。”其他如前端團隊、API團隊等也都沒有幸免於難。
“我知道有六個關鍵系統(比如推送的關鍵系統)已經沒有任何工程師了”,有Twitter的前員工表示,“這個系統甚至不再有骨幹人員。它會繼續自動運行,直到遇到什麼東西,然後就會停下來。”
實際上,在3500名員工被裁、2000多人主動離職後,Twitter原來維護網站正常運行的幾個關鍵團隊都部分或全部解散。其中,在馬斯克發出“最後通牒”後辭職的員工中,許多人是Twitter最有經驗的員工,甚至有些人在Twitter工作的時間是這家公司存在時間的一半。
有Twitter員工透露,由於目前維護關鍵服務的全天候輪班員工不夠用,這部分員工已經開始外出“借人”,試圖通過培訓公司其他部門的同事來幫助減輕工作量。另一方面,馬斯克的“鐵血裁員”也落下了帷幕,目前開始正在招聘工程師和廣告銷售人員。“在關鍵的招聘方面,我想說那些擅長編寫軟件的人是最優先的。”馬斯克在最近的全體員工大會上表示。
“最優秀的人都留下來了,所以我不是特別擔心。”馬斯克18日發推說道。
雖然馬斯克很樂觀,但網上很多開發者認爲Twitter出現故障在所難免。“他(馬斯克)有從根本上改變堆棧的宏偉願景。他的更改不會有適當的測試,因爲所有高級工程師都離開了,他的SRE員工不在那裏監控新功能或進行容量規劃。所以剩下的很多將是擁有H1B簽證的工程師,他們不能離開,無法反駁馬斯克的要求,而且會過度勞累,變得足夠‘硬核’,無情地工作、精疲力盡、不做應有的努力。Twitter將出現一些重大中斷,過去處理過這些事件的大多數人都離開了。因此,這將比我們以往看到的任何情況都更嚴重、持續時間更長。”
當然也有開發者表示,“如果什麼都不改變,那麼什麼都不會破壞。我想如果有什麼問題的話,他們會在部署新東西同時不破壞其他功能時遇到問題。問題將發生在開發服務器上,而不是生產服務器上。”
倫敦大學教授StevenMurdoch認爲,Twitter將難以處理複雜的故障。他表示,即使公司僱用新員工或重新分配現有員工的任務,而且交接過程順利,這些人瞭解相關係統的工作方式也可能需要幾個月的時間。
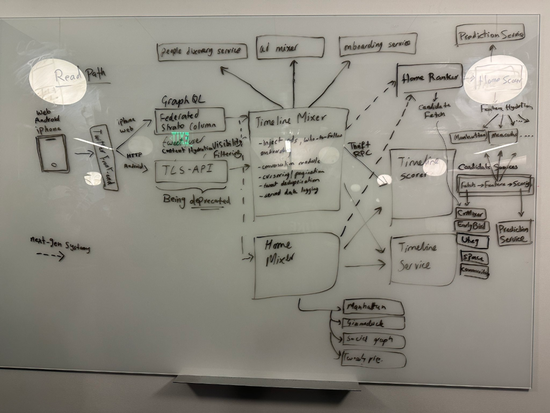
馬斯克發佈的Twitter“架構圖”
2
爲什麼還沒有宕機?
從硬件到軟件/代碼,可能導致Twitter宕機的原因有很多。一位擁有10年以上行業經驗的SRE總結了五十多個影響因素,包括簡單錯誤代碼問題、硬盤驅動器已滿,到大型活動、外部攻擊等等。
雖然現在有問題出現,但Twitter還可以繼續運行,新的推文仍不斷湧現。在Twitter工作五年的站點可靠性工程師(SRE)MatthewTejo在自己的文章中介紹了Twitter至今沒有宕機的原因:前期大量投入的自動化設施。Matthew有四年的時間是Twitter緩存團隊裏的唯一SRE,負責自動化、可靠性和運營工作,設計並實現了大部分保持功能運行的工具。
緩存承載着用戶在網站上看到的大部分內容。推文、所有時間線、直接消息、廣告、身份驗證等,都是由緩存團隊的服務器負責提供。一旦緩存出現問題,用戶會立刻受到顯性影響。
Matthew加入團隊後的第一個項目,就是將退役的舊設備換成新機器。當時根本就沒有相應的工具或者自動化選項,Matthew拿到的只有一份標記着服務器名稱的電子表格。不過現在好緩存團隊的運營已經升級完畢,不再像當初那麼粗糙。
Matthew介紹,Twitter保證緩存運行的頭號大事,就是把它們放在Mesos上以Aurora作業的形式運行。Aurora會找到運行應用程序的服務器,Mesos則將所有服務器聚合起來以供Aurora感知。Aurora還會在應用程序啓動後保持其運行。如果說一個緩存集羣需要100臺服務器,那Aurora就會盡量保持這100臺全部運行。
如果服務器出於某種原因而斷開,Mesos能及時檢測到問題,將有問題的服務器從聚合池中刪除,這時候Aurora會知道只有99臺緩存服務器在運行。於是,Aurora會自動再找臺服務器接入,將總數恢復到100。整個流程全面自動化,無需任何人爲參與。
在Twitter數據中心,服務器被安置在機架當中。機架上的服務器通過交換機設備與其他服務器連接。再往外走,這些設備再通過交換機和路由器繼續擴展,最終建立起完整的複雜系統、接入互聯網。單個機架可以容納20到30臺服務器。其中機架可能發生故障、交換機可能損壞、電源也可能宕掉,導致全部20臺服務器陷入停機。
Aurora和Mesos另一大優勢就是確保不會把太多應用程序放進同一個機架。這樣即使整個機架突然停轉,Aurora和Mesos也能找到新的服務器並把應用負載轉移過去,不致影響到用戶感受。
“在我之前提到的電子表格裏,還記錄着機架上的服務器數量。能感受到,前任管理員在努力保證每個機架上別塞進太多服務器。而現在我們有了更強大的工具,能夠持續追蹤每一臺新接入的服務器,所以整個流程就更順暢了。這些工具能夠確保團隊在各機架上均衡部署物理服務器,而且一切都會以故障發生時不致引起大麻煩的方式進行排布。”Matthew表示。
不過,Mesos沒辦法切實檢測到每一項服務器故障,所以Matthew團隊還得對硬件問題進行額外的監控,關注磁盤和內存損壞之類的問題。這些情況不一定會拖垮整臺服務器,但卻往往導致其運行緩慢。“我們有一個警報儀表板,可以掃描損壞的服務器。一旦檢測到某服務器發生問題,我們會自動創建一項修復任務,引導數據中心的運維人員前往查看。”
緩存團隊還掌握着另一款重要軟件(服務)用於跟蹤緩存集羣時間。如果在短時間內有大量服務器被標記爲宕機,則要求關閉緩存的新任務將被拒絕,直到恢復安全。Matthew團隊希望通過這種方式避免整個緩存集羣被關閉,進而拖垮受其保護的服務體系。
他們還解決了警報太多而無法快速關閉、無法通過一次維護解決的大規模報錯、Aurora找不到足夠的新服務器來容納舊任務等各類問題。“要爲檢測到的損壞服務器創建修復任務,我們首先會檢查這項服務來確定能否安全刪除其中的作業。在損壞服務器被清空之後,即會獲得安全標記,由數據中心技術人員前往處理。處置完成、標記切換爲已修復之後,我們會再次使用工具查找並自動激活該服務器,讓它重新承載和運行作業。整個流程中,唯一需要的人手就是數據中心內的運維技術人員(不知道他們還在不在崗)。”Matthew介紹道。
另外,重複申請的問題也得到了解決。之前的一些bug會導致無法重新添加新的緩存服務器(啓動時出現了競爭條件),有時候可能需要長達10分鐘才能重新添加服務器(O(n^n)邏輯)。有了自動化系統處理後,團隊不致於被迫選擇手動操作。當然,還有其他自動修復設計,例如在某些應用程序指標(例如延遲)處於異常值時自動重啓任務。
Matthew表示,“緩存團隊每週大概會積累下一頁的故障報告,但幾乎不出過什麼大問題。大多數情況下,我們就在那裏靜靜值班、靜靜下班,啥事都沒發生。”
容量規劃也是Twitter平臺仍在正常運行的重要原因之一。Twitter有兩個持續運行的數據中心,負責承載整個站點的故障。Twitter的每一項重要服務都可以在其中一處數據中心內單獨運行,意味着隨時都有200%的可用容量儲備。當然,這是在災難恢復的場景下;大部分時間裏,兩處數據中心會把閒置資源拿來承載業務流量,且利用率最多不超過50%。
即使如此,整個運行實踐也非常繁忙。當Matthew團隊計算自己的容量需求時,要先確定一處數據中心需要多少設備來承載全部流量,再以此爲基礎額外增加淨空。所以只要不在故障轉移期內,就會有大量服務器空間用於承載額外流量。數據中心發生整體故障的情況非常罕見,Matthew任職的五年中只經歷過一次。
緩存團隊還把緩存集羣剝離開來,並沒有選擇用單一多租戶集羣來承載所有服務,而是在應用程序層級進行隔離。這點非常重要,因爲一旦某個集羣出現問題,它的爆炸半徑也只在自身範圍內,即僅影響處於同一位置的部分服務器。同樣地,Aurora會提供緩存分佈,儘可能控制影響範圍,最終監控並及時加以修復。
“所以大家應該知道了,我們這幫傢伙可沒有偷懶。我們跟緩存即服務團隊隨時交流,儘量推動自動化流程,研究了不少有趣的性能問題,嘗試引入能改善體驗的技術,並推動了一系列大型成本節約項目。我們進行容量規劃、確定需要訂購的服務器數量,總之挺忙的。反正,我們不像很多人想象的那樣天天摸魚、打遊戲就能拿高薪。”Matthew在文章最後打趣道。
“恰恰相反,該網站在如此大規模裁員後仍能全面運行這一事實證明了參與維護基礎設施的每一位專業人員都表現卓越!”有網友評價道。
參考鏈接:
https://www.theguardian.com/technology/2022/nov/19/twitter-crashing-world-cup-elon-musk-social-media-traffic-spikes
https://www.theverge.com/2022/11/17/23465274/hundreds-of-twitter-employees-resign-from-elon-musk-hardcore-deadline
https://threadreaderapp.com/thread/1593541177965678592.html
https://matthewtejo.substack.com/p/why-twitter-didnt-go-down-from-a








