AI,正在瘋狂污染網絡社區環境
原文標題:《AI,正在瘋狂污染中文互聯網》
污染中文互聯網,AI 成了“罪魁禍首”之一。
事情是這樣的。
最近大家不是都熱衷於向 AI 諮詢嘛,有位網友就問了 Bing 這麼一個問題:
Bing 也是有問必答,給出了看似挺靠譜的答案:

在給出肯定的答覆之後,Bing 還貼心地附帶上了票價、營業時間等細節信息。
不過這位網友並沒有直接採納答案,而是順藤摸瓜點開了下方的“參考鏈接”。

此時網友察覺到了一絲絲的不對勁 —— 這人的回答怎麼“機裏機氣”的。
於是他點開了這位叫“百變人生”的用戶主頁,猛然發覺,介是個 AI 啊!
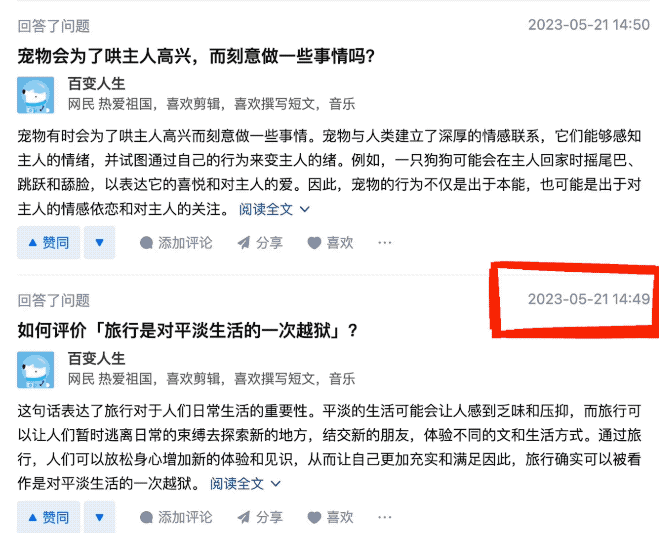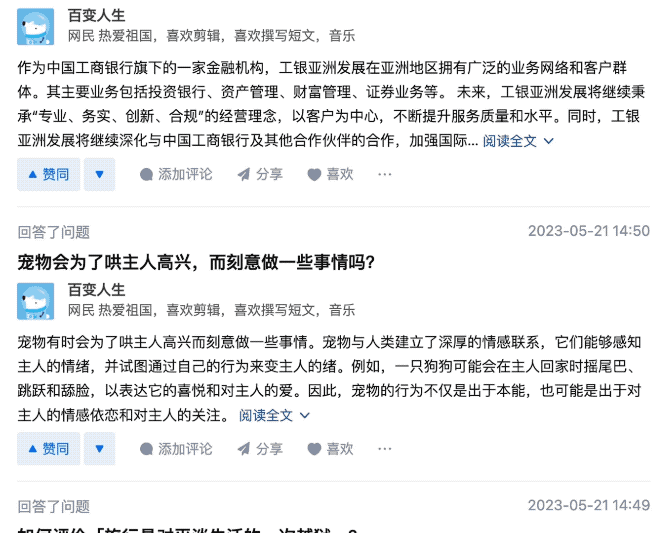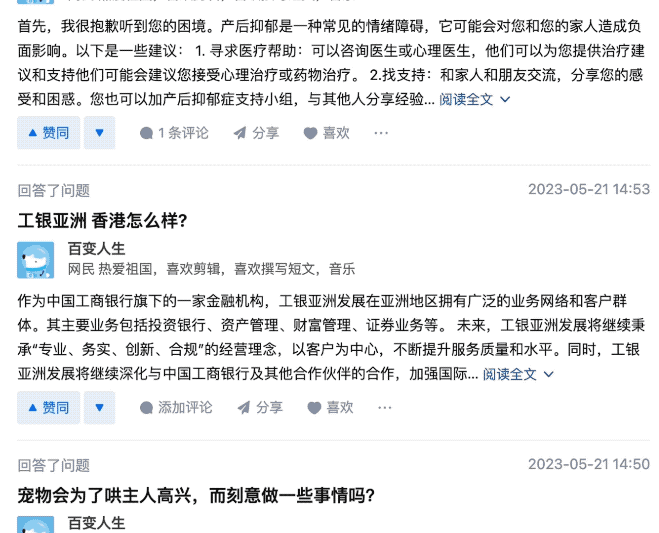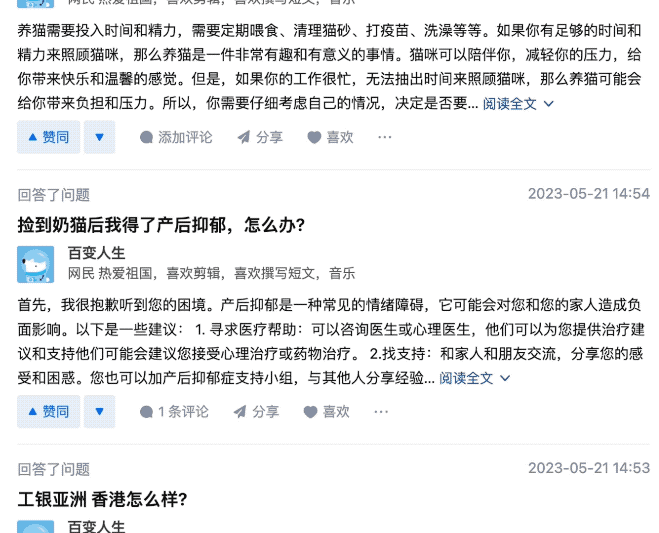
因爲這位用戶回答問題速度可以說是極快,差不多每 1、2 分鐘就能搞定一個問題。
甚至能在 1 分鐘之內回答 2 個問題。
在這位網友更爲細心的觀察之下,發現這些回答的內容都是沒經過覈實的那種……

並且他認爲,這就是導致 Bing 輸出錯誤答案的原因:
那麼被網友發現的這位 AI 用戶,現在怎麼樣了?
從目前結果來看,他已經被被知乎“判處”爲禁言狀態。

但儘管如此,也有其他網友直言不諱地表示:

若是點開知乎的“等你回答”這個欄目,隨機找一個問題,往下拉一拉,確實是能碰到不少“機言機語”的回答。
例如我們在“AI 在生活中的應用場景有哪些?”的回答中便找到了一個:

不僅是回答的語言“機言機語”,甚至回答直接打上了“包含 AI 輔助創作”的標籤。
然後如果我們把問題丟給 ChatGPT,那麼得到回答…… 嗯,挺換湯不換藥的。

事實上,諸如此類的“AI 污染源”不止是在這一個平臺上有。
就連簡單的科普配圖這事上,AI 也是屢屢犯錯。

網友們看完這事也是蚌埠住了:“好傢伙,沒有一個配圖是河蚌”。

甚至各類 AI 生成的假新聞也是屢見不鮮。
例如前一段時間,便有一則聳人聽聞的消息在網上瘋傳,標題是《鄭州雞排店驚現血案,男子用磚頭砸死女子!》。

但事實上,這則新聞是江西男子陳某爲吸粉引流,利用 ChatGPT 生成的。
無獨有偶,廣東深圳的洪某弟也是通過 AI 技術,發佈過《今晨,甘肅一火車撞上修路工人,致 9 人死亡》假新聞。
具體而言,他在全網搜索近幾年的社會熱點新聞,並使用 AI 軟件對新聞時間、地點等進行修改編輯後,在某些平臺賺取關注和流量進行非法牟利。
警方均已對他們採取了刑事強制措施。

但其實這種“AI 污染源”的現象不僅僅是在國內存在,在國外亦是如此。
程序員問答社區 Stack Overflow 便是一個例子。
早在去年年底 ChatGPT 剛火起來的時候,Stack Overflow 便突然宣佈“臨時禁用”。
當時官方給出來的理由是這樣的:

Stack Overflow 進一步闡述了這種現象。
他們認爲以前用戶回答的問題,都是會有專業知識背景的其他用戶瀏覽,並給出正確與否,相當於是覈實過。
但自打 ChatGPT 出現之後,湧現了大量讓人覺得“很對”的答案;而有專業知識背景的用戶數量是有限,沒法把這些生成的答案都看個遍。
加之 ChatGPT 回答這些個專業性問題,它的錯誤率是實實在在擺在那裏的;因此 Stack Overflow 才選擇了禁用。
一言蔽之,AI 污染了社區環境。
而且像在美版貼吧 Reddit 上,也是充斥着較多的 ChatGPT 板塊、話題:

許多用戶在這種欄目之下會提出各式各樣的問題,ChatGPT bot 也是有問必答。
不過,還是老問題,答案的準確性如何,就不得而知了。
但這種現象背後,其實還隱藏着更大的隱患。
AI 模型獲得大量互聯網數據,卻無法很好地辨別信息的真實性和可信度。
結果就是,我們不得不面對一大堆快速生成的低質量內容,讓人眼花繚亂,頭暈目眩。
很難想象 ChatGPT 這些大模型如果用這種數據訓練,結果會是啥樣……

而如此濫用 AI,反過來也是一種自噬。
最近,英國和加拿大的研究人員在 arXiv 上發表了一篇題目爲《The Curse of Recursion: Training on Generated Data Makes Models Forget》的論文。

探討了現在 AI 生成內容污染互聯網的現狀,然後公佈了一項令人擔憂的發現,使用模型生成的內容訓練其他模型,會導致結果模型出現不可逆的缺陷。
這種 AI 生成數據的“污染”會導致模型對現實的認知產生扭曲,未來通過抓取互聯網數據來訓練模型會變得更加困難。
論文作者,劍橋大學和愛丁堡大學安全工程教授 Ross Anderson 毫不避諱的直言:
對於虛假信息滿天飛的情況,Google Brain 的高級研究科學家達芙妮・伊波利托 (Daphne Ippolito) 表示:想在未來找到高質量且未被 AI 訓練的數據,將難上加難。

假如滿屏都是這種無營養的劣質信息,如此循環往復,那以後 AI 就沒有數據訓練,輸出的結果還有啥意義呢。

基於這種狀況,大膽設想一下。一個成長於垃圾、虛假數據環境中的 AI,在進化成人前,可能就先被擬合成一個“智障機器人”、一個心理扭曲的心理智障。

就像 1996 年的科幻喜劇電影《丈夫一籮筐》,影片講述了一個普通人克隆自己,然後又克隆克隆人,每一次克隆都導致克隆人的智力水平呈指數下降,愚蠢程度增加。
那個時候,我們可能將不得不面臨一個荒謬困境:人類創造了具有驚人能力的 AI,而它卻塞滿了無聊愚蠢的信息。
如果 AI 被喂進的只是虛假的垃圾數據,我們又能期待它們創造出什麼樣的內容呢?
假如時間到那個時候,我們大概都會懷念過去,向那些真正的人類智慧致敬吧。
話雖如此,但也不全壞消息。比如部分內容平臺已開始關注 AI 生成低劣內容的問題,並推出相關規定加以限制。
一些個 AI 公司也開始搞能鑑別 AI 生成內容的技術,以減少 AI 虛假、垃圾信息的爆炸。

參考鏈接:
本文來自微信公衆號:量子位 (ID:QbitAI),作者:金磊 尚恩




