可提前15年预知痴呆风险,复旦团队发现重要血浆生物标志物

发布的研究。 本文图片 复旦大学研究团队供图
你能想象仅凭一滴血的检测化验,就知道患上痴呆症的风险有多高吗?通过血浆的蛋白检测,人类可提前15年预知痴呆发病风险。不久的将来,人们从血检报告单上,就能提前知道有多大几率患上痴呆症。
复旦大学类脑智能科学与技术研究院冯建峰教授、程炜研究员团队联合复旦大学附属华山医院郁金泰教授团队展开联合攻关,采用大规模蛋白质组学数据和人工智能算法发现了预测未来痴呆风险的重要血浆生物标志物,可提前15年预测痴呆发病风险,对痴呆高危人群的筛查和早期干预具有重大意义。
北京时间2024年2月13日凌晨,这一研究成果以《血浆蛋白质组学预测健康成年人未来痴呆风险》(Plasma proteomic profiles predict future dementia in healthy adults)为题,发表在《自然·衰老》(Nature Aging)。
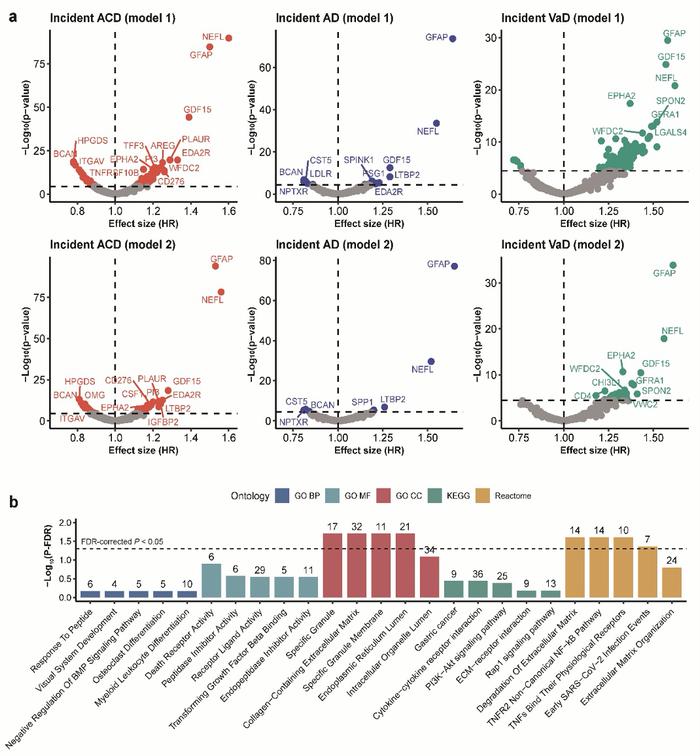
研究发现:1463种血浆蛋白质与新发ACD、AD和VaD的关联。
采用人工智能技术,分析1463种血浆蛋白组学数据
研究团队指出,以阿尔茨海默病为代表的痴呆症,已成为严重影响居民健康和经济发展的重大公共卫生问题。在临床症状出现前,痴呆症存在数年甚至数十年的隐匿期,15-20年可能无症状,早期表现容易与正常老化相混淆。当患者出现显著认知行为障碍等症状,前往医院就诊时,疾病往往已进展到中晚期,错过干预的最佳时期,医生也束手无策。
在这项研究中,团队研究运用AI for science(注:人工智能驱动的科学研究,下文简称AI4S),采用迄今为止全球最大规模的基于社区队列的蛋白质组学数据和人工智能算法,对1463种血浆蛋白组学数据进行了分析和建模,发现GFAP、NEFL和GDF15三个蛋白与新发全因痴呆(ACD)、新发阿尔茨海默病(AD)和新发血管性痴呆(VaD)三种常见痴呆类型的风险有显著关联,并且LTBP2也与痴呆发病关联密切。
“我们的研究提供了一个很好的AI4S的研究范例,基于数据驱动的思想,我们构建出高精度的痴呆风险预测模型,这是理工医交叉融合的突破进展,对推动精准医疗的发展具有重要意义,”冯建峰介绍,与以往类似研究使用采用的小样本量横断面设计不同,此次复旦团队运用大样本、长时间的纵向数据,从中提炼有用的模式、趋势和关联信息,强调让数据“说话”。
团队使用大样本队列数据,对52645名非痴呆成年人的血液数据进行跨度超过中位数14年的追踪分析,参与者中后来有1417位被诊断为新发全因痴呆(ACD),691位被诊断为新发阿尔兹海默病(AD),285位被诊断为新发血管性痴呆(VaD)。团队通过基于抗体的Olink测定技术进行统一测定量化,对每个血液样本检测了包含心脏代谢、炎症、神经和肿瘤四个面板上的1463种血浆蛋白,并运用Cox模型和机器学习算法开展建模分析,最终识别出GFAP、NEFL和GDF15等对痴呆预测极具价值的血浆生物标志物。
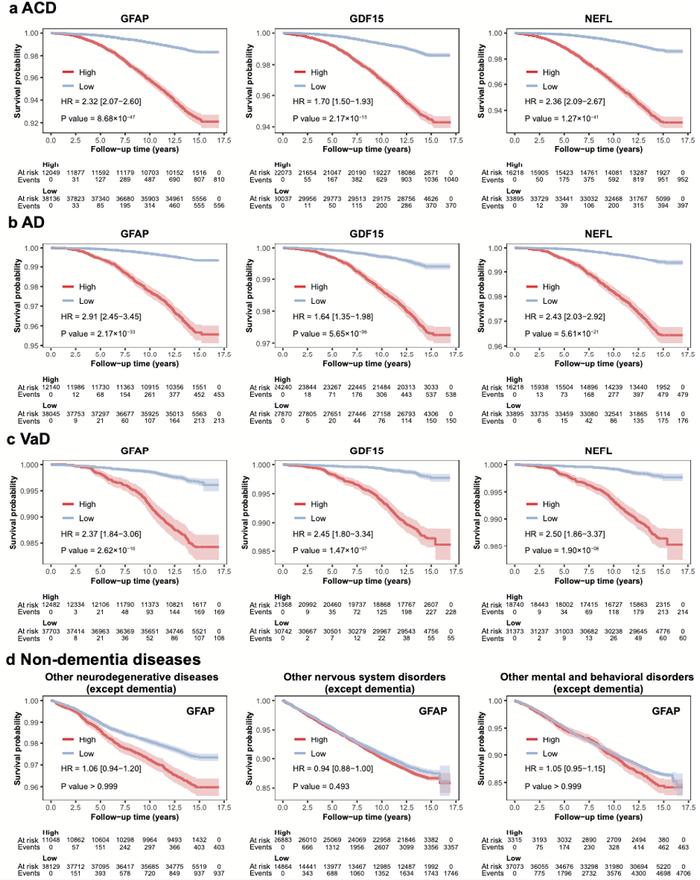
不同血浆蛋白水平与疾病临床进展风险的关联。
探讨将相关检测加入体检项目的可能性
为进一步提高预测的准确性,研究团队将蛋白质筛选过程转化为一个优化组合的数学问题。通过运用信息增益和轻量提升机等基于机器学习的算法,成功挖掘出对早期识别痴呆最为有效的蛋白质组合。这些算法不仅考虑了单个蛋白质的作用,还充分考虑了蛋白质之间的相互作用和协同效应,从而可实现更高精度的预测。为确保模型的可靠性和稳定性,团队在不同亚组人群中进行多重验证,模型均表现出良好的预测性能,为痴呆症的早期识别提供了有力工具。
“血液学检测方便无创、价格低廉,可作为临床前阶段对广大人群进行早期风险筛查的理想工具。”程炜解释说,现在团队发现蛋白组学与脑疾病风险间的关联,通过验血,就有望辅助临床医生尽早识别痴呆高危患者,尽早干预,提高病人的生活质量。
郁金泰同时表示:“这次发现的重要血浆生物标志物,为血液学检测从研究到临床的过渡提供新的理论基础。而且我们这次建立的模型更加简便、易获取、易于普及,无论是短期痴呆发病风险还是十余年后的痴呆发病风险,都能做到很好地预测。”
随着这项研究的发布,距离应用于普通民众痴呆症风险检测还有多远?
上述研究团队介绍,如果一切顺利,半年后可应用到临床检测,筛查出高危人群。目前,部分体检医疗机构已主动与团队取得联系,探讨将相关检测加入体检项目的可能性。下一步,团队还将围绕我国的痴呆症风险人群队列开展数据采集和交叉验证,针对我国人群队列的基线水平对相关数据作出矫正,开发出最适合我国人群队列的痴呆症风险预测数据模型。






