可提前15年預知癡呆風險,復旦團隊發現重要血漿生物標誌物

發佈的研究。 本文圖片 復旦大學研究團隊供圖
你能想象僅憑一滴血的檢測化驗,就知道患上癡呆症的風險有多高嗎?通過血漿的蛋白檢測,人類可提前15年預知癡呆發病風險。不久的將來,人們從血檢報告單上,就能提前知道有多大幾率患上癡呆症。
復旦大學類腦智能科學與技術研究院馮建峯教授、程煒研究員團隊聯合復旦大學附屬華山醫院鬱金泰教授團隊展開聯合攻關,採用大規模蛋白質組學數據和人工智能算法發現了預測未來癡呆風險的重要血漿生物標誌物,可提前15年預測癡呆發病風險,對癡呆高危人羣的篩查和早期干預具有重大意義。
北京時間2024年2月13日凌晨,這一研究成果以《血漿蛋白質組學預測健康成年人未來癡呆風險》(Plasma proteomic profiles predict future dementia in healthy adults)爲題,發表在《自然·衰老》(Nature Aging)。
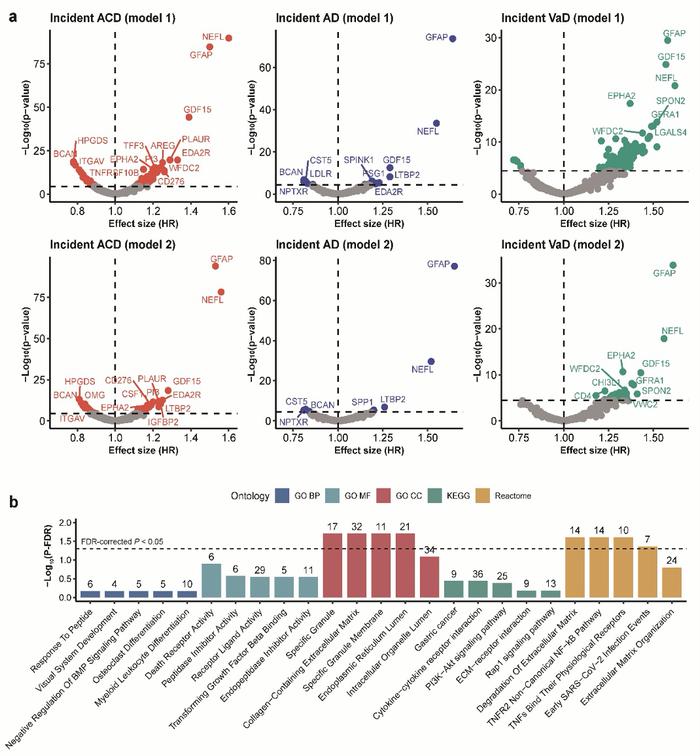
研究發現:1463種血漿蛋白質與新發ACD、AD和VaD的關聯。
採用人工智能技術,分析1463種血漿蛋白組學數據
研究團隊指出,以阿爾茨海默病爲代表的癡呆症,已成爲嚴重影響居民健康和經濟發展的重大公共衛生問題。在臨牀症狀出現前,癡呆症存在數年甚至數十年的隱匿期,15-20年可能無症狀,早期表現容易與正常老化相混淆。當患者出現顯著認知行爲障礙等症狀,前往醫院就診時,疾病往往已進展到中晚期,錯過干預的最佳時期,醫生也束手無策。
在這項研究中,團隊研究運用AI for science(注:人工智能驅動的科學研究,下文簡稱AI4S),採用迄今爲止全球最大規模的基於社區隊列的蛋白質組學數據和人工智能算法,對1463種血漿蛋白組學數據進行了分析和建模,發現GFAP、NEFL和GDF15三個蛋白與新發全因癡呆(ACD)、新發阿爾茨海默病(AD)和新發血管性癡呆(VaD)三種常見癡呆類型的風險有顯著關聯,並且LTBP2也與癡呆發病關聯密切。
“我們的研究提供了一個很好的AI4S的研究範例,基於數據驅動的思想,我們構建出高精度的癡呆風險預測模型,這是理工醫交叉融合的突破進展,對推動精準醫療的發展具有重要意義,”馮建峯介紹,與以往類似研究使用採用的小樣本量橫斷面設計不同,此次復旦團隊運用大樣本、長時間的縱向數據,從中提煉有用的模式、趨勢和關聯信息,強調讓數據“說話”。
團隊使用大樣本隊列數據,對52645名非癡呆成年人的血液數據進行跨度超過中位數14年的追蹤分析,參與者中後來有1417位被診斷爲新發全因癡呆(ACD),691位被診斷爲新發阿爾茲海默病(AD),285位被診斷爲新發血管性癡呆(VaD)。團隊通過基於抗體的Olink測定技術進行統一測定量化,對每個血液樣本檢測了包含心臟代謝、炎症、神經和腫瘤四個面板上的1463種血漿蛋白,並運用Cox模型和機器學習算法開展建模分析,最終識別出GFAP、NEFL和GDF15等對癡呆預測極具價值的血漿生物標誌物。
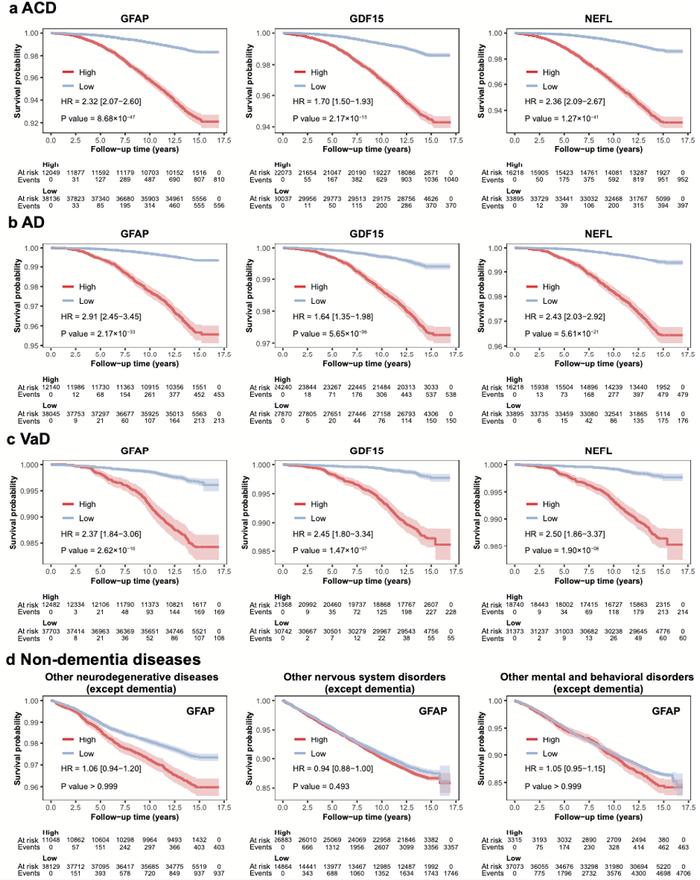
不同血漿蛋白水平與疾病臨牀進展風險的關聯。
探討將相關檢測加入體檢項目的可能性
爲進一步提高預測的準確性,研究團隊將蛋白質篩選過程轉化爲一個優化組合的數學問題。通過運用信息增益和輕量提升機等基於機器學習的算法,成功挖掘出對早期識別癡呆最爲有效的蛋白質組合。這些算法不僅考慮了單個蛋白質的作用,還充分考慮了蛋白質之間的相互作用和協同效應,從而可實現更高精度的預測。爲確保模型的可靠性和穩定性,團隊在不同亞組人羣中進行多重驗證,模型均表現出良好的預測性能,爲癡呆症的早期識別提供了有力工具。
“血液學檢測方便無創、價格低廉,可作爲臨牀前階段對廣大人羣進行早期風險篩查的理想工具。”程煒解釋說,現在團隊發現蛋白組學與腦疾病風險間的關聯,通過驗血,就有望輔助臨牀醫生儘早識別癡呆高危患者,儘早干預,提高病人的生活質量。
鬱金泰同時表示:“這次發現的重要血漿生物標誌物,爲血液學檢測從研究到臨牀的過渡提供新的理論基礎。而且我們這次建立的模型更加簡便、易獲取、易於普及,無論是短期癡呆發病風險還是十餘年後的癡呆發病風險,都能做到很好地預測。”
隨着這項研究的發佈,距離應用於普通民衆癡呆症風險檢測還有多遠?
上述研究團隊介紹,如果一切順利,半年後可應用到臨牀檢測,篩查出高危人羣。目前,部分體檢醫療機構已主動與團隊取得聯繫,探討將相關檢測加入體檢項目的可能性。下一步,團隊還將圍繞我國的癡呆症風險人羣隊列開展數據採集和交叉驗證,針對我國人羣隊列的基線水平對相關數據作出矯正,開發出最適合我國人羣隊列的癡呆症風險預測數據模型。






