英偉達B200打破摩爾定律,老黃順便公開GPT-4的祕密
夢晨 克雷西 發自 凹非寺
量子位 | 公衆號 QbitAI
整個AI圈最想知道的祕密,被老黃在PPT某頁的小字裏寫出來了?

時隔兩年,英偉達官宣新一代Blackwell架構,爲AI帶來30倍推理加速。定位直指“新工業革命的引擎” 。
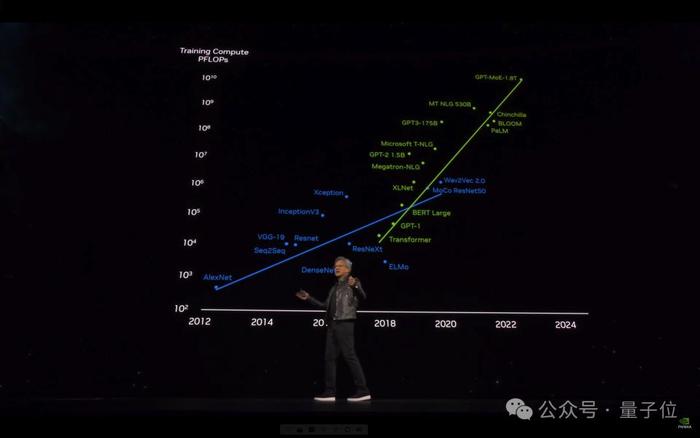
老黃PPT中拿了一個1.8萬億參數MoE的GPT系列大模型測試結果來證明。
眼尖的網友當場就盯上了這行不起眼的小字,截圖發出神祕暗號。
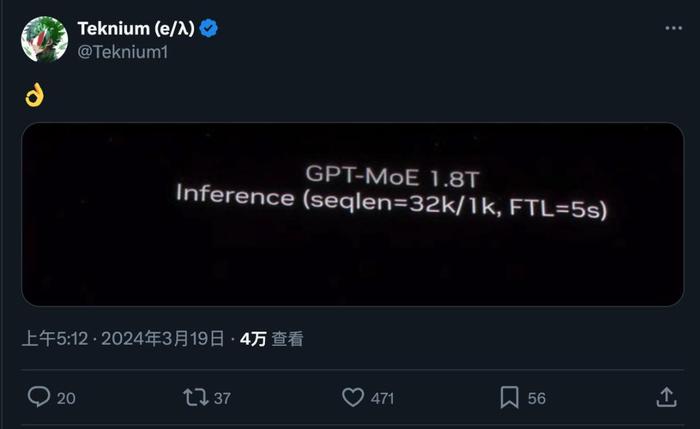
1.8萬億參數、MoE架構,與初代GPT-4的細節傳聞一毛一樣,32k序列長度也能對得上。
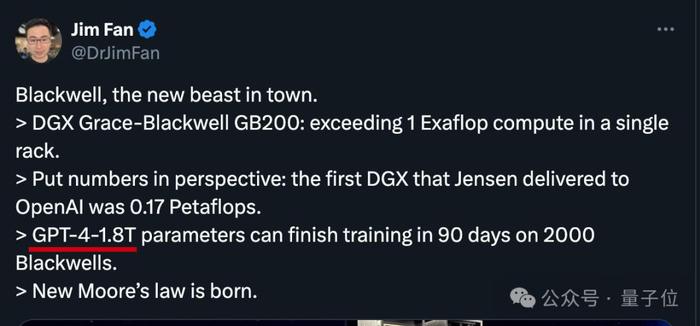
剛升任研究經理不久的英偉達科學家Jim Fan,甚至直接攤牌了。
表達摩爾定律已經限制不住英偉達了的同時,直接點破了這層窗戶紙。
不過個祕密之所以能以這種形式半官方確認,很可能說明對OpenAI來說已經無關緊要了。
很多人相信,最新版gpt-4-turbo經過一輪輪的優化,已經蒸餾到更小規模。

說回到英偉達GTC大會本身,作爲架構更新的大年,老黃的主題演講亮點頗多:
宣佈GPU新核彈B200,超級芯片GB200
Blackwell架構新服務器,一個機櫃頂一個超算
推出AI推理微服務NIM,要做世界AI的入口
新光刻技術cuLitho進駐臺積電,改進產能。
……

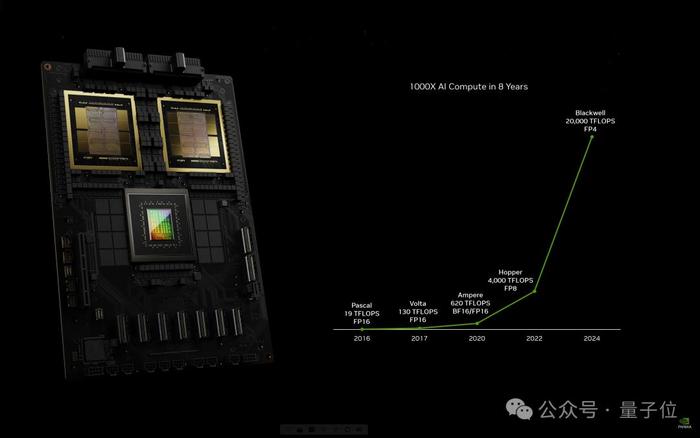
8年時間,AI算力已增長1000倍。
老黃斷言“加速計算到達了臨界點,通用計算已經過時了”。
我們需要另一種方式來進行計算,這樣我們才能夠繼續擴展,這樣我們才能夠繼續降低計算成本,這樣我們才能夠繼續進行越來越多的計算。
老黃這次主題演講題目爲《見證AI的變革時刻》,但不得不說,英偉達纔是最大的變革本革。
GPU的形態已徹底改變
我們需要更大的GPU,如果不能更大,就把更多GPU組合在一起,變成更大的虛擬GPU。
Blackwell新架構硬件產品線都圍繞這一句話展開。
通過芯片,與芯片間的連接技術,一步步構建出大型AI超算集羣。
4nm製程達到瓶頸,就把兩個芯片合在一起,以10TB每秒的滿血帶寬互聯,組成B200 GPU,總計包含2080億晶體管。
內存也直接翻倍,高達192GB的HBM3e高速內存。
沒錯,B100型號被跳過了,直接發佈的新架構首個GPU就是B200。

兩個B200 GPU與Grace CPU結合就成爲GB200超級芯片,通過900GB/s的超低功耗NVLink芯片間互連技術連接在一起。
兩個超級芯片裝到主板上,成爲一個Blackwell計算節點。

18個這樣的計算節點共有36CPU+72GPU,組成更大的“虛擬GPU”。
它們之間由今天宣佈的NVIDIA Quantum-X800 InfiniBand和Spectrum™-X800以太網平臺連接,可提供速度高達800Gb/s的網絡。

在NVLink Switch支持下,最終成爲“新一代計算單元”GB200 NVL72。
一個像這樣的“計算單元”機櫃,FP8精度的訓練算力就高達720PFlops,直逼H100時代一個DGX SuperPod超級計算機集羣(1000 PFlops)。

與相同數量的72個H100相比,GB200 NVL72對於大模型推理性能提升高達30倍,成本和能耗降低高達25倍。
把GB200 NVL72當做單個GPU使用,具有1.4EFlops的AI推理算力和30TB高速內存。

再用Quantum InfiniBand交換機連接,配合散熱系統組成新一代DGX SuperPod集羣。
DGX GB200 SuperPod採用新型高效液冷機架規模架構,標準配置可在FP4精度下提供11.5 Exaflops算力和240TB高速內存。
此外還支持增加額外的機架擴展性能。

最終成爲包含32000 GPU的分佈式超算集羣。
老黃直言,“英偉達DGX AI超級計算機,就是AI工業革命的工廠”。
將提供無與倫比的規模、可靠性,具有智能管理和全棧彈性,以確保不斷的使用。

在演講中,老黃還特別提到2016年贈送OpenAI的DGX-1,那也是史上第一次8塊GPU連在一起組成一個超級計算機,當時只有0.17 PFlops。

從此之後便開啓了訓練最大模型所需算力每6個月翻一倍的增長之路。
GPU新核彈GB200
過去,在90天內訓練一個1.8萬億參數的MoE架構GPT模型,需要8000個Hopper架構GPU,15兆瓦功率。

如今,同樣給90天時間,在Blackwell架構下只需要2000個GPU,以及1/4的能源消耗。

在標準的1750億參數GPT-3基準測試中,GB200的性能是H100的7倍,提供的訓練算力是H100的4倍。

Blackwell架構除了芯片本身外,還包含多項重大革新:
第二代Transformer引擎
動態爲神經網絡中的每個神經元啓用FP6和FP4精度支持。

第五代NVLink高速互聯
爲每個GPU 提供了1.8TB/s雙向吞吐量,確保多達576個GPU之間的無縫高速通信。

Ras Engine(可靠性、可用性和可維護性引擎)
基於AI的預防性維護來運行診斷和預測可靠性問題。
Secure AI
先進的加密計算功能,在不影響性能的情況下保護AI模型和客戶數據,對於醫療保健和金融服務等隱私敏感行業至關重要。
專用解壓縮引擎
支持最新格式,加速數據庫查詢,以提供數據分析和數據科學的最高性能。

在這些技術加持下,一個GB200 NVL72就最高支持27萬億參數的模型。
假如初代GPT-4真是1.8萬億參數,一臺GB200 NVL72就能跑15個GPT-4。

英偉達要做世界AI的入口
老黃官宣ai.nvidia.com頁面,要做世界AI的入口。
任何人都可以通過易於使用的用戶界面體驗各種AI模型和應用。
同時,企業使用這些服務在自己的平臺上創建和部署自定義應用,同時保留對其知識產權的完全所有權和控制權。
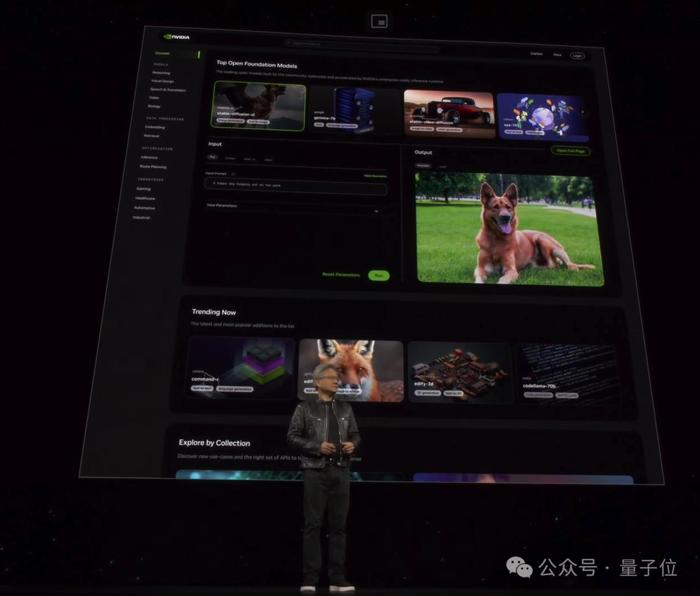
這上面的應用都由英偉達全新推出的AI推理微服務NIM支持,可對來自英偉達及合作伙伴的數十個AI模型進行優化推理。

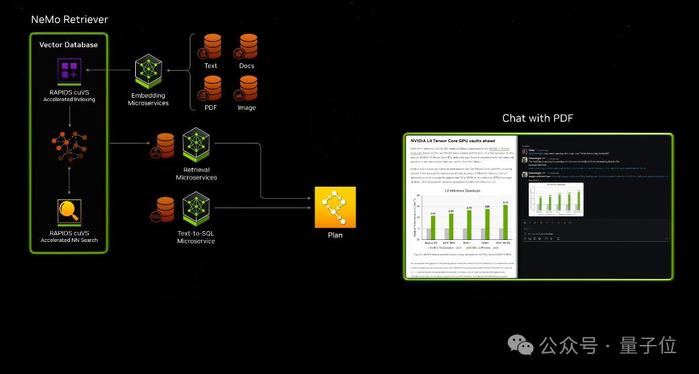
此外,英偉達自己的開發套件、軟件庫和工具包都可以作爲NVIDIA CUDA-X™微服務訪問,用於檢索增強生成 (RAG)、護欄、數據處理、HPC 等。
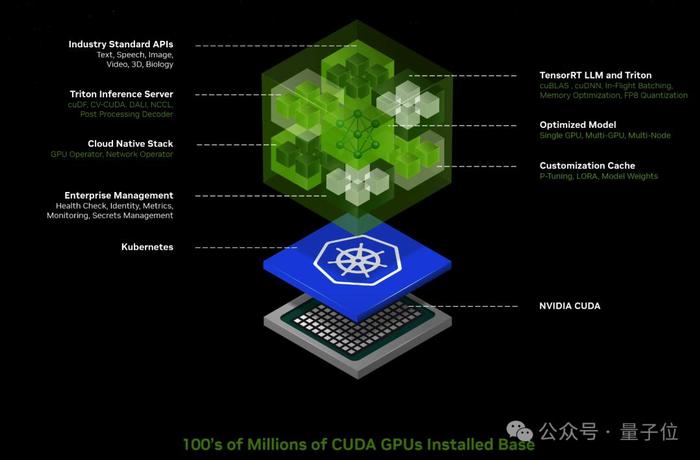
比如通過這些微服務,可以輕鬆構建基於大模型和向量數據庫的ChatPDF產品,甚至智能體Agent應用。
NIM微服務定價非常直觀,“一個GPU一小時一美元”,或年付打五折,一個GPU一年4500美元。
從此,英偉達NIM和CUDA做爲中間樞紐,連接了百萬開發者與上億GPU芯片。
什麼概念?
老黃曬出AI界“最強朋友圈”,包括亞馬遜、迪士尼、三星等大型企業,都已成爲英偉達合作伙伴。

最後總結一下,與往年相比英偉達2024年戰略更聚焦AI,而且產品更有針對性。
比如第五代NVLink還特意爲MoE架構大模型優化通訊瓶頸。
新的芯片和軟件服務,都在不斷的強調推理算力,要進一步打開AI應用部署市場。
當然作爲算力之王,AI並不是英偉達的全部。
這次大會上,還特別宣佈了與蘋果在Vision Pro方面的合作,讓開發者在工業元宇宙裏搞空間計算。

此前推出的新光刻技術cuLitho軟件庫也有了新進展,被臺積電和新思科技採用,把觸手伸向更上游的芯片製造商。

當然也少不了生物醫療、工業元宇宙、機器人汽車的新成果。


以及佈局下一輪計算變革的前沿領域,英偉達推出雲量子計算機模擬微服務,讓全球科學家都能充分利用量子計算的力量,將自己的想法變成現。

One More Thing
去年GTC大會上,老黃與OpenAI首席科學家Ilya Sutskever的爐邊對談,仍爲人津津樂道。
當時世界還沒完全從ChatGPT的震撼中清醒過來,OpenAI是整個行業絕對的主角。
如今Ilya不知蹤影,OpenAI的市場統治力也開始鬆動。在這個節骨眼上,有資格與老黃對談的人換成了8位——
Transformer八子,開山論文《Attention is all you need》的八位作者。
他們已經悉數離開谷歌,其中一位加入OpenAI,另外7位投身AI創業,有模型層也有應用層,有toB也有toC。
這八位傳奇人物既象徵着大模型技術真正的起源,又代表着現在百花齊放的AI產業圖景。在這樣的格局中,OpenAI不過是其中一位玩家。
而就在兩天後,老黃將把他們聚齊,在自己的主場。

要論在整個AI界的影響力、號召力,在這一刻,無論是“鋼鐵俠”馬斯克還是“奧特曼”Sam Altman,恐怕都比不過眼前這位“皮衣客”黃仁勳。
……
最後,再來欣賞一段英偉達爲Blackwell架構製作的精彩動畫短片。
直播回放:
https://www.youtube.com/watch?v=Y2F8yisiS6E
— 完 —