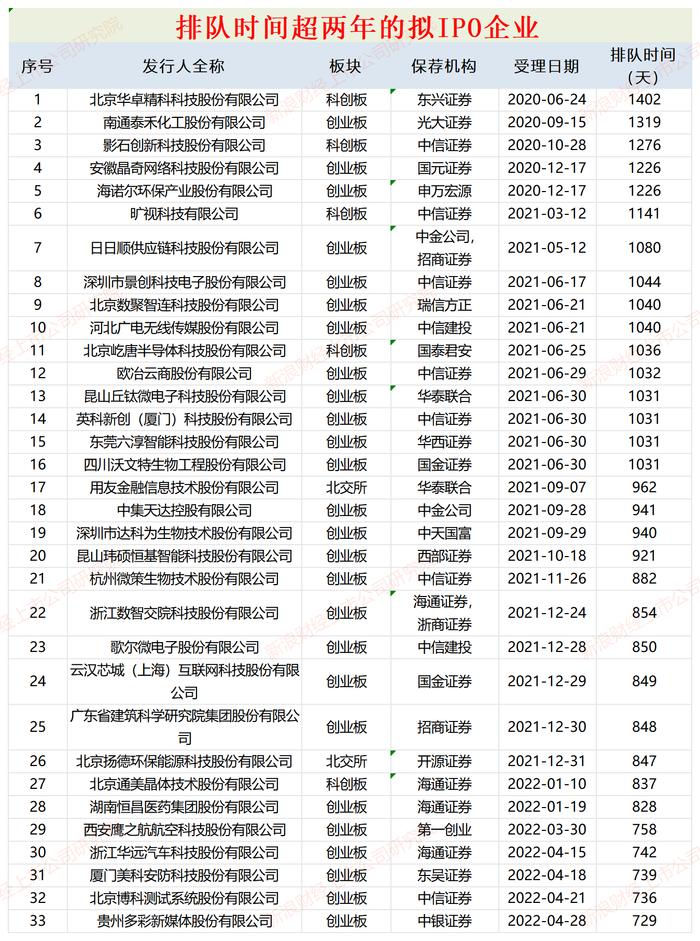
免費、SOTA、中文,微軟卷出了新高度
出品 | 虎嗅科技組
作者 | 杜鈺君
碾壓谷歌的Gemini Pro和阿里的Qwen-VL-Plus,與GPT-4V正面硬剛,這個有着SOTA級別性能的多模態大模型真正做到了“人無我有,人有我優”。
繼2023年4月的初級版本、2023年10月的LLaVA-1.5之後,2024年1月31日,微軟研究院又聯合威斯康星大學麥迪遜分校和哥倫比亞大學的研究者共同發佈了多模態大模型LLaVa(Large Language and Vision Assistant)的1.6版本。與GPT-4V只提供API接口的閉源經營理念不同,LLaVA1.6的代碼、模型與訓練數據全開源,且在標準評測數據集上跑出了較爲亮眼的成績。
一、LLaVA1.6:捲上加捲
LLaVA是一種端到端訓練的大型多模態模型,又被稱爲“大型語言和視覺助手”。LLaVa-1.6是微軟LLaVa系列的第三個迭代版本。升級後的LLaVa-1.6可謂buff疊滿:SOTA級別的性能,低訓練花銷,多模態的內容生成能力和再一次將開源大模型捲上了新高度。
根據LLaVa-1.6官網的標準評測數據集,該模型的表現超越了Qwen-VL-Plus、CogVLM和Yi-VL等一衆模型,在大部分數據集上的表現都優於Gemini Pro,在Math-Vista、MMB-ENG等部分數據集上的表現甚至勝於GPT-4V,成爲了開源模型中的“性能王者“。

圖片來源:LLaVA-1.6官網的標準評測數據
在不拘泥於單一模態的內容生成,具有Text-to-Text和Image-to-Text兩種模式的同時,LLaVa-1.6的過人之處還在於更低的訓練數據成本。LLaVA-1.6能用32個GPU在一天之內完成訓練,僅需1.3M條訓練數據,其計算和訓練數據比其他模型小100到1000倍。
除了通過對話式AI生成文本外,LLaVA-1.6還可以識別圖片信息並轉化成文字答案。升級後的LLaVa-1.6對輸入圖像的分辨率提升到原來的4倍以上,使得模型能夠抓住圖片的更多細節。目前支持的圖像分辨率有672x672、336x1344以及1344x336三種。
LLaVA模型架構基於大量的圖像-文本配對的數據集,將預訓練的CLIP視覺編碼器與大型語言模型(Vicuna)通過映射矩陣相連接,來實現視覺和語言特徵的匹配。根據該模型的研發團隊成員Haotian Liu在X平臺的介紹,此增強版本建立在其前身的簡約設計和數據效率基礎上,並通過改進視覺指令數據集和SGLang,提升了“推理、OCR等方面的性能”,意味着人類向AGI(通用人工智能)探索的道路上又邁進了一步。

LLaVA-1.6的研發團隊成員Haotian Liu在X平臺發文原文
二、更適合中國人體質的GPT-4V
在奮力追平GPT-4V的同時,LLaVa-1.6也展現出強大的零樣本中文能力。
LLaVa-1.6不需要額外訓練便具備傑出的中文理解和運用能力,其在中文多模態場景下表現優異,使得用戶不必學習複雜的“prompt”便可以輕鬆上手,這對於執行“免費(限制文本長度、使用次數等)+付費會員”制的文心一言們而言無疑提出了新的挑戰。
筆者在對LLaVa-1.6模型的demo進行嘗試時發現,LLaVa-1.6對古詩詞等具有中文語言特色的文本內容理解也較爲到位,且能給出中上水平的答案。因而對於有圖生文或文生文需求的用戶而言,LLaVa-1.6模型不失爲更適合中國人體質的GPT-4V。

圖片來源:筆者在文心一格平臺的使用截圖
更強的視覺對話能力使得LLaVa-1.6的智能服務可以覆蓋更多元的場景、具有更強的常識和邏輯推理能力。

圖片來源:用戶在X平臺對LLaVA-1.6的試用截圖
在上圖的應用場景中,用戶發給LLaVA-1.6一張機票,詢問與之相關的接機和日程安排。LLaVA-1.6不僅準確的估計了駕駛時間,還考慮到了可能堵車的情況,頗具一個“智能管家”的自我修養。

圖片來源:用戶在X平臺對LLaVA-1.6的試用截圖
爲了促進多模態大模型社區的發展,開發者們開源了LLaVa-1.6的全部代碼、訓練數據和模型。這無疑有益於人工智能開發的透明度和協作。在較小訓練樣本和開源的前提下,如果可以基於本地數據訓練專業模型,推動解決當前大模型基於雲的產品的責任和隱私問題。
不難發現,輕量化的訓練數據是LLaVa-1.6與其他多模態大模型不同的關鍵一點。一直以來,成本的高企便是橫亙在大模型訓練面前的一大難題。隨着大模型賽道越來越卷,研發者們開始將關注點從性能轉向成本,在關注大規模參數量的同時着力降低模型的運算和推理成本,實現模型壓縮化和計算高效化。
責任編輯:張恆星 SF142