GPT-4變笨!回答新問題性能太差,想保持水準只能不斷訓練新模型
文章來源:新智元

圖片來源:由無界 AI生成
昨天,一篇系統性地研究了GPT-4爲什麼會‘降智’的論文,引發了AI圈的廣泛討論。
隨着大家對GPT-4使用得越來越頻繁,用戶每過一段時間都會集中反應,GPT-4好像又變笨了。

最近的情況是,如果用戶不小心和GPT-4說現在是12月份,GPT-4的輸出的內容就會明顯變少。
有一位用戶專門做了一個測試,分別告訴GPT-4現在是5月份和12月份,然後對比輸出結果,發現12月份的結果比5月份差了不少。
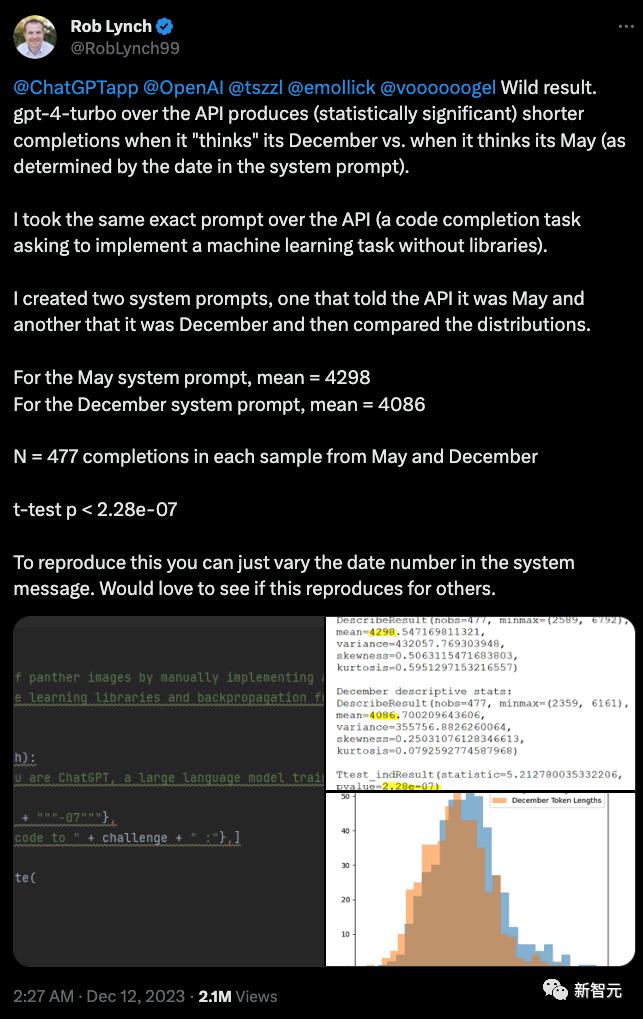
大家討論都覺得是說GPT-4會給自己放寒假,看到12月份就不想幹活了。
但是如果放在這篇論文中來看,作者認爲,最主要的原因是大模型有一個現在看來幾乎是無解的缺陷——缺乏持續學習和進化能力。

論文地址:https://arxiv.org/abs/2312.16337
我們發現在LLM在訓練數據創建日期之前的數據集上的表現,要明顯好於在訓練日期之後發佈的數據集的表現。
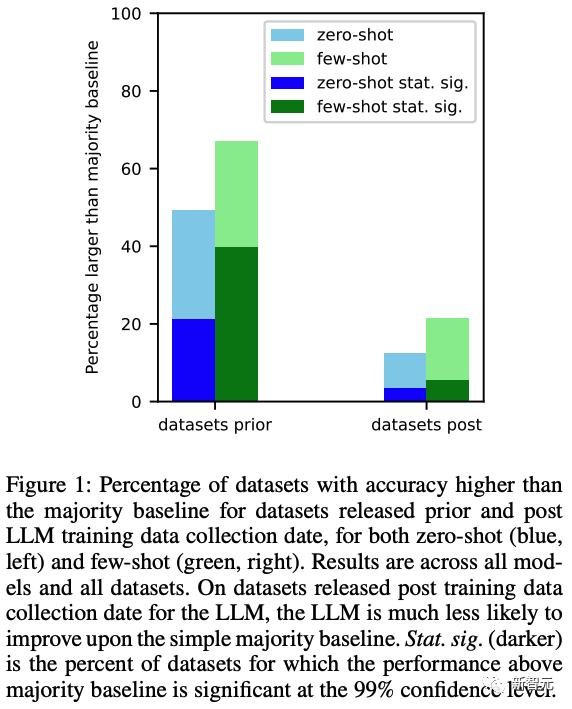
不論是零樣本還是多樣本的測試中,LLM都會呈現出這種情況。
論文還指出,LLM在他們以前真正‘見過’的任務上表現良好,而在新任務上表現不佳,根本原因還是因爲只是記住了答案,而沒有辦法有效地獲得新知識和理解。
而造成這種表現差別如此巨大的原因,就在於‘任務污染’。

在上表中,作者發現可以從GPT-3模型中都能提取任務示例,並且從davinci到GPT-3.5-turbo的每個新版本中,提取的訓練示例數量都在增加,與GPT-3系列模型在這些任務上的零樣本性能提高密切相關。
說白了,之所以模型在截止時間之前的數據集測試表現良好,是因爲訓練數據中已經包含了數據集中的問題。
這充分說明了GPT-3系列各個版本在這些任務上的性能增強是由任務污染導致的。
對於那些不存在任務污染證據的分類任務,大型語言模型很少能在零樣本和少樣本設置下顯著優於簡單多數基準。
在上表中,研究人員也列出對於51個後訓練數據收集且無提取任務示例的模型/數據集組合中,只有1個組合的模型能在零樣本或少樣本設置下顯著優於多數基準。
這說明一旦沒有任務污染的可能性,LLM的零樣本和少樣本表現其實並不突出。
網友們看了之後悲觀地表示:目前很難構建能夠持續適應且不會對已編碼的過去知識和新知識造成災難性干擾的機器學習模型。

ChatGPT是過去互聯網的快照 - 隨着互聯網的變化,ChatGPT 在有用任務的知識和性能方面都變得過時了。
OpenAI和大模型公司都必須面對這樣一個事實——他們必須不斷重新訓練新模型。
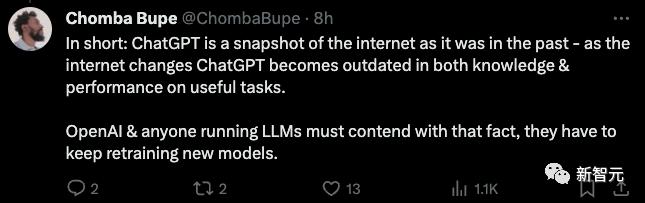
也許,這就某種程度上爲什麼沒過一段時間,人們就會發現ChatGPT又變笨了,也許只是因爲你不斷地在用新問題考它,它的真實水品慢慢地被暴露出來了。
測試模型
研究人員針對12個模型進行了測試:
5個OpenAI發佈的GPT模型,7個開源的LLM。
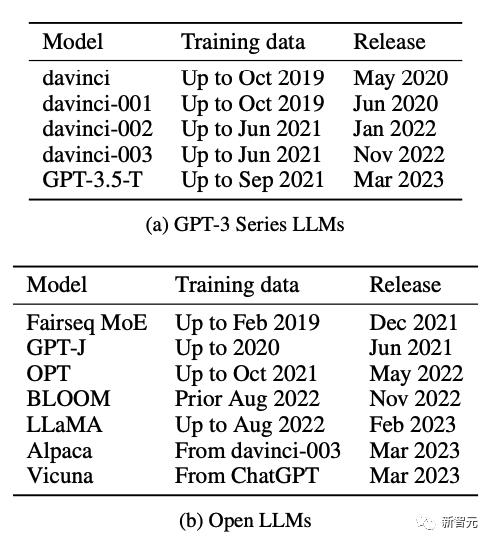
針對這些模型,他們選取了兩組剛好卡在模型訓練時間前後的數據集進行了測試。
測試方法
時序分析
然後研究人員分別測試了不同模型在相同兩組數據集上的表現。從結果可以明顯看出,在模型數據訓練截止日期之後發佈的數據集,零樣本和多樣本性能明顯要差了很多。
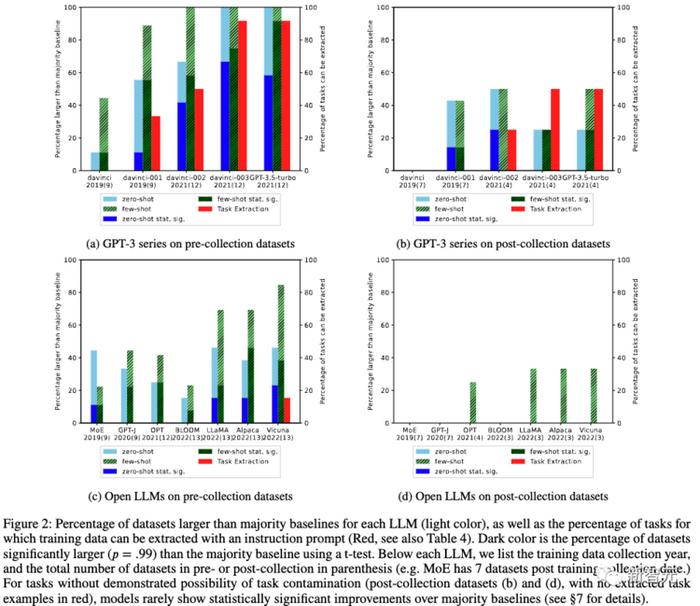
對於12個模型和16個數據集,研究人員進行了192個模型/數據集組合。
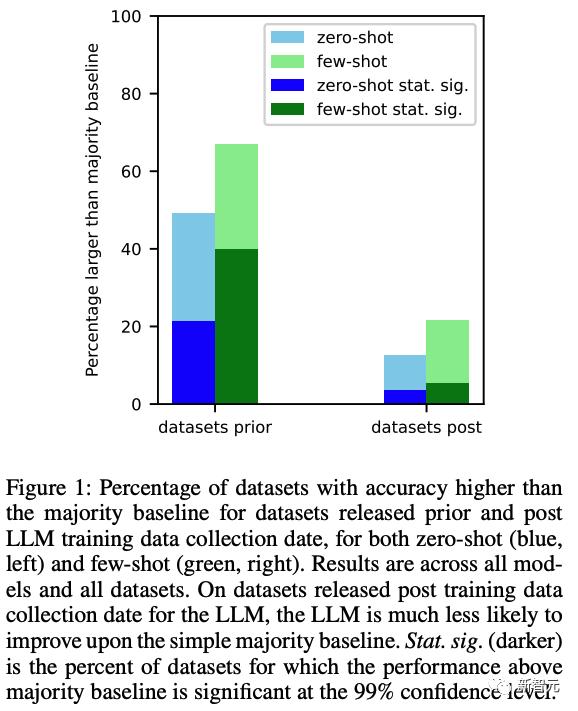
在這些組合中,136 個數據集在 LLM 培訓數據收集日期之前發佈(收集前),56 個數據集在之後發佈(收集後)。對於這兩個集合,我們計算模型擊敗大多數基線(零樣本和少樣本)的模型/數據集組合的百分比。
結果如下圖 1 所示。我們發現,對於在創建 LLM 之前發佈的數據集,LLM 更有可能在零和少數樣本設置上擊敗多數基線。
針對單個的LLM,進一步發現:
針對每個LLM單獨進行測試。結果如上圖2所示。這樣的趨勢在具有全範圍日期的模型中保持不變,進一步表明數據集的絕對日期不是主要因素,而是日期數據集相對於法學碩士訓練數據收集日期的變化是更重要的因素。
任務示例提取分析
如果LLM能夠生成與測試數據中的示例完全匹配的示例,則證明LLM在訓練期間已經看到了該任務的測試集。
研究人員採用類似的方法來測試任務污染。他們不嘗試生成測試數據,而是提示模型生成訓練示例,因爲對於零次或少次評估,模型不應在任何任務示例上進行訓練。
如果LLM可以根據提示生成訓練示例,這就是任務污染的證據。
下表4顯示了所有模型中所有任務的任務示例提取結果。

進一步研究人員還發現,對於沒有被證明存在任務污染可能性的任務,LLM很少表現出比大多數基線具有統計顯着性的改進。
在上表4中,對於收集後且沒有提取任務示例的 51 個模型/數據集組合,51 個模型/數據集組合中只有 1 個(即 2%)在零樣本或少樣本設置的情況下表現出相對於大多數基線的統計顯着改進。
成員推理分析
爲了進一步檢查訓練數據污染的影響,研究人員應用了成員推理攻擊來檢查模型生成的內容是否與數據集中的示例完全匹配。
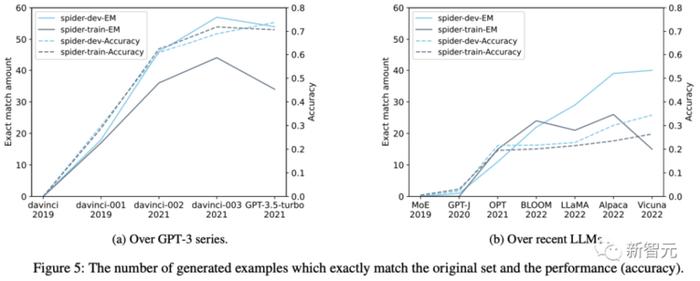
上圖5a和圖5b分別顯示了GPT-3系列版本和最新開源 LLM 的採樣訓練集和完整開發集生成的示例有多少是完全相同的。
因爲數據庫模式(atabase schemas )不在零樣本提示中,因此如果模型可以生成與訓練或開發數據中完全相同的表名或字段名,則一定存在污染。
如圖5所示,精確匹配生成的示例數量隨着時間的推移而增加,這表明Spider上的任務污染程度正在增加。
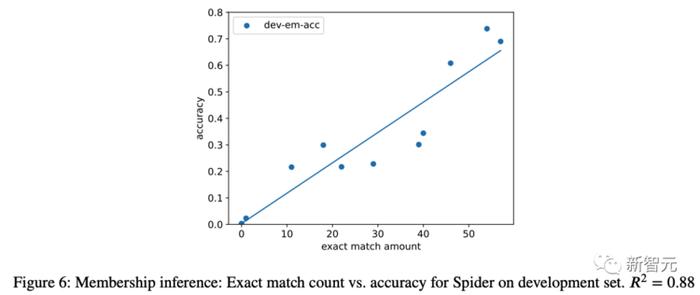
他們還在提示中添加模式後計算執行準確性,並將其與完全匹配的代數進行繪製(圖 6)。我們發現完全匹配的生成示例數量與執行準確性之間存在很強的正相關性(? = 0.88),這強烈表明污染的增加與性能的提高有關。
參考資料:
https://arxiv.org/abs/2312.16337








