大模型幻覺問題無解?理論證明校準的LM必然會出現幻覺
文章轉載來源:機器之心
文章來源:機器之心
理論證明!校準的語言模型必然出現幻覺。

圖片來源:由無界 AI生成
大型語言模型(LLM)雖然在諸多下游任務上展現出卓越的能力,但其實際應用還存在一些問題。其中,LLM 的「幻覺(hallucination)」問題是一個重要缺陷。
幻覺是指由人工智能算法生成看似合理但卻虛假或有誤導性的響應。自 LLM 爆火以來,研究人員一直在努力分析和緩解幻覺問題,該問題讓 LLM 很難廣泛應用。
現在,一項新研究得出結論:「經過校準的語言模型必然會出現幻覺。」研究論文是微軟研究院高級研究員 Adam Tauman Kalai 和佐治亞理工學院教授 Santosh S. Vempala 近日發表的《Calibrated Language Models Must Hallucinate》。該論文表明預訓練語言模型對特定類型的事實產生幻覺存在一個固有的統計學原因,而與 Transformer 架構或數據質量無關。

論文地址:https://arxiv.org/abs/2311.14648
一個語言模型其實就是在 token 序列(如詞或其它字符序列)上的一個概率分佈 D。每個分佈 D 都可以等效地表示成其在整個序列上的對數概率或後續 token 基於之前 token 的條件對數概率
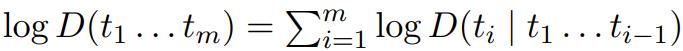
這種數學等價性意味着任何語言模型都要麼可用於生成文本,要麼就能基於之前的 token 根據自然出現的文本來預測下一個 token。
舉個例子,假設有以下句子:
Alexa Wilkins had a tuna sandwich at Salumeria for lunch last Tuesday because the reviews said that it was divine.
對於這樣的句子,我們可以使用預測式語言模型等技術來提供建議,從而減少輸入時點擊手機的次數。我們可能希望詞 tuna 之後有 sandwich 這個選項,另外還有其它可能的詞,比如 salad 和 roll。另一方面,如果使用一個生成式語言模型來隨機生成,那麼這類句子大部分都會是錯誤的。
這篇論文表明,具有優良預測文本性能的語言模型必定會產生幻覺,即便在理想條件下也是如此。要注意的是,對於當今常見的生成式語言模型,預測文本性能的優化工作位於「預訓練」的第一個階段。此外,它還能給出幻覺率的下限;幻覺率可反映不同類型的事實產生幻覺的速率。
以上參考和示例和共同之處是它們是任意的,也就是說 5W(= Who-Ate-What-When-Where-Why 仿真事實)中的每一項都無法通過規則來系統性地確定 —— 對於大多數不存在於訓練數據中的此類事實,人們無法確定其真實性。這與可系統性地確定真實性的事實不同。即使在具有幾個理想屬性的簡化環境中,我們也能量化語言模型出現幻覺的可能性。
因爲這篇論文要給出統計下限,因此更傾向於簡單而非普遍性,因爲這裏的下限的目標是確定語言模型幻覺的根本原因。類似於分類任務(尋找的是在無噪聲環境中分類難度的下限),這裏需要找到在最簡單的設置中也成立的幻覺下限,而最簡單的設置是指訓練數據是獨立同分布且沒有事實性錯誤。
對生成模型進行校準
對一個概率式預測器來說,校準(Calibration)是很自然的需求,因爲這意味着其概率可被解釋成對其自身預測結果的準確置信度。
Philip Dawid 在 1982 年引入了校準這一概念,他當時還給出了一個很多人都很熟悉的例子:當天氣預報說未來幾天降雨概率爲 30% 時,其實是指大約 30% 的時間會下雨。
已經有不少研究者探究過語言模型的校準指標。圖 1 給出了 GPT-4 在一個多選題測驗上的多類別校準示例。
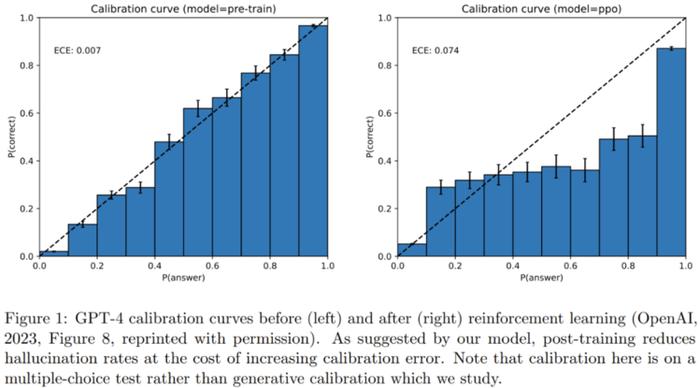
爲了減少幻覺問題,人們常在訓練後進行對齊操作,但研究發現對齊也會降低校準度。校準是有意義的(因爲校準後的預測器的概率可以解釋爲準確置信度),而且在統計學上也是可實現的。相較之下,完美準確的預測器也可以校準,但可能無法學習。
然而,校準只是預測器的最低要求,因爲並非所有校準過的模型都是有用的預測器:始終輸出年平均降雨概率的預測器很簡單就能校準。
研究者在這篇文章中爲生成模型的校準提供了一種自然的泛化。他們的校準概念不同於之前的在 token 層面的語言模型校準。分析原始 token 概率的問題是用自然語言描述任何事實的方式都有很多,因此校準過的 token 概率並不是很有意義。
這裏舉個例子說明一下。假設有一個三元組語言模型,其僅基於前兩個 token 來預測下一 token 的概率。三元組模型可以很自然地在 token 層面完成校準,而幻覺並非三元組模型的一個主要問題。這是因爲他們基本上都是生成毫無意義的亂語。相對而言,語義層面的校準考慮的則是基於文本中所含信息(事實或幻覺)的概率分佈。
這裏如何認定一個語言模型是否已經校準呢?對於任意概率 z ∈ [0, 1],在語言模型以大約 z 的概率生成的信息中,這樣的信息平均出現在自然表達的語言(理想情況下是訓練數據所在的分佈)中的大約 z 份額中。
語言模型出現幻覺的原因
幻覺讓語言模型用戶和研究者都深感困惑。研究者調查了許多關於語言模型幻覺原因的假設,從不準確或過時的訓練數據到訓練中的下一 token 對數似然目標。
幻覺的原因還有對抗性或分佈外的 prompt:爲語言模型提供的使其補全已有上下文的文本前綴。而在這項新研究中,研究者發現即使是使用完美的訓練數據,並且不使用 prompt,經過校準的語言模型也會出現幻覺。
簡化設置
在研究者的簡化設置中,有一個基於文檔(即文本字符串)x ∈ X 的靜態語言分佈 D_L ∈ ∆(X) 和一個學習算法 A。
學習算法 A 可以根據從 D_L 獨立採樣的 n 個文檔組成的訓練數據 x_train ∈ X^n,輸出一個語言模型,即一個分佈 D_LM = A (x_train) ∈ ∆(X)。
爲了簡單,研究者在這裏假設訓練數據中僅有事實,並且每個文檔最多一個事實,也就是沒有訓練幻覺。這裏的事實是任意事實,也就是其真實性通常無法通過訓練集本身確定;而不是系統性事實(可通過學習定義正確性的基本規則而基於訓練集預測得出),比如 572 < 120523。沒有統計學上的理由表明語言模型會在系統性事實上產生幻覺。
此外,在系統性事實上的錯誤可能根本不會被視爲幻覺 —— 它們通常被歸類爲推理或算術錯誤。
這裏假設每個文檔 x ∈ X 至多包含一個仿真陳述(factoid) f (x) ∈ Y ,其中仿真陳述是指要麼爲真(事實)要麼爲假(幻覺)的任意信息,並且其真實性很難根據訓練數據從統計上確定。
研究者還採用了另一種簡化方法:考慮無條件的生成,即採樣語言模型生成文本時不使用任何 prompt(相當於無字符串前綴)。
當然,相較於簡化設置,更現實的情況更可能出現幻覺現象,即 prompt 中包含來自不同於訓練數據的分佈的上下文。
結果
假設在包含大量任意仿真事實的一個未知分佈上採樣了 n 個獨立同分布樣本,比如 5W 樣本和索引。缺失質量(missing mass)(在這裏即爲缺失的事實 p (U))是來自該事實分佈 p 的未來樣本中未在 n 個訓練樣本中觀察到的部分,其中 U 是在訓練數據中未觀察到的事實的子集。
缺失質量的 Good-Turing 估計是指在訓練數據中僅出現一次的樣本(在這裏即爲事實)的比例。研究者將其稱之爲 MonoFacts estimator,即單事實估計器:
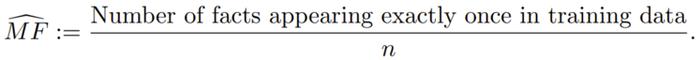
研究表明,對於任意分佈 p,這個 Good-Turing 估計器有很高的概率位於缺失質量的
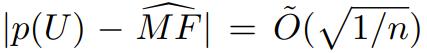
範圍內。
如果訓練中不包含的任意仿真事實的正確性無法被確定,則缺失事實率可以提供一個幻覺率的下限。這反過來就能提供一個接近
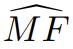
的下限。特別是,在仿真事實分佈的「正則性」假設下,最簡單的界限(論文中的推論 1)意味着:對於任何算法,在訓練集上有 ≥ 99% 的概率會有:
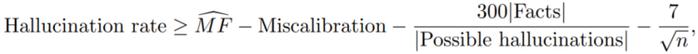
其中幻覺率(Hallucination rate)是指語言模型產生幻覺的速率,下一項是缺失事實的「單事實」估計器。再後一項是「誤校準率」,它量化了分佈與校準的接近程度。下一項則涉及任意事實與錯誤的類似信息的數量之比,對許多類型的信息來說,該比值非常小。最後一項很小,因爲當今語言模型的訓練集規模 n 都很大。
「正則性(regularity)」假設的意思是:平均而言,所有未觀察過的仿真事實爲真的概率相等。
更一般而言,該界限成立的概率 ≥ 1 − δ,其中常數 60 可以用與 δ 成反比且與仿真事實分佈上的正則項成正比的項替換。這個正則項衡量的是最可能的仿真事實(在訓練數據中未觀察到)與平均未觀察到的仿真事實概率的比。對於對稱分佈和其它類型的簡單分佈,該常數爲 1。
爲了考慮有界的正則性,研究者放寬了它,這樣就能允許存在一定的負相關性(比如一個人不能同一天在 1000 個不同地方喫 1000 頓午餐),並允許某些仿真事實的條件概率爲 0,但它不允許未觀察過的仿真事實具有非常大的概率。
相關的證明過程請參看原論文。
解釋
對於上面的下限,研究者給出瞭如下解釋。
第一,應當確定大量仿真事實:任意的、合理的、正則的仿真事實。它們可能是有關 5W 的文章和合理的科研文章引用。直觀上講,不正確的仿真事實(幻覺)比事實多得多。然後再考慮這些仿真事實中有多大比例可能在訓練數據中剛好出現一次。對於 5W 的情況,可以想象有一半的文章剛好出現一次。這表明,經過校準的仿真事實模型在 5W 仿真事實上的生成結果中大約有一半會有幻覺問題。
另一方面,可以想象文章的數量遠遠少於 n,因爲出版的目標是廣告宣傳,每一個引用都可能在訓練數據中多次出現(即概率遠大於 1/n),可能只有非常近期的除外(比如在其它引用出現之前)。這表明文章的缺失質量很低,並且在引用標題上產生幻覺方面沒有內在的統計必然性。
還有其它一些原因可能會導致出現這種幻覺,比如模型能力有限(即便語言模型的參數數量遠大於文章數量,這些參數也必然會編碼文章標題之外的許多其它類型的信息)。這也證明:爲了緩解幻覺問題,一種合理做法是在生成時諮詢事實數據庫,即便該事實數據庫完全基於訓練數據。
儘管事實性和預測準確度之間存在這種緊張關係,但這兩種類型的語言模型的訓練或「預訓練」目標通常都是最大化在語料庫上的可能性,也就相當於最小化「KL 散度」,這是語言模型和其訓練所用的數據分佈之間的一個強大的統計差異指標。








