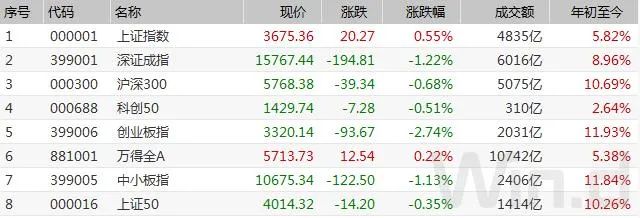
外國人爲什麼說不好中文?原因只有一個……
來源:科學大院
“歪果仁”會被中文逼瘋嗎?不會,但可能被聲調逼瘋。

(圖片來源:梁柏燊,姜欣桐繪製)
有一位在中國做高中班主任的英國老師,平時和學生們相處得很好,但是有一天一羣過度活躍的孩子在自習課上太鬧騰,看自習的老師終於按捺不住,激動地站了起來,拍着講桌:
“我補知搗你們微什麼遮麼吵!”
學生們意識到班主任憤怒了,但還是忍不住笑了起來。班主任也沒轍,見場面已經失控,也捂着嘴,笑了起來……

(圖片來源:梁柏燊,姜欣桐繪製)
事實上,他是一個對漢語瞭如指掌的牛津文學院高材生——在入學報到第一次開班會的時候,他拿着花名冊一個一個地把同學的名字字正腔圓地念了一遍——包括聲調。開學之前他給學生家長打電話,家長們竟然沒有聽出他的“歪果”腔。後來才發現,他在花名冊中給每個人的名字都標好了拼音,寫好了聲調。可是,那天的自習課上,學生們過分吵鬧,還是讓他在很生氣的情況下“原形畢露”了。
不僅是這位來自英國的老師,有很多可以掌握好幾門語言的外國人,還是不能說把漢語說好。若是問他們漢語裏面什麼東西最難學,他會毫不猶豫地告訴你——“tone”(譯:聲調)。

(圖片來源:梁柏燊,姜欣桐繪製)
聲調之難,難於……
漢語博大精深,聲調可以說是漢語的精髓之一了。精髓的另一個意思就是難,就像哥德巴赫猜想是數學界皇冠上的明珠,花掉了數學家們多少年呀,何況是咱家的聲調呢?所以,聲調難學,聲調發不準,真的能怪勤奮好學的“歪果仁”們嗎?
首先,讓我們看看聲調是什麼。我們日常說的言語(speech),聽起來很簡單,用錄音機錄下來畫成一幅圖,也就是一些波形:
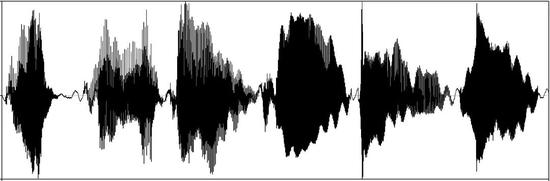
(圖片來源:梁柏燊繪製)
可是這些波形內有乾坤。君請看,下圖這個鼓起來的小包包是一個音節(syllable,這裏是普通話的“媽”)。這個“媽”的前後部分分別代表着/m/和/a/。
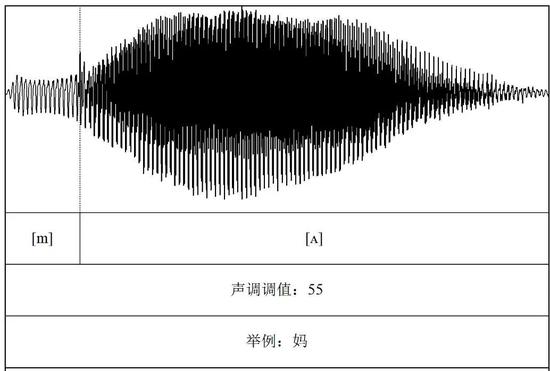
(圖片來源:梁柏燊繪製)
那麼難倒了“歪果仁”的聲調在哪裏呢?爲了看清楚聲調,我們需要對“媽”進行加窗傅里葉變換。
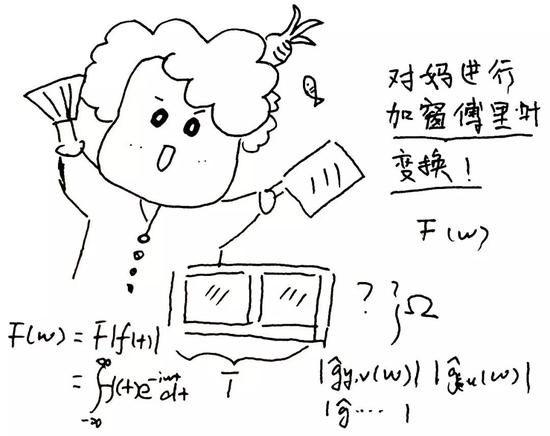
(圖片來源:梁柏燊,姜欣桐繪製)
簡單來說,傅里葉變換將聲音信號分解爲許多不同頻率的(也就是聽起來音高不一樣的)簡諧波——這些波可以疊加成我們聽到的聲音信號。這就好比大合奏,原始的波形就好比合奏本身,而傅里葉變換讓我們看清楚小提琴、大提琴、笛簫等各種組成合奏的樂器。加窗傅里葉變換是指對選取一段時間範圍內的信號進行拓展處理後進行傅里葉變換,就好比選取樂曲中的一段來看樂器們各自的演奏情況。
再說頻率——讓我們看看下圖。“媽”的其中一小段被分解成了很多不同頻率的簡諧波,其中頻率最低的那段波的頻率就稱爲“基頻”(F0),頻率爲基頻整數倍的各段波稱爲“諧波”,而這一小段聲音的音高就是由基頻決定的。
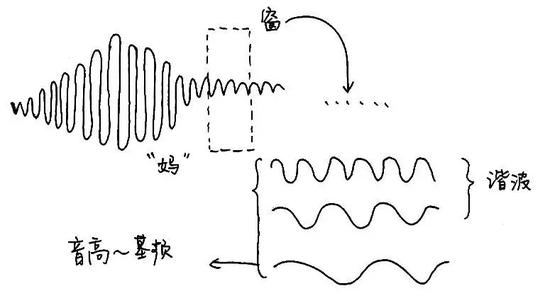
(圖片來源:梁柏燊,姜欣桐繪製)
每個小段能計算出一個基頻數值,這個數值代表這一段的音高。如下圖所示,將每一小段的數值連起來,就形成了代表音高變化的曲線。
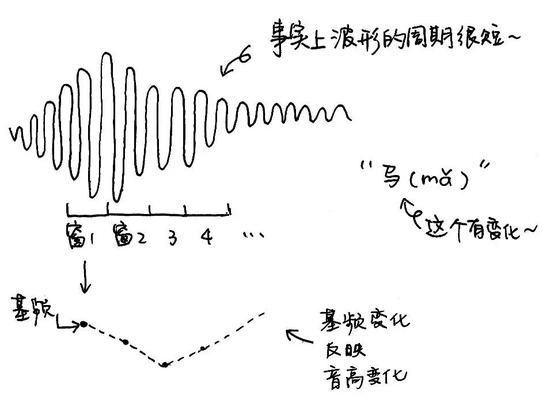
(圖片來源:梁柏燊,姜欣桐繪製)
聲調是什麼呢?對於單個讀的音節,聲調就是音高的變化曲線(音高輪廓)。在物理上,聲調就是基頻F0的起伏。
那麼爲什麼“歪果仁”們那麼難學聲調呢。我們來看看英語和普通話的基頻(F0)是怎麼變化的。
這是英語:
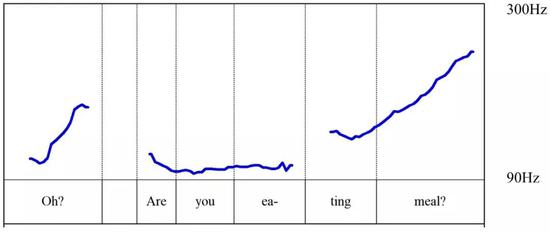
(圖片來源:梁柏燊繪製)
這是普通話:
(圖片來源:梁柏燊繪製)
看到區別了嗎?
作爲一種非聲調語言,英語的一句話中,音高基本上是平順的,如果是疑問語調,纔會一直往上揚。但是普通話就不同了。當單個音節組合成句子的時候,每個音節的音高變化就是聲調和語調的疊加。換言之,普通話有跟英語一樣表示語調的句子長度的音高變化,還有疊加在句子“大波浪”上面的“小波浪”——聲調!
(圖片來源:梁柏燊,姜欣桐繪製)
就好比開車,說英語就像在平整的路上開車,雖然有起伏,但都是平緩上坡下坡。普通話就不一樣啦,你不僅要上下坡,你還要面對突如其來的密密麻麻的音節長度的震顫。就好像開慣平路的司機突然遇到坑坑窪窪的山路,需要你手腳並用輪番換擋踩剎車油門一樣,嗓(腦)子沒有自小練就十八般武藝,又怎可能迅速應付過來呢?
然而,聲調的難,又何在於難學呢?
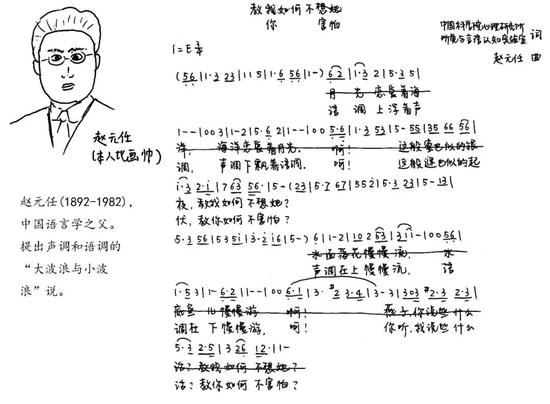
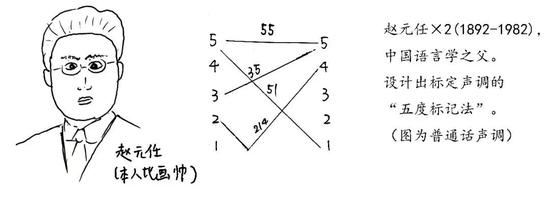
由於聲調這種坑坑窪窪的個性具有如此獨特的語言學地位,研究者們對其進行了大量的研究。比如,中國語言之父趙元任先生創立一種標記聲調的研究方法:
(圖片來源:梁柏燊,姜欣桐繪製)
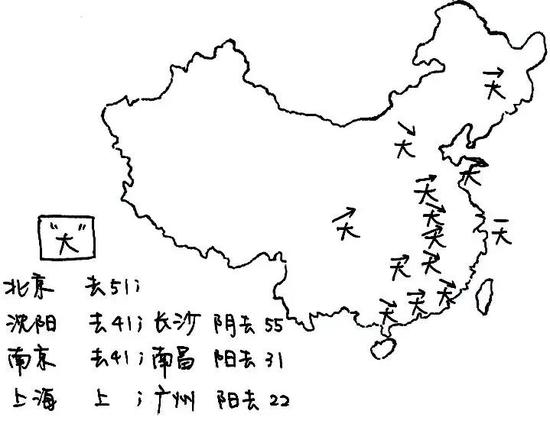
再比如,探究偉大祖國各種方言的聲調:
(圖片來源:梁柏燊,姜欣桐繪製)
又比如,創造一系列(人間不存在的)介於一聲和二聲之間的“聲調”,讓人聽後判斷這到底是一聲還是二聲(範疇感知):
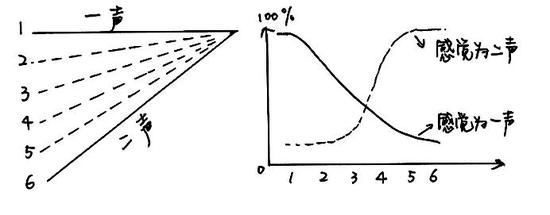
圖解:我們日常說話的一聲和二聲一般是有一個固定的基頻升降範圍的——比如一聲就是幾乎沒有變化,二聲是比如介於100~200Hz之間,那麼如果人爲地創造一個變化幅值低於正常的二聲變化幅值的聲調(如圖中的2~5),就會造成聲調判斷困難。(圖片來源:梁柏燊,姜欣桐繪製)
又或者,是一些不怕卡機(或者是雖然老卡機,但愈卡愈勇)的大腦試圖建立大腦與聲調之間的關係——我們的大腦是怎樣處理聲調的呢?
我們的大腦是怎麼處理聲調的呢?
要搞清楚這個,可是比“歪果仁”學聲調還困難N的N次方倍(N>1)的事情。但是,還是有人衝在了前面,咬了這個螃蟹幾口。
比方說,在二十年前,Gandour等研究者讓說泰語的人、說漢語的人和說英語的人躺進磁共振儀裏(Gandour, Wong, & Hutchins, 1998)。研究者每次給他們聽一對只有聲調可能不一樣的音節(比如/khaa/和/khàa/),他們需要判斷這一對音節的聲調是否一樣。在整個實驗中,他們會聽到許多對像這樣的音節,並且做出判斷。他們希望通過記錄和對比三種母語背景的人判斷聲調激活的腦區的異同,來研究母語背景對大腦處理聲調的方式的影響。
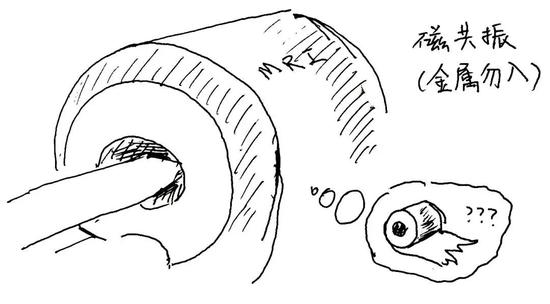
(圖片來源:梁柏燊,姜欣桐繪製)
後來,關於大腦處理語言的腦成像研究越來越多——其中,聲調研究就有不下二十個。
那麼問題來了。
這麼多的聲調研究,發現的結果都是一樣的嗎?
這裏就要提一下科學得以存在和發展的基石之一——結論的可重複性了。就比方說,小明今天觀察到太陽從東方升起,提出了“太陽東昇說”。小紅第二天也觀察到太陽從東邊升起,就重複檢驗了小明的“太陽東昇說”。如果小明的結論一直得到獨立觀察的重複驗證,那麼他發現的就應該是真理。
然而,對於腦研究而言,事情並沒有那麼簡單。

(圖片來源:梁柏燊,姜欣桐繪製)
不同人的大腦是不一樣的:有的圓,有的扁;不同型號的機器掃出來的結果也不盡相同。因此,要求後續研究都嚴格地將結果重複出來是不實際的。但是,如果人躺在掃描儀裏做的任務是相似的,那麼他們的腦激活也應該是相似的。
爲了尋找大腦加工聲調過程中最可能的激活點(在不同研究中都有激活的點),我們對已有的掃描加工聲調的大腦的研究進行了一項文獻整理工作(學名叫元分析)(Liang & Du, 2018)。在這項工作中,我們還整理了音位(比如英語中的元音和輔音)和韻律(比如疑問的語調)的腦成像研究,並且對比了它們和聲調激活腦區的異同。
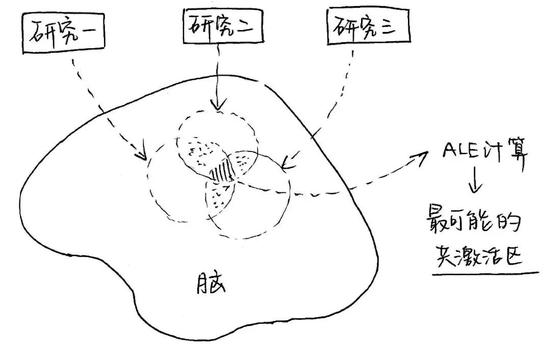
(圖片來源:作者提供)
爲了對比“歪果仁”(不說聲調的人)和說聲調的人,我們將聲調腦激活的結果按人的母語背景分成了兩類。又因爲韻律有長有短,我們按韻律長度分成了兩組韻律加工任務。換言之,我們收集了五組研究:聲調母語者的聲調感知(tonal tone),非聲調母語者的聲調感知(non-tonal tone),音位感知(phoneme),詞長度的韻律感知(word prosody)和句子長度的韻律感知(sentence prosody)。我們對每個組的腦激活結果分別進行元分析。
結果發現,大腦是按照聽起來像什麼(聲學分析)、說起來是什麼(發音模擬)以及有什麼語言功能的方式來加工聲調的。
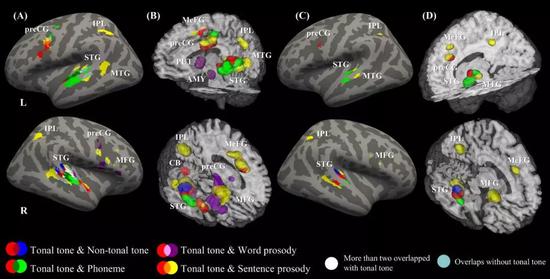
圖解:元分析的激活結果圖:紅色表示聲調母語者的聲調感知,藍色表示非聲調母語者的聲調感知,綠色表示音位感知,紫色和黃色分別表示詞長度和句子長度的韻律感知 (Liang & Du, 2018)。
具體而言,聲調的激活區域在聽皮層(耳朵附近的腦區)中更加偏向右側,只有聲調母語者加工聲調時出現了左側的激活,這說明決定意義的角色使得聲調在聲調母語者腦中有更多的語言功能(因爲語言區域偏向左腦)。在左側聽皮層中,聲調激活區與音位激活區重疊,位於句子長度韻律的前面,這也體現了聲調的語言功能。而在右側聽皮層中,聲調激活區域位於音位的後面和韻律的前面,這更加體現出聲調長度夾在音位和韻律之間這一聲學屬性。
另一個更加神祕的激活區位於負責說話的區域。我們在左側運動皮層發現了音位、聲調和韻律的激活。而且,聲調與韻律(都是用喉部控制)重疊並位於音位(脣舌控制)的下方,符合大腦運動皮層的拓撲分佈(運動皮層的不同小區域負責傳達身體不同區域的運動指令,按區域的比例畫成人形,就是“運動小人”,motor homunculus,如下圖)。發音系統的參與其實是人感知言語的一種獨特方式,聽者會通過重構和預測說話者的發音動作來輔助言語理解(Du et al。, 2014, 2016)。
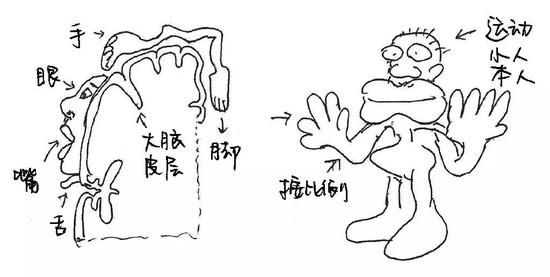
(圖片來源:梁柏燊,姜欣桐繪製)
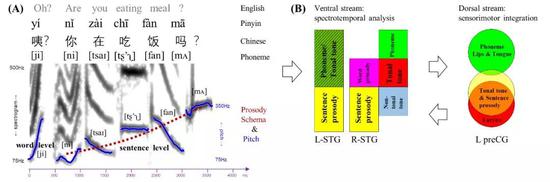
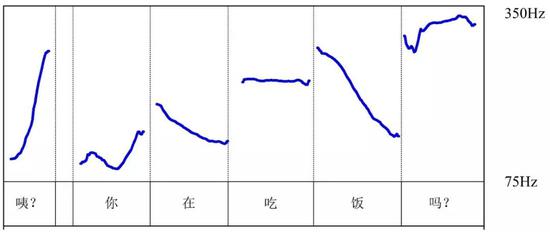
圖解:聲調感知的腦機制模型:(A)普通話“咦?你在喫飯嗎?”的語音頻譜圖(spectrogram)和音高輪廓(pitch contour);(B)聲調感知的腹側通路(ventral stream,在聽皮層,對聲調進行聲音分析和語義的辨認)和背側通路(dorsal stream,在發音運動區域,對聲調進行發音運動模擬)(Liang & Du, 2018)
總而言之,通過這些文獻整理,我們進一步瞭解了大腦處理聲調的方式。然而,研究的路還有很長的一段要走。
比如,如何讓“歪果仁”們學習普通話時不再那麼痛苦呢?這就像是遙遠的夜空中閃爍的北斗星,指示着我們前行的路。
(圖片來源:梁柏燊,姜欣桐繪製)