不只是統計機器!MIT研究人員重磅論文引圍觀:大型語言模型是"世界模型",甚至有獨立的"時間和空間神經元"
來源:每日經濟新聞 記者 蔡鼎 編輯 蘭素英
近年來,大型語言模型(下稱LLMs)的能力不斷提高,引發了各界關於它們是否只是學習了表面的統計規律,還是形成了包含數據生成過程的內在模型(即世界模型)的爭論。近日,來自麻省理工(下稱MIT)的研究人員公佈了他們的研究,就此給出了答案。
MIT研究人員Wes Gurnee和Max Tegmark於10月3日提交在預印本arXiv上的論文稱,他們通過分析三個空間數據集(世界、美國、紐約市的地點)和三個時間數據集(歷史人物、藝術作品、新聞標題)在Llama-2系列模型中的學習表徵,發現了世界模型的證據。
研究人員發現,LLMs學習了空間和時間的線性表徵,並且這些表徵在不同的尺度和實體類型(如城市和地標)之間是統一的。此外,作者還識別出了單個的“空間神經元”和“時間神經元”,它們可靠地編碼了空間和時間座標。論文稱,現代LLMs獲取了關於空間和時間這些基本維度的結構化知識,證明LLMs學習的不僅僅是表面統計規律,而是真正的世界模型。
LLMs中存在“時間和空間神經元”
在空間和時間數據集層面,研究人員在實驗中構建了六個數據集,包含有對應空間或時間座標的地點或事件的名稱,分別涵蓋了不同的空間或時間尺度,包括全球範圍內的地點、美國國內的地點,以及紐約市範圍內的地點;過去3000年內去世的歷史人物;1950年以來發布的歌曲、電影和書籍;以及2010年至2020年發佈的新聞標題。

圖片來源:arXiv網站論文
對於每個數據集,研究人員納入了多種類型的實體,例如城市等人口密集場所和湖泊等自然地標,以研究不同對象類型的統一表徵情況。此外,研究人員還維護並豐富了相關的元數據,以便通過更詳細的分類分析數據。
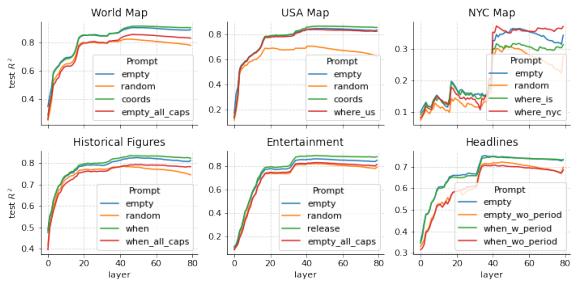
研究人員使用標準的探測技術,即在LLMs的內部激活上擬合一個簡單的模型來預測與輸入數據相關聯的目標標籤。具體來說,給定一個激活數據集A和一個目標Y,包含時間或二維經緯度座標,作者擬合線性迴歸探測器得到一個線性預測器。在未提示過的數據上強大的預測性表明,LLMs中有可被線性解碼出來的空間和時間信息。
作者首先探測了Llama-2-{7B, 13B, 70B}每一層對每個空間和時間數據集的預測性能。結果顯示,在所有數據集上,空間和時間特徵都可以被線性探測器恢復,而且這些表達隨着模型規模增大而變得更準確,並且在達到穩定狀態之前,模型前半層的表達質量會平穩提高。例如,他們發現,Llama-2-70B竟然能夠描繪出真實世界的文字地圖。
總結來說,MIT研究人員的研究顯示:LLMs不僅僅是隨機的模型——Llama-2已經是包含世界的詳細模型,甚至包含獨立的“時間神經元”和“空間神經元”!
論文作者之一、MIT研究大模型優化的博士生Wes Gurnee的論文一經arXiv和推特(現X)發佈,便引發廣泛關注。其推文概述了論文的內容,截至發稿,已經有近300萬次閱讀。
LLMs學習的空間和時間線性表徵在不同實體類型間是統一的
此外,作者還研究了Llama-2的這些空間或時間表徵是否對提示詞敏感,即是否可以通過上下文來引發或抑制這些事實回憶。直覺上,對於任何實體詞,自迴歸模型都有動機產生一個適合應對任何未來可能的上下文或問題的表達。
爲了研究這一點,研究人員創建了新的激活數據集,其中在每個實體詞前加上不同的提示。在所有情況下,作者都包括了一個“空”提示,只包含實體詞(和一個序列開始符號)。然後,作者包括了一個詢問模型回憶相關事實的提示,例如“<地點>的經緯度是多少”或“<作者>的<書籍>發佈於何時”。對於美國和紐約市數據集,作者還包括了詢問這個地點在美國或紐約市哪裏的提示,試圖消除一些地點名稱的歧義(例如City Hall)。
作爲基準的模型,作者囊括了10個隨機提示詞作爲提示。爲了確定是否可以模糊主題,對於一些數據集,作者將所有實體名稱全部大寫。最後,對於標題數據集,作者嘗試在最後一個詞和在標題後面加上句號兩種情況下進行測試。研究人員發現,顯式地提示模型信息,或者給出消除歧義的提示,對Llama-2的輸出結果幾乎沒有影響。然而,作者驚訝地發現隨機干擾詞和將實體大寫會降低其輸出內容的質量。唯一明顯改善性能的修改是在標題後面加上句號進行探測,這表明句號被用來包含句子結束。
圖片來源:arXiv
Wes Gurnee和Max Tegmark在論文的“討論”章節指出,他們提供的證據表明,LLMs學習的空間和時間線性表徵在不同實體類型之間是統一的,並且對提示詞具有相當敏感的反應,而且存在對這些特徵高度敏感的單個神經元。由此推論,在模型和數據量足夠大的情況下,LLMs僅靠下一個標記的預測就足以學習世界的文字地圖。
“我們的分析爲今後的工作提出了許多有趣的問題。雖然我們表明可以線性地重建樣本在空間或時間中的絕對位置,而且一些神經元使用了這些探測方向,但空間和時間表徵的真正範圍和結構仍不清楚。特別是,我們推測這種結構的最典型形式是離散化的分層網狀結構,其中任何樣本都被表示爲其最近基點的線性組合。此外,LLMs可以也確實在使用這種座標系,以線性探針(linear probe)的方式使用正確的基點方向線性組合來表示絕對位置。我們預計,隨着LLMs規模的擴大,這一座標系將通過更多的基點、更多的粒度以及更精確的實體到模型座標的映射而得到增強。”研究人員寫道。

Wes Gurnee和Max Tegmark的論文標題 圖片來源:arXiv
作者還指出,在他們的分析以及更廣泛的研究中,另一個干擾因素是他們的數據集中存在許多模型本身並不知道的“實體”,從而“污染”了他們的激活數據集。
“我們對這些瞭解空間和時間維度的世界模型是如何學習或使用的理解也僅僅觸及了其表面。在初步的實驗中,我們發現我們的模型在不依賴多步推理的情況下難以回答基本的時空關係問題,這使得因果乾預分析變得複雜,但我們認爲這是理解何時以及如何使用這些特徵的關鍵步驟。”論文作者補充道。
封面圖片來源:視覺中國-VCG111421248465
